mirror of https://github.com/bmaltais/kohya_ss
1727 lines
118 KiB
Markdown
1727 lines
118 KiB
Markdown
[ 読者になる ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://blog.hatena.ne.jp/hoshikat/hoshikat.hatenablog.com/subscribe?utm_medium%3Dbutton%26utm_source%3Dblogs_topright_button%26utm_campaign%3Dsubscribe_blog)
|
||
|
||
# [人工知能と親しくなるブログ](https://hoshikat-hatenablog-
|
||
com.translate.goog/?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
## 人工知能に関するトピックを取り上げるブログです
|
||
|
||
[ 2023-05-26 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/05/26?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
# [誰でもわかるStable Diffusion Kohya_ssを使ったLoRA学習設定を徹底解説](https://hoshikat-
|
||
hatenablog-
|
||
com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
前回の記事では、Stable Diffusionモデルを追加学習するためのWebUI環境「kohya_ss」の導入法について解説しました。
|
||
|
||
今回は、LoRAのしくみを大まかに説明し、その後にkohya_ssを使ったLoRA学習設定について解説していきます。
|
||
|
||
※今回の記事は非常に長いです!
|
||
|
||
|
||
|
||
**この記事では「各設定の意味」のみ解説しています。**
|
||
|
||
「学習画像の用意のしかた」とか「画像にどうキャプションをつけるか」とか「どう学習を実行するか」は解説していません。学習の実行法についてはまた別の記事で解説したいと思います。
|
||
|
||
|
||
|
||
* [LoRAの仕組みを知ろう](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRAの仕組みを知ろう)
|
||
* [「モデル」とは](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#モデルとは)
|
||
* [LoRAは小さいニューラルネットを追加する](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRAは小さいニューラルネットを追加する)
|
||
* [小さいニューラルネットの構造](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#小さいニューラルネットの構造)
|
||
* [LoRA学習対象1:U-Net](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRA学習対象1U-Net)
|
||
* [RoLA学習対象2:テキストエンコーダー](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#RoLA学習対象2テキストエンコーダー)
|
||
* [kohya_ssを立ち上げてみよう](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#kohya_ssを立ち上げてみよう)
|
||
* [LoRA学習の各設定](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRA学習の各設定)
|
||
* [LoRA設定のセーブ、ロード](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRA設定のセーブロード)
|
||
* [Source modelタブ: 学習に使うベースモデルの設定](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Source-modelタブ学習に使うベースモデルの設定)
|
||
* [Pretrained model name or path](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Pretrained-model-name-or-path)
|
||
* [Model Quick Pick](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Model-Quick-Pick)
|
||
* [Save trained model as](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-trained-model-as)
|
||
* [v2](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#v2)
|
||
* [v_parameterization](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#v_parameterization)
|
||
* [Foldersタブ: 学習画像の場所とLoRA出力先の設定](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Foldersタブ学習画像の場所とLoRA出力先の設定)
|
||
* [Image folder](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Image-folder)
|
||
* [Output folder](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Output-folder)
|
||
* [Regularisation folder](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Regularisation-folder)
|
||
* [Logging folder](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Logging-folder)
|
||
* [Model output name](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Model-output-name)
|
||
* [Training comment](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Training-comment)
|
||
* [Training parametersタブ: 学習の詳細設定](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Training-parametersタブ学習の詳細設定)
|
||
* [LoRA type](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRA-type)
|
||
* [LoRA network weights](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LoRA-network-weights)
|
||
* [DIM from weights](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#DIM-from-weights)
|
||
* [Train batch size](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Train-batch-size)
|
||
* [Epoch](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Epoch)
|
||
* [Save every N epochs](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-every-N-epochs)
|
||
* [Caption Extension](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Caption-Extension)
|
||
* [Mixed precision](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Mixed-precision)
|
||
* [Save precision](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-precision)
|
||
* [Number of CPU threads per core](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Number-of-CPU-threads-per-core)
|
||
* [Seed](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Seed)
|
||
* [Cache latents](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Cache-latents)
|
||
* [Cache latents to disk](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Cache-latents-to-disk)
|
||
* [Learning rate:](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Learning-rate)
|
||
* [LR Scheduler:](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LR-Scheduler)
|
||
* [LR warmup](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LR-warmup)
|
||
* [Optimizer](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Optimizer)
|
||
* [Optimizer extra arguments](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Optimizer-extra-arguments)
|
||
* [Text Encoder learning rate](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Text-Encoder-learning-rate)
|
||
* [Unet learning rate](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Unet-learning-rate)
|
||
* [Network Rank(Dimension)](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Network-RankDimension)
|
||
* [Network alpha:](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Network-alpha)
|
||
* [Max resolution](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Max-resolution)
|
||
* [Stop text encoder training](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Stop-text-encoder-training)
|
||
* [Enable buckets](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Enable-buckets)
|
||
* [Advanced Configuration](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Advanced-Configuration)
|
||
* [Weights、Blocks、Conv](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#WeightsBlocksConv)
|
||
* [Weights: Down LR weights/Mid LR weights/Up LR weights](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Weights-Down-LR-weightsMid-LR-weightsUp-LR-weights)
|
||
* [Weights: Blocks LR zero threshold](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Weights-Blocks-LR-zero-threshold)
|
||
* [Blocks: Block dims, Block alphas](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Blocks-Block-dims-Block-alphas)
|
||
* [Conv: Conv dims, Conv, alphas](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Conv-Conv-dims-Conv-alphas)
|
||
* [No token padding](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#No-token-padding)
|
||
* [Gradient accumulation steps](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Gradient-accumulation-steps)
|
||
* [Weighted captions](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Weighted-captions)
|
||
* [Prior loss weight](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Prior-loss-weight)
|
||
* [LR number of cycles](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LR-number-of-cycles)
|
||
* [LR power](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#LR-power)
|
||
* [Additional parameters](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Additional-parameters)
|
||
* [Save every N steps](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-every-N-steps)
|
||
* [Save last N steps](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-last-N-steps)
|
||
* [Keep n tokens](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Keep-n-tokens)
|
||
* [Clip skip](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Clip-skip)
|
||
* [Max Token Length](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Max-Token-Length)
|
||
* [Full fp16 training (experimental)](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Full-fp16-training-experimental)
|
||
* [Gradient checkpointing](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Gradient-checkpointing)
|
||
* [Shuffle caption](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Shuffle-caption)
|
||
* [Persistent data loader](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Persistent-data-loader)
|
||
* [Memory efficient attention](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Memory-efficient-attention)
|
||
* [Use xformers](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Use-xformers)
|
||
* [Color augmentation](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Color-augmentation)
|
||
* [Flip augmentation](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Flip-augmentation)
|
||
* [Min SNR gamma](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Min-SNR-gamma)
|
||
* [Don't upscale bucket resolution](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Dont-upscale-bucket-resolution)
|
||
* [Bucket resolution steps](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Bucket-resolution-steps)
|
||
* [Random crop instead of center crop](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Random-crop-instead-of-center-crop)
|
||
* [Noise offset type](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Noise-offset-type)
|
||
* [Noise offset](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Noise-offset)
|
||
* [Adaptive noise scale](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Adaptive-noise-scale)
|
||
* [Multires noise iterations](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Multires-noise-iterations)
|
||
* [Multires noise discount](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Multires-noise-discount)
|
||
* [Dropout caption every n epochs](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Dropout-caption-every-n-epochs)
|
||
* [Rate of caption dropout](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Rate-of-caption-dropout)
|
||
* [VAE batch size](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#VAE-batch-size)
|
||
* [Save training state](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Save-training-state)
|
||
* [Resume from saved training state](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Resume-from-saved-training-state)
|
||
* [Max train epoch](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Max-train-epoch)
|
||
* [Max num workers for DataLoader](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Max-num-workers-for-DataLoader)
|
||
* [WANDB API Key](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#WANDB-API-Key)
|
||
* [WANDB Logging](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#WANDB-Logging)
|
||
* [Sample images config](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Sample-images-config)
|
||
* [Sample every n steps](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Sample-every-n-steps)
|
||
* [Sample every n epochs](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Sample-every-n-epochs)
|
||
* [Sample sampler](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Sample-sampler)
|
||
* [Sample prompts](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#Sample-prompts)
|
||
* [まとめ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp#まとめ)
|
||
|
||
|
||
|
||
### LoRAの仕組みを知ろう
|
||
|
||
kohya_ssの各設定の意味を知るには、LoRAがどういうメ[カニ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AB%25A5%25CB)ズムで追加学習をするのか知っておく必要があります。
|
||
|
||
追加学習の対象である「モデル」とは何なのかも合わせて説明します。
|
||
|
||
|
||
|
||
#### 「モデル」とは
|
||
|
||
Stable Diffusionは「 **モデル** 」と呼ばれるモジュールを読み込んで使います。モデルとはいわば「脳みそ」で、その正体は「
|
||
**[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のウェイト情報**」です。
|
||
|
||
[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)はたくさんの「
|
||
**[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)**
|
||
」からできていて、[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)のまとまりが何層もの「
|
||
**レイヤー**
|
||
」を形作っています。あるレイヤーの[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)は違うレイヤーの[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)と線でつながっていて、そのつながりの強さを表すのが「
|
||
**ウェイト** 」です。膨大な絵の情報を保持しているのは、この「ウェイト」なのです。
|
||
|
||
|
||
|
||
####
|
||
LoRAは小さい[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加する
|
||
|
||
LoRAは「追加学習」の一種ですが、追加学習とは[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)をバージョンアップすることです。
|
||
|
||
その方法はいろいろありますが、まず思いつくのは下の図のようにモデル全部を学習しなおす方法です。
|
||
|
||
|
||
|
||

|
||
|
||
追加学習でモデルを鍛えなおす
|
||
|
||
「DreamBooth」という追加学習法がこの方法を使っています。
|
||
|
||
この方法だと、もし追加学習データを公開したい場合、追加学習で新しくなったモデルを丸ごと配布する必要があります。
|
||
|
||
モデルのサイズは通常2G~5Gバイトあり、配布はなかなか大変です。
|
||
|
||
これに対して、LoRA学習ではモデルには手を付けず、新しい「小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)」を学習したい位置ごとに作ります。追加学習は、この小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を対象にして行われます。
|
||
|
||
LoRAを配布したいときはこの小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)だけを配布すればいいので、データサイズが少なく済みます。
|
||
|
||
|
||
|
||

