Major update, UI, Controls, Bug Fix, Speed up computation...
parent
f2bfff251c
commit
7a817b3863
|
|
@ -14,3 +14,5 @@ scripts/wav2lip/output/masks/*.png
|
|||
scripts/wav2lip/output/*.mp4
|
||||
scripts/wav2lip/output/*.aac
|
||||
scripts/wav2lip/results/result_voice.mp4
|
||||
scripts/wav2lip/temp/*.avi
|
||||
scripts/wav2lip/temp/*.wav
|
||||
|
|
|
|||
|
|
@ -24,6 +24,6 @@ Before submitting a pull request, please make sure your code adheres to the proj
|
|||
|
||||
## Contact
|
||||
|
||||
If you have any questions or need help, please ping the developer via email at numzzz@hotmail.com to make sure your addition will fit well into such a large project and to get help if needed.
|
||||
If you have any questions or need help, please ping the developer via discord NumZ#7184 to make sure your addition will fit well into such a large project and to get help if needed.
|
||||
|
||||
Thank you again for your contribution!
|
||||
|
|
|
|||
105
README.md
105
README.md
|
|
@ -1,27 +1,44 @@
|
|||
# Wav2Lip UHQ extension for Stable diffusion webui Automatic1111
|
||||
# 🔉👄 Wav2Lip UHQ extension for Stable Diffusion WebUI Automatic1111
|
||||
|
||||
|
||||

|
||||
|
||||
Result video can be find here : https://www.youtube.com/watch?v=-3WLUxz6XKM
|
||||
|
||||
https://user-images.githubusercontent.com/800903/258139382-6594f243-b43d-46b9-89f1-7a9f8f47b764.mp4
|
||||
|
||||
## Description
|
||||
## 💡 Description
|
||||
This repository contains a Wav2Lip UHQ extension for Automatic1111.
|
||||
|
||||
It's an all-in-one solution: just choose a video and a speech file (wav or mp3), and it will generate a lip-sync video. It improves the quality of the lip-sync videos generated by the [Wav2Lip tool](https://github.com/Rudrabha/Wav2Lip) by applying specific post-processing techniques with Stable diffusion.
|
||||
It's an all-in-one solution: just choose a video and a speech file (wav or mp3), and the extension will generate a lip-sync video. It improves the quality of the lip-sync videos generated by the [Wav2Lip tool](https://github.com/Rudrabha/Wav2Lip) by applying specific post-processing techniques with Stable diffusion tools.
|
||||
|
||||

|
||||
|
||||
|
||||
## Requirements
|
||||
- latest version of Stable diffusion webui automatic1111
|
||||
- FFmpeg
|
||||
## 📖 Quick Index
|
||||
* [🚀 Updates](#-Updates)
|
||||
* [🔗 Requirements](#-Requirements)
|
||||
* [💻 Installation](#-Installation)
|
||||
* [🐍 Usage](#-Usage)
|
||||
* [📖 Behind the scenes](#-Behind-the-scenes)
|
||||
* [💪 Quality tips](#-Quality-tips)
|
||||
* [📝 TODO](#-TODO)
|
||||
* [😎 Contributing](#-Contributing)
|
||||
* [🙏 Appreciation](#-Appreciation)
|
||||
* [📝 Citation](#-Citation)
|
||||
* [📜 License](#-License)
|
||||
|
||||
1. Install Stable Diffusion WebUI by following the instructions on the [Stable Diffusion Webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) repository.
|
||||
2. Download FFmpeg from the [official FFmpeg site](https://ffmpeg.org/download.html). Follow the instructions appropriate for your operating system. Note that FFmpeg should be accessible from the command line.
|
||||
## 🚀 Updates
|
||||
|
||||
## Installation
|
||||
**2023.08.13**
|
||||
- ⚡ Speed-up computation
|
||||
- 🚢 Change User Interface : Add controls on hidden parameters
|
||||
- 👄 Only Track mouth if needed
|
||||
- 📰 Control debug
|
||||
- 🐛 Fix resize factor bug
|
||||
|
||||
|
||||
## 🔗 Requirements
|
||||
- latest version of Stable Diffusion WebUI Automatic1111 by following the instructions on the [Stable Diffusion Webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) repository.
|
||||
|
||||
## 💻 Installation
|
||||
|
||||
1. Launch Automatic1111
|
||||
2. In the extensions tab, enter the following URL in the "Install from URL" field and click "Install":
|
||||
|
|
@ -32,48 +49,76 @@ It's an all-in-one solution: just choose a video and a speech file (wav or mp3),
|
|||
|
||||

|
||||
|
||||
5. if you don't see the "Wav2lip Uhq tab" restart automatic1111.