|
||
|
||
RoLA学習は小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)対象
|
||
|
||
|
||
|
||
#### 小さい[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)の構造
|
||
|
||
LoRAの小さい[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)は3つの層からできています。左の「入力層」、右の「出力層」の[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)の数は、ターゲットの[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)の「入力層」「出力層」の[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)数と同じです。真ん中の層(中間層)の[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)数は「ランク数」(または次元数)と呼ばれ、この数は学習するときに自由に決めることができます。
|
||
|
||

|
||
|
||
小さな[ニューラルネットワーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8%25A5%25EF%25A1%25BC%25A5%25AF)の構造
|
||
|
||
|
||
|
||
では、この小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)はどこに追加されるのでしょう?
|
||
|
||
|
||
|
||
#### LoRA学習対象1:U-Net
|
||
|
||
下の図はStable
|
||
Diffusionの心臓部である「U-Net」というメ[カニ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AB%25A5%25CB)ズムです。
|
||
|
||
U-Netは「Down」(左半分)「Mid」(一番下)「Up」(右半分)に分けられます。
|
||
|
||
そして、Down12ブロック、Mid1ブロック、Up12ブロックの合計25ブロックからできています。
|
||
|
||
ここの中の赤い矢印の部分(オレンジ色のブロック)がLoRA学習対象です。つまり、この赤い矢印のブロックに小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)が追加されます。
|
||
|
||

|
||
|
||
赤い矢印のブロックがLoRA学習対象の「Attentionブロック」
|
||
|
||
|
||
|
||
オレンジ色のブロックでは「テキスト処理」、つまりプロンプトとして与えられたテキストを画像に反映させる処理を行っています。
|
||
|
||
このブロックをさらに細かく見ると、以下のような処理を行っています。
|
||
|
||

|
||
|
||
赤い矢印の部分にそれぞれ小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)が追加される
|
||
|
||
ここにも赤い矢印がいくつもついていますが、この赤い矢印の処理全部にそれぞれ別の[ニューラルネットワーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8%25A5%25EF%25A1%25BC%25A5%25AF)が追加されます。
|
||
|
||
ここに追加される[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のことをKohya_ssでは単純に「UNet」と呼んでいます。
|
||
|
||
|
||
|
||
####
|
||
RoLA学習対象2:テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)
|
||
|
||
LoRAが[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加するのはここだけではありません。
|
||
|
||
上の図の「Cross
|
||
Attention」というブロックは、「テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)」というモジュールからテキスト情報を受け取ります。この「テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)」は、テキストデータであるプロンプトを数字の列(ベクトル)に変換するという役割があります。
|
||
|
||
テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)は1つしかなく、U-Net内のすべてのAttentionブロックで共通で使われます。このテキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)は本来Stable
|
||
Diffusion内では「完成品」として扱われ、モデル学習の対象にはなりませんが、LoRAによる追加学習ではこれも学習対象です。
|
||
|
||
LoRAでアップデートしたテキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)はすべてのAttentionブロックで使われるので、ここに追加される[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)は完成画像にとても大きな影響を及ぼします。
|
||
|
||
ここに追加される[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)の事をKohya_ssでは「Text
|
||
Encoder」と呼んでいます。
|
||
|
||
|
||
|
||
### kohya_ssを立ち上げてみよう
|
||
|
||
LoRA学習のしくみを見たので、いよいよkohya_ssを使ってみましょう。
|
||
|
||
kohya_ssフォルダ内にある「[gui](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/gui).bat」をダブルクリックすると、[コマンドプロンプト](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25B3%25A5%25DE%25A5%25F3%25A5%25C9%25A5%25D7%25A5%25ED%25A5%25F3%25A5%25D7%25A5%25C8)(黒背景の文字だけのウィンドウ)が立ち上がります。しばらくするとそこにURLが表示されるので、それをウェブブラウザのURL欄に入力してリターンを押すとkohya_ssの画面がブラウザ上に表示されます。
|
||
|
||
|
||
|
||
kohya_ssを立ち上げると、UIの上部にタブがいくつか現れます。この中の「Dreambooth
|
||
LoRA」を選びましょう。これがLoRA学習のためのタブです。
|
||
|
||

|
||
|
||
左から2番目のタブがLoRA学習設定
|
||
|
||
|
||
|
||
### LoRA学習の各設定
|
||
|
||
「Dreambooth LoRA」タブを選ぶと、たくさんの設定が出てきます。それらをここで解説します。
|
||
|
||
|
||
|
||
#### LoRA設定のセーブ、ロード
|
||
|
||
一番上にあるのは「コンフィグファイル」です。ここでLoRA設定をコンフィグファイルとしてセーブ、ロードすることができます。
|
||
|
||

|
||
|
||
設定はコンフィグファイルとしてセーブ、ロードできる
|
||
|
||
設定をコンフィグファイルに保存しておけば後でそのコンフィグファイルをロードして設定を復元できるので、お気に入りの設定はなるべく保存しておきましょう。
|
||
|
||
|
||
|
||
|
||
|
||
次に、4つのタブがあります。最初の3つについてそれぞれ詳しく見ていきます。
|
||
|
||
(「Tools」タブはLoRA学習時には使わないので説明は省略します。)
|
||
|
||

|
||
|
||
モデル選択、学習画像フォルダ、詳細設定、ツールの各タブ
|
||
|
||
|
||
|
||
#### Source modelタブ: 学習に使うベースモデルの設定
|
||
|
||
|
||
|
||
##### Pretrained model name or path
|
||
|
||
ここにベースモデルの場所を指定します。最初に説明した通り、LoRAは既存のモデルに小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加します。つまり、LoRA学習とは「ベースモデル+α」の「+α」の部分を作る作業です。
|
||
|
||
LoRA学習はベースモデルの特徴に大きな影響を受けるので、
|
||
|
||
* 学習する画像と相性のいいベースモデル
|
||
* 画像生成時に使う(と想定される)モデルと相性のいいベースモデル
|
||
|
||
を選ぶ必要があります。例えば学習画像が実写のような画像なら、実写生成が得意なモデルを選ぶといいでしょう。学習画像が2次元調でも実写調の画像生成を想定しているなら、2次元調と3次元調の混合モデルを選ぶべきかもしれません。
|
||
|
||
なお、学習後にできたLoRAファイルは「追加された[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)」のデータのみで、ベースモデルのデータは入っていません。そのため、完成したLoRAファイルを使って画像を生成するときは、ここで指定したベースモデルだけでなく、どんなモデルとも一緒に使うことができます。
|
||
|
||
|
||
|
||
##### Model Quick Pick
|
||
|
||
ここでモデルを選ぶと、学習実行時にそのモデルが自動的にネット経由でダウンロードされ、ベースモデルとして使用されます。Pretrained model
|
||
name or pathの指定は無視されます。
|
||
|
||
もしモデルがPCに保存されていない場合や、どのモデルを使っていいのか分からない場合は、ここで選択できるモデルを選んで使いましょう。
|
||
|
||
「runwayml/stable-diffusion-v1-5」が使われることが多いようです。
|
||
|
||
自分で用意したモデルを使いたい場合はcustomにしましょう。
|
||
|
||
|
||
|
||
##### Save trained model as
|
||
|
||
学習済みのLoRAファイルをどのファイル形式で保存するかを指定できます。
|
||
|
||
ckptはかつてStable
|
||
Diffusionで使われていた主流の形式でしたが、この形式にはセキュリティ上問題があったため、safetensorsというより安全なファイル形式が生まれました。現在ではsafetensorsが主流となっています。
|
||
|
||
特別な理由がない限りsafetensorsを選びましょう。
|
||
|
||
|
||
|
||
##### v2
|
||
|
||
Stable
|
||
Diffusionのモデルは「バージョン1系」と「バージョン2系」の2つのバージョンがあり、これらはデータ構造がそれぞれ違います。バージョン2系は(2023年5月時点で)まだ普及しておらず、ほとんどの有名モデルは「バージョン1系」です。
|
||
|
||
しかし、「バージョン2系」のモデルをベースモデルとして使う場合はこのオプションをオンにしましょう。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### v_parameterization
|
||
|
||
v-parameterizationとは「バージョン2系」モデルで導入された手法で、従来よりも少ないサンプリングステップで安定して画像を生成するためのトリックです。
|
||
|
||
「バージョン1系」のモデルを使用するときはこのオプションはオフで構いませんが、お使いのベースモデルがv-
|
||
parameterizationを導入していることが分かっている場合はここをオンにしてください。これをオンにするときは必ずv2もオンにしましょう。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
#### Foldersタブ: 学習画像の場所とLoRA出力先の設定
|
||
|
||
##### Image folder
|
||
|
||
学習画像を含むフォルダ(「10_cat」のような名前のフォルダ)がある場所を指定します。
|
||
|
||
「画像がある場所」ではありません!「画像を含むフォルダがある場所」を指定しましょう。
|
||
|
||
|
||
|
||
##### Output folder
|
||
|
||
完成後のLoRAファイルの出力先を指定します。学習の途中経過のLoRAを出力する場合(後述)も、ここで指定した出力先に出力されます。
|
||
|
||
|
||
|
||
##### Regularisation folder
|
||
|
||
LoRA学習では、学習画像の特徴が意図しない単語に強く結びつきすぎてしまい、その単語を入れるたびに学習画像に似た画像しか生成しなくなる、ということがしばしば起こります。
|
||
|
||
そこで「[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像」という「学習画像っぽくない」画像を一緒に学習させることで、特定の単語に学習対象が強く結びついてしまうのを防ぐことができます。
|
||
|
||
[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像の使用は必須ではありませんが、もし[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像を学習に使う場合は、ここで[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像を含んだフォルダの場所を指定します。
|
||
|
||
|
||
|
||
##### Logging folder
|
||
|
||
学習時の処理をログとして出力して保存したい場合、その場所を指定します。
|
||
|
||
ここで指定した名前のフォルダが作業フォルダ内に作成され、さらにその中に学習日時を表す名前のフォルダができます。ログはそこに保存されます。
|
||
|
||
なお、ログファイルは「tensorboard」というツールまたは「WandB」というオンラインサービス(後述)でグラフ化できます。
|
||
|
||
|
||
|
||
##### Model output name
|
||
|
||
完成したLoRAファイルの名前をここで指定します。拡張子をつける必要はありません。
|
||
|
||
「〇〇_ver1.0」(〇〇は学習対象の名前)のようにバージョン番号付きの名前にすると分かりやすいでしょう。
|
||
|
||
なお、名前には日本語を使わないようにしましょう。
|
||
|
||
|
||
|
||
##### Training comment
|
||
|
||
完成したLoRAファイルには「[メタデータ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25E1%25A5%25BF%25A5%25C7%25A1%25BC%25A5%25BF)」としてテキストを埋め込むことができます。もし埋め込みたいテキストがある場合はここに記述します。
|
||
|
||
なお、[メタデータ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25E1%25A5%25BF%25A5%25C7%25A1%25BC%25A5%25BF)はStable
|
||
Diffusion WebUIのLoRA選択画面でⓘマークをクリックすると見ることができます。
|
||
|
||
|
||
|
||
#### Training parametersタブ: 学習の詳細設定
|
||
|
||
このタブではLoRA学習のためのほぼすべてのパラメータを設定します。
|
||
|
||
|
||
|
||
##### LoRA type
|
||
|
||