|
||||
4. If you don't see the "Wav2Lip UHQ tab" restart Automatic1111.
|
||||
|
||||
6. 🔥 Important: Get the weights. Download the model weights from the following locations and place them in the corresponding directories:
|
||||
5. 🔥 Important: Get the weights. Download the model weights from the following locations and place them in the corresponding directories (take care about the filename, especially for s3fd)
|
||||
|
||||
| Model | Description | Link to the model | install folder |
|
||||
|:-------------------:|:----------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------:|
|
||||
| Wav2Lip | Highly accurate lip-sync | [Link](https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/Eb3LEzbfuKlJiR600lQWRxgBIY27JZg80f7V9jtMfbNDaQ?e=TBFBVW) | extensions\sd-wav2lip-uhq\scripts\wav2lip\checkpoints\ |
|
||||
| Wav2Lip + GAN | Slightly inferior lip-sync, but better visual quality | [Link](https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/EdjI7bZlgApMqsVoEUUXpLsBxqXbn5z8VTmoxp55YNDcIA?e=n9ljGW) | extensions\sd-wav2lip-uhq\scripts\wav2lip\checkpoints\ |
|
||||
| s3fd | Face Detection pre trained model | [Link](https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth) | extensions\sd-wav2lip-uhq\scripts\wav2lip\face_detection\detection\sfd\s3fd.pth |
|
||||
| s3fd | Face Detection pre trained model (alternate link) | [Link](https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth) | extensions\sd-wav2lip-uhq\scripts\wav2lip\face_detection\detection\sfd\s3fd.pth |
|
||||
| landmark predicator | Dlib 68 point face landmark prediction (click on the download icon) | [Link](https://github.com/numz/wav2lip_uhq/blob/main/predicator/shape_predictor_68_face_landmarks.dat) | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
|
||||
| landmark predicator | Dlib 68 point face landmark prediction (alternate link) | [Link](https://huggingface.co/spaces/asdasdasdasd/Face-forgery-detection/resolve/ccfc24642e0210d4d885bc7b3dbc9a68ed948ad6/shape_predictor_68_face_landmarks.dat) | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
|
||||
| landmark predicator | Dlib 68 point face landmark prediction (alternate link click on the download icon) | [Link](https://github.com/italojs/facial-landmarks-recognition/blob/master/shape_predictor_68_face_landmarks.dat) | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
|
||||
|
||||
|
||||
## Usage
|
||||
## 🐍 Usage
|
||||
1. Choose a video or an image.
|
||||
2. Choose an audio file with speech.
|
||||
3. choose a checkpoint (see table above).
|
||||
4. **Padding**: Wav2Lip uses this to add a black border around the mouth, which is useful to prevent the mouth from being cropped by the face detection. You can change the padding value to suit your needs, but the default value gives good results.
|
||||
5. **No Smooth**: If checked, the mouth will not be smoothed. This can be useful if you want to keep the original mouth shape.
|
||||
4. **Padding**: Wav2Lip uses this to add a black border around the mouth, which is useful to prevent the mouth from being cropped by the face detection. You can change the padding value to suit your needs, but the default value gives good results.
|
||||
5. **No Smooth**: When checked, this option retains the original mouth shape without smoothing.
|
||||
6. **Resize Factor**: This is a resize factor for the video. The default value is 1.0, but you can change it to suit your needs. This is useful if the video size is too large.
|
||||
7. Choose a good Stable diffusion checkpoint, like [delibarate_v2](https://civitai.com/models/4823/deliberate) or [revAnimated_v122](https://civitai.com/models/7371) (SDXL models don't seem to work, but you can generate a SDXL image and change model for wav2lip process).
|
||||
8. Click on the "Generate" button.
|
||||
7. **Only Mouth**: This option tracks only the mouth, removing other facial motions like those of the cheeks and chin.
|
||||
8. **Mouth Mask Dilate**: This will dilate the mouth mask to cover more area around the mouth. depends on the mouth size.
|
||||
9. **Face Mask Erode**: This will erode the face mask to remove some area around the face. depends on the face size.
|
||||
10. **Mask Blur**: This will blur the mask to make it more smooth, try to keep it under or equal to **Mouth Mask Dilate**.
|
||||
11. **Active debug**: This will create step-by-step images in the debug folder.