|
||
|
||
LoRA学習のタイプを指定します。上で解説したLoRAは「スタンダード」タイプです。「DyLoRA」は指定したRank以下の複数のランクを同時に学習するので、最適なランクを選びたいときに便利です。LoHaは高効率なLoRA、LoConは学習をU-
|
||
NetのResブロックまで広げたものです。
|
||
|
||
最初はStandardタイプで問題ありません。学習がうまくいかないときはほかのタイプを選んでみましょう。
|
||
|
||
|
||
|
||
##### LoRA network weights
|
||
|
||
既に学習済みのLoRAファイルを使ってさらに追加学習をしたいときは、ここでLoRAファイルを指定します。
|
||
|
||
ここで指定したLoRAは学習開始時に読み込まれ、このLoRAの状態から学習がスタートします。学習後のLoRAはまた別のファイルとして保存されるので、ここで指定したLoRAファイルが上書きされることはありません。
|
||
|
||
|
||
|
||
##### DIM from weights
|
||
|
||
これはLoRA network weightsで追加学習を行うとき限定のオプションです。
|
||
|
||
上の図にある通り、LoRAは小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加しますが、その中間層の[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)数(ランク数)はNetwork
|
||
Rank(後述)で自由に設定することができます。
|
||
|
||
しかし、このオプションをオンにすると、作成するLoRAのランク数がLoRA network
|
||
weightsで指定したLoRAと同じランク数に設定されます。ここをオンにしたときはNetwork Rankの指定は無視されます。
|
||
|
||
例えば追加学習に使うLoRAのランク数が32の時、作成するLoRAのランク数も32に設定されます。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Train batch size
|
||
|
||
バッチサイズを指定します。バッチとは「いっぺんに読み込む画像の枚数」です。バッチサイズ2なら、一度に2枚の画像を同時に学習します。違う絵を複数同時に学習すると個々の絵に対するチューニング精度は落ちますが、複数の絵の特徴を包括的にとらえる学習になるので、最終的な仕上がりはかえって良くなる可能性があります。
|
||
|
||
(特定の絵にチューニングしすぎると応用の利かないLoRAになってしまいます。)
|
||
|
||
複数の絵を一度に学習するのでバッチサイズを上げれば上げるほど学習時間が短くなりますが、チューニング精度が下がるうえウェイト変更数も減るので、場合によっては学習不足になる可能性があります。
|
||
|
||
(バッチサイズを上げるときは学習率(Learning
|
||
rate、後述します)も上げた方がいいという報告もあります。例えばバッチサイズ2なら学習率を2倍にする、といった感じです。)
|
||
|
||
また、バッチサイズを上げるほどメモリを多く消費します。お使いのPCのVRAMのサイズに合わせて決めましょう。
|
||
|
||
VRAMが6GBあればバッチサイズ2もかろうじて可能でしょう。
|
||
|
||
デフォルトは1です。
|
||
|
||
※バッチごとに同時に読み込む画像はすべて同じサイズでなければならないので、学習画像のサイズがバラバラだと、ここで指定したバッチ数よりも少ない枚数しか同時処理しないことあります。
|
||
|
||
|
||
|
||
##### Epoch
|
||
|
||
1エポックは「1セットの学習」です。
|
||
|
||
例えば50枚の画像をそれぞれ10回ずつ読み込んで学習したいとします。この場合、1エポックは50x10=500回の学習です。2エポックならこれを2回繰り返すので、500x2=1000回の学習になります。
|
||
|
||
指定されたエポック数の学習が終わった後に、LoRAファイルが作成され、指定の場所に保存されます。
|
||
|
||
LoRAの場合、2~3エポックの学習でも十分効果を得られます。
|
||
|
||
|
||
|
||
##### Save every N epochs
|
||
|
||
ここで指定したエポック数ごとに、途中経過をLoRAファイルとして保存することができます。
|
||
|
||
例えば「Epoch」で10と指定し、「Save every N
|
||
epochs」を2に指定すると、2エポックごと(2、4、6、8エポック終了時)に指定フォルダにLoRAファイルが保存されます。
|
||
|
||
途中経過のLoRA作成が不要の場合は、ここの数値を「Epoch」と同じ数値にしましょう。
|
||
|
||
|
||
|
||
##### Caption Extension
|
||
|
||
もし画像ごとにキャプションファイルを用意している場合、そのキャプションファイルの拡張子をここで指定します。
|
||
|
||
ここが空欄の場合、拡張子は「.caption」になります。もしキャプションファイルの拡張子が「.txt」の時は、ここに「.txt」と指定しておきましょう。
|
||
|
||
キャプションファイルがない場合は、無視してかまいません。
|
||
|
||
|
||
|
||
##### Mixed precision
|
||
|
||

|
||
|
||
学習時のウェイトデータの混合精度のタイプを指定します。
|
||
|
||
本来ウェイトデータは32ビット単位(no選択の場合)ですが、必要に応じて16ビット単位のデータも混ぜて学習するとかなりのメモリ節約、スピードアップにつながります。fp16は精度を半分にした[データ形式](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C7%25A1%25BC%25A5%25BF%25B7%25C1%25BC%25B0)、bf16は32ビットデータと同じ数値の幅を取り扱えるよう工夫した[データ形式](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C7%25A1%25BC%25A5%25BF%25B7%25C1%25BC%25B0)です。
|
||
|
||
fp16で十分精度の高いLoRAを得られます。
|
||
|
||
|
||
|
||
##### Save precision
|
||
|
||

|
||
|
||
LoRAファイルに保存するウェイトデータのタイプを指定します。
|
||
|
||
floatは32ビット、fp16とbf16は16ビット単位です。下の二つの方がファイルサイズが小さくなります。
|
||
|
||
デフォルトはfp16です。
|
||
|
||
|
||
|
||
##### Number of CPU threads per core
|
||
|
||
学習時のCPUコアごとのスレッドの数です。基本的に数値が大きいほど効率が上がりますが、スペックに応じて設定を調節する必要があります。
|
||
|
||
デフォルトは2です。
|
||
|
||
|
||
|
||
##### Seed
|
||
|
||
学習時には「どういう順番で画像を読み込むか」や「学習画像にノイズをどれくらい乗せるか(詳細は省略)」など、ランダムな処理がいくつもあります。
|
||
|
||
Seedはそのランダム処理の手順を決めるためのIDのようなもので、同じSeedを指定すれば毎回同じランダム手順が使われるので学習結果を再現しやすくなります。
|
||
|
||
ただ、このSeedを使わないランダム処理(例えば画像をランダムに切り抜く処理など)もあるので、同じSeedを指定しても必ず同じ学習結果が得られるとは限りません。
|
||
|
||
デフォルトは空欄です。指定しなければ学習実行時にSeedが適当に設定されます。
|
||
|
||
結果をなるべく再現したいなら適当に(1234とか)数字を設定しておいて損はありません。
|
||
|
||
|
||
|
||
##### Cache latents
|
||
|
||
学習画像はVRAMに読み込まれ、U-Netに入る前にLatentという状態に「圧縮」されて小さくなり、この状態でVRAM内で学習されます。通常、画像は読み込まれるたびに毎回「圧縮」されますが、Cache
|
||
latentsにチェックを入れると、「圧縮」済みの画像をメインメモリに保持するよう指定できます。
|
||
|
||
メインメモリに保持するとVRAMのスペース節約になり、スピードも上がりますが、「圧縮」前の画像加工ができなくなるので、flip_aug以外のaugmentation(後述)が使えなくなります。また、画像を毎回ランダムな範囲で切り抜くrandom
|
||
crop(後述)も使えなくなります。
|
||
|
||
デフォルトはオンです。
|
||
|
||
|
||
|
||
##### Cache latents to disk
|
||
|
||
Cache latentsオプションと似ていますが、ここにチェックを入れると、圧縮画像データを一時ファイルとしてディスクに保存するよう指定できます。
|
||
|
||
kohya_ssを再起動した後もこの一時ファイルを再利用できるので、同じデータで何度もLoRA学習をしたい場合はこのオプションをオンにすると学習効率が上がります。
|
||
|
||
ただし、これをオンにするとflip_aug以外のaugmentationとrandom cropが使えなくなります。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Learning rate:
|
||
|
||
学習率を指定します。「学習」とは、与えられた絵とそっくりな絵を作れるように[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)内の配線の太さ(ウェイト)を変えていくことですが、毎回絵が与えられるごとにゴッソリ配線を変えてしまうと、与えられた絵のみにチューニングしすぎて、他の絵がまったく描けなくなってしまいます。
|
||
|
||
これを避けるため、毎回、与えられた絵をちょっとだけ取り込むように、ちょっとだけウェイトを変えます。この「ちょっとだけ」の量を決めるのが「学習率」(Learning
|
||
rate)です。
|
||
|
||
デフォルト値は0.0001です。
|
||
|
||
|
||
|
||
##### LR Scheduler:
|
||
|
||

|
||
|
||
学習の途中で学習率(Learning rate)を変えることができます。スケジューラーとは「どういうふうに学習率を変えていくかの設定」です。
|
||
|
||
* adafactor:[オプティマ](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AA%25A5%25D7%25A5%25C6%25A5%25A3%25A5%25DE)イザー(後述)をAdafactorに設定する場合はこれを選択する。VRAM節約のため状況に応じて学習率を自動調節しながら学習
|
||
* constant:学習率は最初から最後まで変わらない
|
||
* constant_with_warmup:最初は学習率0から始めてウォームアップ中にLearning rate設定値に向けてだんだん増やし、本学習の時はLearning rate設定値を使う
|
||
* [cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://d.hatena.ne.jp/keyword/cosine):波(コ[サインカーブ](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25B5%25A5%25A4%25A5%25F3%25A5%25AB%25A1%25BC%25A5%25D6))を描きながら学習率をだんだん0に向けて減らす
|
||
* [cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://d.hatena.ne.jp/keyword/cosine)_with_restarts:[cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://d.hatena.ne.jp/keyword/cosine)を何度も繰り返す(LR number of cyclesの説明も見てください)
|
||
* linear:最初はLearning rate設定値で始め、0に向けて一直線に減らす
|
||
* polynomial:挙動はlinearと同じ、減らし方が少し複雑(LR powerの説明も見てください)
|
||
|
||
学習率をLearning rate設定値に固定したいならconstantにしてください。
|
||
|
||
デフォルトは[cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/cosine)です。
|
||
|
||
|
||
|
||
##### LR warmup
|
||
|
||
スケジューラーでconstant_with_warmupを選択した場合、ウォームアップをどれくらいの回数行うかをここで設定します。
|
||
|
||
ここで指定する数値は全体のステップ数のパーセントです。
|
||
|
||
例えば、50枚の画像をバッチサイズ1で10回学習、これを2エポック行うとき、総ステップ数は50x10x2=1000です。もしLR
|
||
warmupを10に設定すると、総ステップ1000のうち最初の10%、つまり100ステップがウォームアップになります。
|
||
|
||
スケジューラーがconstant_with_warmupでないならここは無視して構いません。
|
||
|
||
デフォルトは10です。
|
||
|
||
|
||
|
||
##### Optimizer
|
||
|
||

|
||
|
||
[オプティマ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AA%25A5%25D7%25A5%25C6%25A5%25A3%25A5%25DE)イザーとは「学習中に[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のウェイトをどうアップデートするか」の設定です。賢く学習するためにいろいろな手法が提案されていますが、LoRA学習で最もよく使われるのは「AdamW」(32ビット)または「AdamW8bit」です。AdamW8bitはVRAMの使用量も低く、精度も十分なので迷ったらこれを使いましょう。
|
||
|
||
その他、Adam手法を取り入れつつ学習の進み具合に応じて学習率を適切に調節する「Adafactor」もよく使われるようです(Adafactorを使う場合はLearning
|
||
rate設定は無視されます)。
|
||
|
||
「DAdapt」は学習率を調節する[オプティマ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AA%25A5%25D7%25A5%25C6%25A5%25A3%25A5%25DE)イザー、「Lion」は比較的新しい[オプティマ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AA%25A5%25D7%25A5%25C6%25A5%25A3%25A5%25DE)イザーですがまだ十分検証されていません。「SGDNesterov」は学習精度は良いものの速度が下がるという報告があります。
|
||
|
||
デフォルトはAdamW8bitです。基本的にこのままで問題ありません。
|
||
|
||
|
||
|
||
##### Optimizer extra arguments
|
||
|
||
指定した[オプティマ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25AA%25A5%25D7%25A5%25C6%25A5%25A3%25A5%25DE)イザーに対してさらに細かく設定したい場合は、ここでコマンドを書きます。
|
||
|
||
通常は空欄のままで構いません。
|
||
|
||
|
||
|
||
##### Text Encoder learning rate
|
||
|
||
テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)に対する学習率を設定します。最初のほうで書いた通り、テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)の追加学習の影響はU-
|
||
Net全体に及びます。
|
||
|
||
そのため、通常はU-Netの各ブロックに対する学習率(Unet learning rate)よりも低くしておきます。
|
||
|
||
デフォルト値は0.00005(5e-5)です。
|
||
|
||
ここで数値を指定した場合、Learning rateの値よりもこちらが優先されます。
|
||
|
||
|
||
|
||
##### Unet learning rate
|
||
|
||
U-Netに対する学習率を設定します。U-Netの中にある各Attentionブロック(設定によっては他のブロックも)に追加学習を行うときの学習率です。
|
||
|
||
デフォルト値は0.0001です。
|
||
|
||
ここで数値を指定した場合、Learning rateの値よりもこちらが優先されます。
|
||
|
||
|
||
|
||
##### Network Rank(Dimension)
|
||
|
||
記事の上の方で説明した「追加する小さな[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)」の中間層の[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)の数を指定します(詳細は上の図を見てください)。
|
||
|
||
[ニューロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25ED%25A5%25F3)の数が多いほど学習情報を多く保持できますが、学習対象以外の余計な情報まで学習してしまう可能性が高くなり、LoRAのファイルサイズも大きくなります。
|
||
|
||
一般的に最大128程度で設定することが多いですが、32で十分という報告もあります。
|
||
|
||
試験的にLoRAを作る場合は2~8あたりから始めるのがいいかもしれません。
|
||
|
||
デフォルトは8です。
|
||
|
||
|
||
|
||
##### Network alpha:
|
||
|
||
これは、LoRA保存時にウェイトが0に丸め込まれてしまうのを防ぐための便宜上の処置として導入されたものです。
|
||
|
||
LoRAはその構造上、[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のウェイト値が小さくなりがちで、小さくなりすぎるとゼロ(つまりなにも学習していないのと同じ)と見分けがつかなくなってしまう恐れがあります。そこで、実際の(保存される)ウェイト値は大きく保ちつつ、学習時には常にウェイトを一定の割合で弱めてウェイト値を小さく見せかける、というテクニックが提案されました。この「ウェイトを弱める割合」を決めるのがNetwork
|
||
alphaです。
|
||
|
||
**Network
|
||
alpha値が小さければ小さいほど、保存されるLoRAの[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のウェイト値が大きくなります。**
|
||
|
||
|
||
|
||
使用時にウェイトがどれだけ弱まるか(使用強度)は「Network_Alpha/Network_Rank」で計算され(ほぼ0~1の値)、Network
|
||
Rank数と深く関係しています。
|
||
|
||
学習後のLoRAの精度がいまいちな場合、ウェイトデータが小さすぎて0に潰れてしまっている可能性があります。そんな時はNetwork
|
||
Alpha値を下げてみる(=保存ウェイト値を大きくする)とよいでしょう。
|
||
|
||
デフォルトは1(つまり保存ウェイト値をなるべく最大にする)です。
|
||
|
||
Network AlphaとNetwork Rankが同じ値の場合、効果はオフになります。
|
||
|
||
※Network Alpha値がNetwork Rank値を超えてはいけません。超える数字を指定することは可能ですが、高確率で意図しないLoRAになります。
|
||
|
||
また、Network Alphaを設定するときは、学習率への影響を考える必要があります。
|
||
|
||
例えばAlphaが16、Rankが32の場合、ウェイトの使用強度は16/32 = 0.5になり、つまり学習率が「Learning
|
||
Rate」設定値のさらに半分の効力しか持たないことになります。
|
||
|
||
AlphaとRankが同じ数字であれば使用強度は1になり、学習率に何の影響も与えません。
|
||
|
||
|
||
|
||
##### Max resolution
|
||
|
||
学習画像の最大解像度を「幅、高さ」の順で指定します。もし学習画像がここで指定した解像度を超える場合、この解像度まで縮小されます。
|
||
|
||
デフォルトは「512,512」です。多くのモデルがこのサイズの画像を使っているので、LoRA学習の時もこのサイズの画像を使うのが無難です。
|
||
|
||
|
||
|
||
##### Stop text encoder training
|
||
|
||
テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)の学習は途中でストップすることができます。上で書いた通り、テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)のアップデートは全体に大きな影響を及ぼすので[過学習](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25B2%25E1%25B3%25D8%25BD%25AC)(学習画像にチューニングしすぎて他の画像が描けなくなる)に陥りやすく、ほどほどのところで学習をストップさせるのも[過学習](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25B2%25E1%25B3%25D8%25BD%25AC)を防ぐ一つの手です。
|
||
|
||
ここで指定した数値は全学習ステップのパーセントです。学習がこのパーセントに達したら、テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)は学習をストップします。
|
||
|
||
例えば、総ステップ数が1000だった場合、ここで80と指定したら、学習進行度が80%の時、つまり1000x0.8=800ステップの時点でテキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)の学習が終了します。
|
||
|
||
U-Netの学習は残り200ステップで引き続き行われます。
|
||
|
||
ここが0の場合、テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)の学習は最後までストップしません。
|
||
|
||
|
||
|
||
##### Enable buckets
|
||
|
||
「[bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/bucket)」とはその名の通り「バケツ」(入れ物)です。LoRAで使う学習画像はサイズが統一されていなくてもかまわないのですが、違うサイズの画像を同時に学習することはできません。そのため、学習前に画像をサイズに応じて「バケツ」に振り分ける必要があります。似たサイズの画像は同じバケツに入れ、違うサイズの画像は別のバケツに入れていきます。
|
||
|
||
デフォルトはオンです。
|
||
|
||
もし学習画像のサイズがすべて同じならこのオプションはオフにして構いませんが、オンのままでも影響はありません。
|
||
|
||
※もし学習画像のサイズが統一されていない時にEnable bucketsをオフにすると、学習画像は拡大、縮小されてサイズが同じ大きさに揃えられます。
|
||
|
||
拡大、縮小は画像の[アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)を保ったまま行われます。[アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)が基準サイズと同じでない場合、拡大縮小後の画像のタテかヨコが基準サイズからはみ出すことがあります。例えば、基準サイズが512x512([アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)1)で、画像サイズが1536x1024([アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)1.5)の場合、画像は縮小されて768x512([アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)1.5のまま)になります。
|
||
|
||
|
||
|
||
#### Advanced Configuration
|
||
|
||
ここより後は、「Advanced Configuration」セクションにあるオプションです。
|
||
|
||
|
||
|
||
##### Weights、Blocks、Conv
|
||
|
||

|
||
|
||
これらはU-Net内の各ブロックの「学習の重み付け」と「ランク」の設定です。それぞれのタブを選択すると、対応する設定画面が表示されます。
|
||
|
||
※これらの設定は上級者向けです。こだわりがないならすべて空欄のままで構いません。
|
||
|
||
|
||
|
||
##### Weights: Down LR weights/Mid LR weights/Up LR weights
|
||
|
||
U-Netの構造図からわかる通り、U-Netは12個のINブロック、1個のMIDブロック、12個のOUTブロックの計25個のブロックからできています。
|
||
|
||
それぞれのブロックの学習率のウェイト(重み)を変えたい場合、ここで個別に設定することができます。
|
||
|
||
ここでいうウェイトとは0~1の数値で表される「学習の強さ」で、0の場合は「まったく学習しない」、1の場合は「Learning
|
||
rateで設定した学習率で学習」という感じで学習の強さを変えることができます。
|
||
|
||
ウェイトを0.5にした場合、Learning rateの半分の学習率になります。
|
||
|
||
「Down LR weights」は12個のINブロックのそれぞれのウェイトを指定します。
|
||
|
||
「Mid LR weights」はMIDブロックのウェイトを指定します。
|
||
|
||
「Up LR weights」は12個のOUTブロックのそれぞれのウェイトを指定します。
|
||
|
||
|
||
|
||
##### Weights: Blocks LR zero threshold
|
||
|
||
「LoRAは[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加する」と説明しましたが、ウェイトが小さすぎる(つまりほとんど学習していない)[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)は追加しても意味がありません。そこで、「ウェイトが小さすぎるブロックには[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)を追加しない」という設定ができます。
|
||
|
||
ここで設定したウェイト値を超えないブロックでは、[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)が追加されません。例えばここに0.1と指定した場合、ウェイトを0.1以下に設定したブロックには[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)が追加されません(排除対象が指定値も含んでいることに注意してください!)。
|
||
|
||
デフォルトは空欄で、空欄の場合は0(何もしない)です。
|
||
|
||
|
||
|
||
##### Blocks: Block dims, Block alphas
|
||
|
||
ここで、IN0~11、MID、OUT0~11の25個の各ブロックに対しそれぞれ違うランク(dim)値とアルファ値を設定することができます。
|
||
|
||
ランク値とアルファ値についてはNetwork Rank、Network alphaの説明を見てください。
|
||
|
||
ランクの大きいブロックはより多くの情報を保持できることが期待されます。
|
||
|
||
このパラメータ値は常に25個の数字を指定しなければいけませんが、LoRAはAttentionブロックを学習対象としているので、Attentionブロックの存在しないIN0、IN3、IN6、IN9、IN10、IN11、OUT0、IN1、IN2に対する設定(1、4、7、11、12、14、15、16番目の数字)は学習時は無視されます。
|
||
|
||
※上級者向け設定です。こだわりがないなら空欄のままで構いません。ここを指定しない場合は「Network Rank(Dimention)」値と「Network
|
||
Alpha」値がすべてのブロックに適応されます。
|
||
|
||
|
||
|
||
##### Conv: Conv dims, Conv, alphas
|
||
|
||
LoRAが学習対象としているAttentionブロックには「Conv」という[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)があり、そこも追加学習によりアップデートされます(記事上部のAttention層の構造の図を見てください)。これは「畳み込み」と言われる処理で、そこで使われている「フィルター」の大きさは1x1マスです。
|
||
|
||
畳み込みについては[この記事](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://github.com/kohya-ss/sd-scripts/pull/121)を読んでください。
|
||
|
||
一方、Attention以外のブロック(Res、Downブロック)やOUTにあるAttentionブロックの一部には、[3x3](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/3x3)マスのフィルターを使った畳み込みを行っている部分もあります。本来そこはLoRAの学習対象ではありませんが、このパラメータで指定することでResブロックの[3x3](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/3x3)の畳み込みも学習対象にすることができます。
|
||
|
||
学習対象が増えるので、より精密なLoRA学習を行える可能性があります。
|
||
|
||
設定方法は「Blocks: Blocks dims, Blocks alphas」と同じです。
|
||
|
||
[3x3](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/3x3)のConvは25層すべてに存在します。
|
||
|
||
※上級者向け設定です。こだわりがないなら空欄のままで構いません。
|
||
|
||
|
||
|
||
##### No token padding
|
||
|
||
学習画像につけるキャプションは、75[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンごとに処理されます(「[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ン」は基本的に「単語」と捉えて問題ありません)。
|
||
|
||
キャプションの長さが75[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ン未満の場合、キャプションの後に終端記号が必要なだけ追加され、75[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンに揃えられます。これを「パディング」と言います。
|
||
|
||
ここでは、[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンのパディングを行わないようにする指定ができます。
|
||
|
||
デフォルトはオフです。基本的にオフのままで構いません。
|
||
|
||
|
||
|
||
##### Gradient accumulation steps
|
||
|
||
ウェイトの変更(つまり「学習」)は通常は1バッチ読み込むごとに行いますが、学習を複数バッチまとめていっぺんに行うこともできます。何バッチまとめていっぺんに学習するかを指定するのがこのオプションです。
|
||
|
||
これはバッチ数を上げる働きと似た効果(「同じ効果」ではありません!)があります。
|
||
|
||
例えば、バッチサイズが4の場合、1バッチで同時に読み込まれる画像数は4枚です。つまり4枚読み込むごとに1回学習が行われます。ここでGradient
|
||
accumulation
|
||
stepsを2にすると、2バッチごとに1回学習が行われるので、結果的に8枚読み込むごとに1回学習が行われることになります。これはバッチ数8と似た働き(同じではありません!)です。
|
||
|
||
この数値を上げると学習回数が減るので処理が速くなりますがメモリを多く消費します。
|
||
|
||
デフォルトは1です。
|
||
|
||
|
||
|
||
##### Weighted captions
|
||
|
||
現在一番人気のStable Diffusion利用環境は「Stable Diffusion
|
||
WebUI」ですが、これには独特のプロンプト記述法があります。例えばプロンプトに「[black
|
||
cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat)」と指定する時に「Black」をものすごく強調したい場合、「(black:1.2)
|
||
cat」という風に強調したいワードをかっこで囲み、ワードの後に「:数字」と入れると、その数字の倍数だけワードが強調されます。
|
||
|
||
この記述法を学習画像のキャプションでも使えるようにするのがこのオプションです。
|
||
|
||
複雑なキャプションを書きたい場合は試してみるのもいいでしょう。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Prior loss weight
|
||
|
||
学習時に「[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像」(詳しくは上のRegularisation
|
||
folderの説明を見てください)をどれだけ重要視するかを決めるのがPrior loss weightです。
|
||
|
||
この値が低いと、[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像はそれほど重要でないと判断され、より学習画像の特徴が強く現れるLoRAが生成されます。
|
||
|
||
[正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像を使わない場合はこの設定は意味がありません。
|
||
|
||
これは0~1の値で、デフォルトは1([正則化](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25C0%25B5%25C2%25A7%25B2%25BD)画像も重視)です。
|
||
|
||
|
||
|
||
##### LR number of cycles
|
||
|
||
スケジューラーに「[Cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Cosine) with
|
||
restart」または「Polynomial」を選んだ場合、学習中にスケジューラー何サイクル実行するかを指定するオプションです。
|
||
|
||
このオプションの数値が2以上の場合、1回の学習中にスケジューラーが複数回実行されます。
|
||
|
||
[Cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Cosine) with
|
||
restartもPolynomialも、学習が進むにつれて学習率が0までだんだん下がっていきますが、サイクル数が2以上の場合、学習率が0に達したら学習率をリセットして再スタートします。
|
||
|
||
下の図[(引用元)](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://github.com/kohya-ss/sd-
|
||
scripts/pull/121)は[Cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Cosine) with
|
||
restart(紫)とPolynomial(薄緑)の学習率の変化の例です。
|
||
|
||
紫の例ではサイクル数が4に設定されています。薄緑の例ではサイクル数は1です。
|
||
|
||
指定されたサイクル数を決められた学習ステップ内で実行するので、サイクル数が増えれば増えるほど、学習率の変化が激しくなります。
|
||
|
||
デフォルトは空欄で、空欄の場合は1になります。
|
||
|
||

|
||
|
||
学習率の動きの例
|
||
[Cosine](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Cosine) with restartで「LR
|
||
number of cycle = 4」 (紫)
|
||
Polynomialで「LR power = 2」 (薄緑)
|
||
|
||
|
||
|
||
##### LR power
|
||
|
||
これはスケジューラーにPolynomialを設定した場合のオプションで、この数が大きければ大きいほど最初の学習率の下がり方が急激になります。(上の図の薄緑の線のスロープが急激になります)。
|
||
|
||
powerが1の時はlinearスケジューラーと同じ形になります。
|
||
|
||
あまり数を大きくしすぎると学習率が0ちかくに張り付いてしまって学習不足に陥るので気をつけましょう。
|
||
|
||
デフォルトは空欄で、空欄の場合は1(つまりlinearスケジューラーと同じ)になります。
|
||
|
||
|
||
|
||
##### Additional parameters
|
||
|
||
kohya_ssの[GUI](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/GUI)に表示されていない学習設定パラメータをいじりたい場合、ここでコマンドとして入力します。
|
||
|
||
通常は空欄のままで構いません。
|
||
|
||
|
||
|
||
##### Save every N steps
|
||
|
||
ここで指定したステップ数の学習が終了するごとに、LoRAファイルが作成され、保存されます。
|
||
|
||
例えば総学習ステップ数が1000の時、ここで200と指定すると、200、400、600、800ステップ終了時にLoRAファイルが保存されます。
|
||
|
||
途中経過のLoRA保存については「Save every N epochs」も参照してください。
|
||
|
||
デフォルトは0(途中経過LoRAを保存しない)です。
|
||
|
||
|
||
|
||
##### Save last N steps
|
||
|
||
学習途中のLoRAを保存するようSave every N stepsで指定した場合のオプションです。
|
||
|
||
もし最近のLoRAファイルのみ保持して古いLoRAファイルは破棄したい場合、ここで「最近何ステップ分のLoRAファイルを保持しておくか」を設定できます。
|
||
|
||
例えば総学習ステップが600の時、Save every N
|
||
stepsオプションで100ステップごとに保存するよう指定したとします。すると100、200、300、400、500ステップ目にLoRAファイルが保存されますが、Save
|
||
every N
|
||
stepsを300と指定した場合、最近300ステップ分のLoRAファイルのみ保持されます。つまり500ステップ目には200(=500-300)ステップ目より古いLoRA(つまり100ステップ目のLoRA)は消去されます。
|
||
|
||
デフォルトは0です。
|
||
|
||
|
||
|
||
##### Keep n tokens
|
||
|
||
学習画像にキャプションがついている場合、そのキャプション内のコンマで区切られた単語をランダムに入れ替えることができます(詳しくはShuffle
|
||
captionオプションを見てください)。しかし、ずっと先頭に置いておきたい単語がある場合は、このオプションで「最初の〇単語は先頭に固定しておいて」と指定できます。
|
||
|
||
ここで指定した数の最初の単語は、いつも先頭に固定されます。
|
||
|
||
デフォルトは0です。Shuffle captionオプションがオフの場合はこのオプションは何もしません。
|
||
|
||
※ここでいう「単語」とは、コンマで区切られたテキストのことです。区切られたテキストがいくつ単語を含んでいようと、それは「1単語」としてカウントされます。
|
||
|
||
「[black cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat), eating,
|
||
sitting」の場合、「[black
|
||
cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat)」で1単語です。
|
||
|
||
|
||
|
||
##### Clip skip
|
||
|
||
テキスト[エンコーダー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A8%25A5%25F3%25A5%25B3%25A1%25BC%25A5%25C0%25A1%25BC)には「CLIP」という仕組みが使われていますが、これは12層の似たようなレイヤーからできています。
|
||
|
||
テキスト([トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ン)は本来、この12層のレイヤーを通って数字の列(ベクトル)に変換され、最後のレイヤーから出てきたベクトルがU-
|
||
NetのAttentionブロックに送られます。
|
||
|
||
しかし、「Novel AI」というサービスが独自に開発したモデル、通称「Novel
|
||
AIモデル」は、最後のレイヤーでなく最後から2番目のレイヤーが出力したベクトルを使う、という独自仕様を採用しました。Novel
|
||
AIモデルから派生したモデルも同様です。そのため、「学習に使うベースモデルがCLIPのどのレイヤーから出てきたベクトルを使っているか」という指定が必要になります。
|
||
|
||
この「最後から〇番目」のレイヤー番号を指定するのが「Clip skip」です。
|
||
|
||
ここを2にすると、最後から2番目のレイヤーの出力ベクトルがAttentionブロックに送られます。1の場合は、最後のレイヤーの出力ベクトルが使われます。
|
||
|
||
ベースモデルにNovel AIモデル(またはそのミックスモデル)が使われている場合は、2にした方がいいでしょう。そのほかの場合は1で構いません。
|
||
|
||
|
||
|
||
##### Max Token Length
|
||
|
||

|
||
|
||
キャプションに含まれる最大の[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンの長さを指定します。
|
||
|
||
ここでいう「[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ン」は単語数ではなく、[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ン数は単語数とだいたい同じ~1.5倍ぐらいの数になります。コンマも1[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンとカウントされることに注意してください。
|
||
|
||
75[トーク](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C8%25A1%25BC%25A5%25AF)ンを超えるキャプションを使うことはめったにないでしょうが、「キャプションの文が長いな」と思ったときは、ここでより大きな数字を指定してください。
|
||
|
||
|
||
|
||
##### Full fp16 training (experimental)
|
||
|
||
上で説明したオプション「Mixed
|
||
precision」をオン(fp16またはbf16)にすると、学習時に32ビットと16ビットのデータが混合して使用されますが、このオプションをオンにするとすべてのウェイトデータが16ビット(fp16形式)に揃えられます。メモリの節約にはなりますが、一部データ精度が半分になるので学習精度も落ちる可能性があります。
|
||
|
||
デフォルトはオフです。よっぽどメモリを節約したいとき以外はオフのままでいいでしょう。
|
||
|
||
|
||
|
||
##### Gradient checkpointing
|
||
|
||
通常の場合、学習中は、画像が読み込まれるごとに膨大な数の[ニューラルネット](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25CB%25A5%25E5%25A1%25BC%25A5%25E9%25A5%25EB%25A5%25CD%25A5%25C3%25A5%25C8)のウェイトを一斉に修正しアップデートします。これを「一斉」でなく「少しずつ」修正することで、計算処理を減らしてメモリを節約できます。
|
||
|
||
このオプションはウェイト計算を少しずつ行うように指定します。ここをオンにしてもオフにしてもLoRAの学習結果に影響はありません。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Shuffle caption
|
||
|
||
学習画像にキャプションがついている場合、キャプションの多くは「[black
|
||
cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat), eating,
|
||
sitting」といった具合にコンマで区切られた単語が並んだ形式で書かれていることが多いでしょう。このコンマで区切られている単語の順番を毎回ランダムに入れ替えるのがShuffle
|
||
captionオプションです。
|
||
|
||
一般的にキャプション内の単語は先頭に近いほど重視されます。そのため、単語の順番が固定されていると後方の単語がうまく学習されなかったり、前方の単語が学習画像と意図しない結びつきをする可能性があります。画像を読み込むごとに毎回単語の順番を入れ替えることで、このかたよりを修正できることが期待されます。
|
||
|
||
キャプションがコンマ区切りでなく文章になっている場合はこのオプションは意味がありません。
|
||
|
||
デフォルトはオフです。
|
||
|
||
※ここでいう「単語」とは、コンマで区切られたテキストのことです。区切られたテキストがいくつ単語を含んでいようと、それは「1単語」としてカウントされます。
|
||
|
||
「[black cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat), eating,
|
||
sitting」の場合、「[black
|
||
cat](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/black%2520cat)」で1単語です。
|
||
|
||
|
||
|
||
##### Persistent data loader
|
||
|
||
学習に必要なデータは1つのエポックが終わるごとに破棄され、再読み込みされます。これを破棄せずに保持しておくためのオプションです。このオプションをオンにすると新しいエポックの学習が始まる速度が上がりますが、データを保持する分メモリを消費します。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Memory efficient attention
|
||
|
||
これにチェックを入れるとVRAMの使用を抑えてAttentionブロックの処理を行います。次のオプションの「xformers」に比べてスピードは遅くなります。VRAMの容量が少ない場合はオンにしましょう。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Use xformers
|
||
|
||
「xformers」という[Python](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Python)ライブラリを使用すると、若干のスピード低下と引き換えにVRAMの使用を抑えてAttentionブロック処理を行います。VRAMの容量が少ない場合はオンにしましょう。
|
||
|
||
デフォルトはオンです。
|
||
|
||
|
||
|
||
##### Color augmentation
|
||
|
||
「augmentation」とは「画像の水増し」を意味します。学習画像を毎回少し加工することにより、学習画像の種類を疑似的に増やします。
|
||
|
||
Color
|
||
augmentationをオンにすると、画像の色相(Hue)を毎回ランダムに少し変化させます。これによって学習したLoRAは色調に若干の幅が出ることが期待されます。
|
||
|
||
Cache latentsオプションがオンの場合は使用できません。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Flip augmentation
|
||
|
||
このオプションをオンにすると、ランダムに画像が左右反転します。左右のアングルを学習できるので、 **左右対称**
|
||
の人物や物体を学習したいときは有益でしょう。
|
||
|
||
デフォルトはオフです。
|
||
|
||
|
||
|
||
##### Min [SNR](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/SNR) gamma
|
||
|
||
LoRA学習では学習画像にいろいろな強さのノイズを乗せて学習します(このあたりの詳細は省略)が、乗っているノイズの強さの違いによって学習目標に近寄ったり離れたりして学習が安定しないことがあり、Min
|
||
[SNR](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/SNR)
|
||
gammaはそれを補正するために導入されました。特にノイズがあまり乗っていない画像を学習するときは目標から大きく離れたりするので、このジャンプを抑えるようにします。
|
||
|
||
詳細はややこしいので省略しますが、この値は0~20で設定でき、デフォルトは0です。
|
||
|
||
この方法を提唱した論文によると最適値は5だそうです。
|
||
|
||
どれほど効果的なのかは不明ですが、学習結果に不満がある時はいろいろな値を試してみるといいでしょう。
|
||
|
||
|
||
|
||
##### Don't upscale
|
||
[bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/bucket) resolution
|
||
|
||
[Bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Bucket)(バケツ)のサイズはデフォルトでは256~1024[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)(またはMax
|
||
resolutionオプションで最大解像度を指定している場合はそちらが優先されます)に設定されています。タテかヨコのどちらか一方でもこのサイズ範囲から外れた画像は、指定範囲内のサイズになるように([アスペクト比](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25A2%25A5%25B9%25A5%25DA%25A5%25AF%25A5%25C8%25C8%25E6)を保ったまま)拡大または縮小されます。
|
||
|
||
しかし、このオプションをオンにするとバケツサイズの範囲設定は無視され、学習画像のサイズに応じて自動的にバケツが用意されるので、すべての学習画像が拡大縮小されずに読み込まれるようになります。ただしこの時も[Bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Bucket) resolution
|
||
steps(後述)にサイズを合わせるため画像の一部が切り取られる可能性はあります。
|
||
|
||
デフォルトはオンです。
|
||
|
||
|
||
|
||
##### [Bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Bucket) resolution steps
|
||
|
||
[Bucket](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Bucket)(バケツ)を使用する場合、各バケツの解像度間隔をここで指定します。
|
||
|
||
例えばここで64を指定した場合、それぞれの学習画像をサイズに応じて64[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)ごとに別のバケツに振り分けます。この振り分けはタテヨコそれぞれに対して行われます。
|
||
|
||
もし画像サイズがバケツの指定するサイズピッタリでない場合、はみ出した部分は切り取られます。
|
||
|
||
例えば、最大解像度が512[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)でバケツのステップサイズが64[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)ごとの場合、バケツは512、448、384…となりますが、500[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)の画像は448[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)のバケツに入れられ、サイズを合わせるため余分な52[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)が切り取られます。
|
||
|
||
デフォルトは64[ピクセル](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D4%25A5%25AF%25A5%25BB%25A5%25EB)です。
|
||
|
||
※この数値をあまり小さくしすぎるとバケツの振り分けが細かくなりすぎてしまい、最悪「画像1枚ごとに1つのバケツ」のような状態になってしまいます。
|
||
|
||
1バッチにつき必ず同じバケツから画像を読み込むので、バケツの中の画像が少なすぎるとバッチ数が意図せず少なくなってしまうことに注意してください。
|
||
|
||
|
||
|
||
##### Random crop instead of center crop
|
||
|
||
上記のように、中途半端なサイズの画像はバケツに振り分けた後に一部が切り取られてサイズが揃えられますが、通常は画像の中心を保つように切り取られます。
|
||
|
||
このオプションをオンにすると、絵のどの部分が切り取られるかがランダムに決まります。学習の範囲を画像の中心以外に広げたいときはこのオプションをオンにします。
|
||
|
||
※cache latentsオプションをオンにしているときはこのオプションは使えません。
|
||
|
||
|
||
|
||
##### Noise offset type
|
||
|
||
学習画像に追加ノイズを乗せるときに、どの手法で乗せるのかを指定するオプションです。学習時には必ず画像にノイズを乗せる(この辺の詳細は省略します)のですが、このノイズは「予測しづらい」ノイズである方がより好ましいため、さらに多くのノイズを乗せることでより「予測しづらい」ノイズにします。
|
||
|
||
デフォルトはOriginalです。Multiresはもう少し複雑な方法でノイズを追加します。
|
||
|
||
|
||
|
||
##### Noise offset
|
||
|
||
Noise offset
|
||
typeに「Original」を選択したときのオプションです。ここで0より大きな値を入れると追加ノイズが乗ります。値は0~1で、0の場合はまったくノイズを追加しません。1の場合は強いノイズを追加します。
|
||
|
||
0.1程度のノイズを追加するとLoRAの色合いが鮮やかになる(明暗がはっきりする)という報告があります。デフォルトは0です。
|
||
|
||
|
||
|
||
##### Adaptive noise scale
|
||
|
||
Noise offsetオプションとペアで使います。ここに数値を指定すると、Noise
|
||
offsetで指定した追加ノイズ量がさらに調整され増幅あるいは減衰します。増幅(または減衰)する量は、「画像に現在どのくらいノイズが乗っているか」によって自動的に調整されます。値は-1~1で、プラスを指定すると追加ノイズ量が増え、マイナスを指定した場合は追加ノイズ量が減ります。
|
||
|
||
デフォルトは0です。
|
||
|
||
|
||
|
||
##### Multires noise iterations
|
||
|
||
Noise offset typeに「Multires」を選択したときのオプションです。ここで0より大きな値を入れると追加ノイズが乗ります。
|
||
|
||
Multiresでは、様々な解像度のノイズを作ってそれらを足すことで最終的な追加ノイズを作成します。ここでは「様々な解像度」をいくつ作るかを指定します。
|
||
|
||
デフォルトは0で、0の時は追加ノイズは乗りません。使用したい場合は6に設定することがが推奨されています。
|
||
|
||
|
||
|
||
##### Multires noise discount
|
||
|
||
Multires noise
|
||
iterationsオプションとペアで使います。各解像度のノイズ量をある程度弱めるための数値です。0~1の値で、数字が小さいほどノイズがより弱まります。ちなみに弱める量は解像度によって違い、解像度の低いノイズはたくさん弱めます。
|
||
|
||
デフォルトは0で、0の場合は使用時に0.3に設定されます。通常は0.8が推奨されています。学習画像が比較的少ない場合は0.3程度に下げると良いようです。
|
||
|
||
|
||
|
||
##### Dropout caption every n epochs
|
||
|
||
通常、画像とキャプションはペアで学習されますが、特定のエポックごとにキャプションを使わず「キャプションなしの画像」のみ学習させることができます。
|
||
|
||
このオプションは「〇エポックごとにキャプションを使わない([ドロップアウト](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C9%25A5%25ED%25A5%25C3%25A5%25D7%25A5%25A2%25A5%25A6%25A5%25C8))」という指定を行えます。
|
||
|
||
例えばここで2を指定すると、2エポックごとに(2エポック目、4エポック目、6エポック目…)キャプションを使わない画像学習を行います。
|
||
|
||
キャプションのない画像を学習すると、そのLoRAはより包括的な画像の特徴を学習することが期待されます。また、特定の単語に画像の特徴を結び付けすぎないようにする効果も期待できます。ただしあまりキャプションを使わなすぎると、そのLoRAはプロンプトの効かないLoRAになってしまう可能性があるので気をつけましょう。
|
||
|
||
デフォルトは0で、0の場合はキャプションの[ドロップアウト](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25C9%25A5%25ED%25A5%25C3%25A5%25D7%25A5%25A2%25A5%25A6%25A5%25C8)を行いません。
|
||
|
||
|
||
|
||
##### Rate of caption dropout
|
||
|
||
上記のDropout caption every n
|
||
epochsと似ていますが、学習の全工程のうち、ある一定の割合だけキャプションを使わず「キャプションなしの画像」として学習させることができます。
|
||
|
||
ここでキャプションなし画像の割合を設定できます。0は「学習中必ずキャプションを使う」設定、1は「学習中キャプションを全く使わない」設定です。
|
||
|
||
どの画像が「キャプションなし画像」として学習されるかはランダムに決まります。
|
||
|
||
例えば、画像20枚をそれぞれ50回読み込むLoRA学習を1エポックだけ行う場合、画像学習の総数は20枚x50回x1エポック=1000回です。この時Rate
|
||
of caption dropoutを0.1に設定すると、1000回x0.1=100回は「キャプションなしの画像」として学習を行います。
|
||
|
||
デフォルトは0で、すべての画像をキャプション付きで学習します。
|
||
|
||
|
||
|
||
##### VAE batch size
|
||
|
||
Cache
|
||
latentsオプションをオンにすると「圧縮」した状態の画像データをメインメモリに保持しておくことができますが、この「圧縮」画像を何枚一組で保持するかを設定するのがVAE
|
||
batch sizeです。バッチサイズ(Batch size)で指定した画像枚数を一度に学習するので、VAE batch
|
||
sizeもこれに合わせるのが普通です。
|
||
|
||
デフォルトは0で、この場合Batch sizeと同じ数値に設定されます。
|
||
|
||
|
||
|
||
##### Save training state
|
||
|
||
学習画像、繰り返し数、エポック数が多いとLoRAの学習に長い時間がかかります。
|
||
|
||
このオプションをオンにすると、学習を途中で中断して後日続きから学習を再開することができます。
|
||
|
||
学習の途中経過データは「last-state」というフォルダに保存されます。
|
||
|
||
|
||
|
||
##### Resume from saved training state
|
||
|
||
中断した学習を再開したい場合、ここに「last-state」フォルダの場所を指定します。
|
||
|
||
学習を再開するには、学習の途中経過データが保存されている必要があります。
|
||
|
||
|
||
|
||
##### Max train epoch
|
||
|
||
学習のための最大エポック数を指定します。Epochオプションでエポック数を指定するのが基本ですが、ここで指定したエポック数に達すると必ず学習を終了します。
|
||
|
||
デフォルトは空欄です。空欄のままで構いません。
|
||
|
||
|
||
|
||
##### Max num workers for DataLoader
|
||
|
||
学習のためのデータを読み込む時に使用するCPUプロセス数を指定するオプションです。この数値を上げるごとにサブプロセスが有効になりデータの読み込みスピードが上がりますが、数字を上げすぎるとかえって非効率になる場合があります。
|
||
|
||
なお、どれだけ大きい数字を指定しても、使用CPUの同時実行スレッド数以上にはなりません。
|
||
|
||
デフォルトは0で、CPUのメインプロセスでのみデータ読み込みを行います。
|
||
|
||
|
||
|
||
##### WANDB [API](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/API) Key
|
||
|
||
「[WandB](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://wandb.ai/site)」(Weights&Biases)という[機械学習](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25B5%25A1%25B3%25A3%25B3%25D8%25BD%25AC)サービスがあります。これは最適な設定を見つけるために学習の進行状況をグラフで表示したり学習ログなどをオンラインで記録、共有するサービスですが、kohya_ssでもこのサービスを使用できるようになりました。
|
||
|
||
ただしこのサービスのアカウントが必要です。アカウントを作成した後、[https://app.wandb.ai/authorize](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://app.wandb.ai/authorize)から「[API](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/API)
|
||
key」を取得できます。取得した[API](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/API)キーをここに入力しておくと、学習時に自動的にログインし、WandBのサービスと連動できるようになります。
|
||
|
||
WandBに関する詳細は省きますが、「LoRA職人」を目指す人は試してみましょう。
|
||
|
||
|
||
|
||
##### WANDB Logging
|
||
|
||
学習状況のログをWandBサービスを使って記録するかどうかをここで指定できます。
|
||
|
||
デフォルトはオフで、オフの場合は「tensorboard」というツールの形式でログを記録します。
|
||
|
||
|
||
|
||
#### Sample images config
|
||
|
||
LoRAを使った画像生成がどんな感じになるのか学習途中でチェックしたい場合、ここで画像生成プロンプトを入力します。
|
||
|
||
ただ、LoRAは比較的学習時間が短いので、画像生成テストの必要はあまりないかもしれません。
|
||
|
||
|
||
|
||
##### Sample every n steps
|
||
|
||
学習中、何ステップ目に画像を生成したいのかを指定します。例えば100と指定すると、100ステップごとに画像を生成します。
|
||
|
||
デフォルトは0で、0の場合は画像を生成しません。
|
||
|
||
|
||
|
||
##### Sample every n epochs
|
||
|
||
学習中、何エポック目に画像を生成したいのかを指定します。例えば2と指定すると、2エポックごとに画像を生成します。
|
||
|
||
デフォルトは0で、0の場合は画像を生成しません。
|
||
|
||
|
||
|
||
##### Sample sampler
|
||
|
||
画像生成に使う[サンプラー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25B5%25A5%25F3%25A5%25D7%25A5%25E9%25A1%25BC)を指定します。ここで指定する[サンプラー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25B5%25A5%25F3%25A5%25D7%25A5%25E9%25A1%25BC)の多くはStable
|
||
Diffusion Web
|
||
UIで用意されている[サンプラー](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25B5%25A5%25F3%25A5%25D7%25A5%25E9%25A1%25BC)と同じなので、詳細はWeb
|
||
UIの説明サイトを参照してください。
|
||
|
||
デフォルトはeuler_aです。
|
||
|
||
|
||
|
||
##### Sample prompts
|
||
|
||
ここでプロンプトを入力します。
|
||
|
||
ただしここにはプロンプトだけでなく他の設定も入力できます。ほかの設定を入力する場合は「--n」のようにマイナス2つとアルファベットを組み合わせて設定を指定します。例えばネガティ[ブプロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D6%25A5%25D7%25A5%25ED%25A5%25F3)プトに「white,
|
||
dog」と入れたい場合、「--n white, dog」と書きます。
|
||
|
||
よく使いそうな設定の指定は以下の通りです。
|
||
|
||
\--n:ネガティ[ブプロン](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25A5%25D6%25A5%25D7%25A5%25ED%25A5%25F3)プト
|
||
|
||
\--w:画像の幅
|
||
|
||
\--h:画像の高さ
|
||
|
||
\--d:Seed
|
||
|
||
\--l:CFG Scale
|
||
|
||
\--s:ステップ数
|
||
|
||
デフォルトは空欄です。空欄の時に記述例が薄く表示されているので、それを参考にしてください。
|
||
|
||
|
||
|
||
### まとめ
|
||
|
||
Stable Diffusionの追加学習のひとつであるLoRAのしくみと、LoRA学習を行うツールであるkohya_ssの各設定について解説しました。
|
||
|
||
設定する項目が非常に多いので混乱しそうですが、まずは推奨設定で軽く学習して、学習結果に応じて少しずつ設定を変えていくようにしましょう。
|
||
|
||
ここでの解説を参考にして、さらに高い精度のLoRA作成を目指してみてください。
|
||
|
||
[ Stable Diffusion ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/Stable%2520Diffusion?from%3Dhatenablog%26utm_source%3Dhoshikat.hatenablog.com%26utm_medium%3Dhatenablog%26utm_campaign%3Dblogtag%26utm_term%3DStable%2BDiffusion%26utm_content%3D%252Fentry%252F2023%252F05%252F26%252F223229)
|
||
[ お絵描きAI ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/%25E3%2581%258A%25E7%25B5%25B5%25E6%258F%258F%25E3%2581%258DAI?from%3Dhatenablog%26utm_source%3Dhoshikat.hatenablog.com%26utm_medium%3Dhatenablog%26utm_campaign%3Dblogtag%26utm_term%3D%25E3%2581%258A%25E7%25B5%25B5%25E6%258F%258F%25E3%2581%258DAI%26utm_content%3D%252Fentry%252F2023%252F05%252F26%252F223229)
|
||
[ LoRA ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/LoRA?from%3Dhatenablog%26utm_source%3Dhoshikat.hatenablog.com%26utm_medium%3Dhatenablog%26utm_campaign%3Dblogtag%26utm_term%3DLoRA%26utm_content%3D%252Fentry%252F2023%252F05%252F26%252F223229)
|
||
[ kohya_ss ](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://d.hatena.ne.jp/keyword/kohya_ss?from%3Dhatenablog%26utm_source%3Dhoshikat.hatenablog.com%26utm_medium%3Dhatenablog%26utm_campaign%3Dblogtag%26utm_term%3Dkohya_ss%26utm_content%3D%252Fentry%252F2023%252F05%252F26%252F223229)
|
||
|
||
hoshikat [2023-05-26 22:32](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://b.hatena.ne.jp/entry/s/hoshikat.hatenablog.com/entry/2023/05/26/223229
|
||
"この記事をはてなブックマークに追加")
|
||
|
||
[Tweet](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://twitter.com/share)
|
||
|
||
[広告を非表示にする](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=http://blog.hatena.ne.jp/guide/pro)
|
||
|
||
関連記事
|
||
|
||
* [  ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/13/002443?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[ 2023-06-13 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/06/13?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[誰でもわかるStable Diffusion テキストエンコーダー:CLIPのしくみ](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/06/13/002443?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
以前の記事でStable Diffusionがどのように絵を描いているか順…
|
||
|
||
* [  ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/07/215433?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[ 2023-06-07 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/06/07?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[誰でもわかるStable Diffusion LoRAを作ってみよう(実践編)](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/06/07/215433?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
以前の記事でLoRAを作るためのKohya_ss導入の解説を書きました*…
|
||
|
||
* [  ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/05/05/013600?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[ 2023-05-05 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/05/05?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[誰でもわかるStable Diffusion LoRAを作ってみよう(導入編)](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/05/05/013600?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
Stable Diffusionはそのままでも十分きれいな画像を描いてくれ…
|
||
|
||
* [ 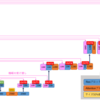 ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/04/12/003127?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[ 2023-04-12 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/04/12?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[誰でもわかるStable Diffusion その6:U-Net(IN1、Resブロック)](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/04/12/003127?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
Stable DiffusionのU-Net解説の3回目です。 今回はIN1ブロック…
|
||
|
||
* [  ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/04/03/215537?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[ 2023-04-03 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023/04/03?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[誰でもわかるStable diffusion その5:U-Net(IN0ブロックと畳み込み)](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/04/03/215537?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
Stable Diffusionで使われるU-Netの最初のブロック、IN0層につ…
|
||
|
||
* もっと読む
|
||
|
||
コメントを書く
|
||
|
||
[ « 誰でもわかるStable Diffusion LoRAを作… ](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/06/07/215433?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp) [ AIお絵描きをめぐる問題 これまでとこれ… » ](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/05/17/183410?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
プロフィール
|
||
|
||
[  ](https://hoshikat-hatenablog-
|
||
com.translate.goog/about?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp) [id:hoshikat](https://hoshikat-hatenablog-
|
||
com.translate.goog/about?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
[ 読者です 読者をやめる 読者になる 読者になる ](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp#)
|
||
|
||
____
|
||
|
||
[このブログについて](https://hoshikat-hatenablog-
|
||
com.translate.goog/about?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
検索
|
||
|
||
リンク
|
||
|
||
* [はてなブログ](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://hatenablog.com/)
|
||
* [ブログをはじめる](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://hatenablog.com/guide?via%3D200109)
|
||
* [週刊はてなブログ](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=http://blog.hatenablog.com)
|
||
* [はてなブログPro](https://translate.google.com/website?sl=auto&tl=en&hl=en-US&client=webapp&u=https://hatenablog.com/guide/pro)
|
||
|
||
[ 最新記事 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
* [誰でもわかるStable Diffusion リージョナルプロンプト](https://hoshikat-hatenablog-com.translate.goog/entry/2023/07/11/004307?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
* [誰でもわかるStable Diffusion スケジューラー](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/30/212231?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
* [誰でもわかるStable Diffusion CFGスケールのしくみ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/17/021610?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
* [誰でもわかるStable Diffusion テキストエンコーダー:CLIPのしくみ](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/13/002443?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
* [誰でもわかるStable Diffusion LoRAを作ってみよう(実践編)](https://hoshikat-hatenablog-com.translate.goog/entry/2023/06/07/215433?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
[月別アーカイブ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
* ▼ ▶
|
||
|
||
[ 2023 ](https://hoshikat-hatenablog-
|
||
com.translate.goog/archive/2023?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp)
|
||
|
||
* [ 2023 / 7 ](https://hoshikat-hatenablog-com.translate.goog/archive/2023/7?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
* [ 2023 / 6 ](https://hoshikat-hatenablog-com.translate.goog/archive/2023/6?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
* [ 2023 / 5 ](https://hoshikat-hatenablog-com.translate.goog/archive/2023/5?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
* [ 2023 / 4 ](https://hoshikat-hatenablog-com.translate.goog/archive/2023/4?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
* [ 2023 / 3 ](https://hoshikat-hatenablog-com.translate.goog/archive/2023/3?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||

|
||
|
||
### はてなブログをはじめよう!
|
||
|
||
hoshikatさんは、はてなブログを使っています。あなたもはてなブログをはじめてみませんか?
|
||
|
||
[はてなブログをはじめる(無料)](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://blog.hatena.ne.jp/register?via%3D200227)
|
||
|
||
[はてなブログとは](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://hatenablog.com/guide)
|
||
|
||
[  人工知能と親しくなるブログ
|
||
](https://hoshikat-hatenablog-
|
||
com.translate.goog/?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-US&_x_tr_pto=wapp)
|
||
|
||
Powered by [Hatena
|
||
Blog](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://hatenablog.com/) |
|
||
[ブログを報告する](https://translate.google.com/website?sl=auto&tl=en&hl=en-
|
||
US&client=webapp&u=https://blog.hatena.ne.jp/-/abuse_report?target_url%3Dhttps%253A%252F%252Fhoshikat.hatenablog.com%252Fentry%252F2023%252F05%252F26%252F223229)
|
||
|
||
__
|
||
|
||
__
|
||
|
||
引用をストックしました
|
||
|
||
ストック一覧を見る 閉じる
|
||
|
||
引用するにはまずログインしてください
|
||
|
||
ログイン 閉じる
|
||
|
||
引用をストックできませんでした。再度お試しください
|
||
|
||
閉じる
|
||
|
||
限定公開記事のため引用できません。
|
||
|
||
[ 読者です 読者をやめる 読者になる 読者になる ](https://hoshikat-hatenablog-
|
||
com.translate.goog/entry/2023/05/26/223229?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=en-
|
||
US&_x_tr_pto=wapp#)
|
||
|
||
____
|
||
|