|
||||
12. Click on the "Generate" button.
|
||||
|
||||
## Behind the scenes
|
||||
## 📖 Behind the scenes
|
||||
|
||||
This extension operates in several stages to improve the quality of Wav2Lip-generated videos:
|
||||
|
||||
1. **Generate a Wav2lip video**: The script first generates a low-quality Wav2Lip video using the input video and audio.
|
||||
2. **Mask Creation**: The script creates a mask around the mouth and try to keep other face motion like cheeks and chin.
|
||||
3. **Video Quality Enhancement**: It takes the low-quality Wav2Lip video and overlays the low-quality mouth onto the high-quality original video.
|
||||
4. **Img2Img**: The script then sends the original image with the low-quality mouth and the mouth mask into Img2Img.
|
||||
2. **Mask Creation**: The script creates a mask around the mouth and tries to keep other facial motions like those of the cheeks and chin.
|
||||
3. **Video Quality Enhancement**: It takes the low-quality Wav2Lip video and overlays the low-quality mouth onto the high-quality original video guided by the mouth mask.
|
||||
4. **Face Enhancer**: The script then sends the original image with the low-quality mouth on face_enhancer tool of stable diffusion to generate a high-quality mouth image.
|
||||
5. **Video Generation**: The script then takes the high-quality mouth image and overlays it onto the original image guided by the mouth mask.
|
||||
6. **Video Post Processing**: The script then uses the ffmpeg tool to generate the final video.
|
||||
|
||||
## Quality tips
|
||||
## 💪 Quality tips
|
||||
- Use a high quality image/video as input
|
||||
- Try to minimize the grain on the face on the input as much as possible, for example you can try to use "Restore faces" in img2img before use an image as wav2lip input.
|
||||
- Use a high quality model in stable diffusion webui like [delibarate_v2](https://civitai.com/models/4823/deliberate) or [revAnimated_v122](https://civitai.com/models/7371)
|
||||
- Try to minimize the grain on the face on the input as much as possible. For example, you can use the "Restore faces" feature in img2img before using an image as input for Wav2Lip.
|
||||
- Dilate the mouth mask. This will help the model retain some facial motion and hide the original mouth.
|
||||
- Mask Blur less or equal to Dilate Mouth Mask.
|
||||
|
||||
## Contributing
|
||||
## 📝 TODO
|
||||
- [ ] Add Suno/Bark to generate high quality text to speech audio as wav file input (see [bark](https://github.com/suno-ai/bark/))
|
||||
|
||||
Contributions to this project are welcome. Please ensure any pull requests are accompanied by a detailed description of the changes made.
|
||||
## 😎 Contributing
|
||||
|
||||
## License
|
||||
We welcome contributions to this project. When submitting pull requests, please provide a detailed description of the changes. see [CONTRIBUTING](CONTRIBUTING.md) for more information.
|
||||
|
||||
## 🙏 Appreciation
|
||||
- [Wav2Lip](https://github.com/Rudrabha/Wav2Lip)
|
||||
|
||||
## 📝 Citation
|
||||
If you use this project in your own work, in articles, tutorials, or presentations, we encourage you to cite this project to acknowledge the efforts put into it.
|
||||
|
||||
To cite this project, please use the following BibTeX format:
|
||||
|
||||
```
|
||||
@misc{wav2lip_uhq,
|
||||
author = {numz},
|
||||
title = {Wav2Lip UHQ},
|
||||
year = {2023},
|
||||
howpublished = {GitHub repository},
|
||||
publisher = {numz},
|
||||
url = {https://github.com/numz/sd-wav2lip-uhq}
|
||||
}
|
||||
```
|
||||
|
||||
## 📜 License
|
||||
* The code in this repository is released under the MIT license as found in the [LICENSE file](LICENSE).
|
||||
|
|
|
|||
|
|
@ -2,55 +2,79 @@ from scripts.wav2lip_uhq_extend_paths import wav2lip_uhq_sys_extend
|
|||
import gradio as gr
|
||||
from scripts.wav2lip.w2l import W2l
|
||||
from scripts.wav2lip.wav2lip_uhq import Wav2LipUHQ
|
||||
from modules.shared import opts, state
|
||||
from pathlib import Path
|
||||
from modules.shared import state
|
||||
|
||||
|
||||
def on_ui_tabs():
|
||||
wav2lip_uhq_sys_extend()
|
||||
|
||||
with gr.Blocks(analytics_enabled=False) as wav2lip_uhq_interface:
|
||||
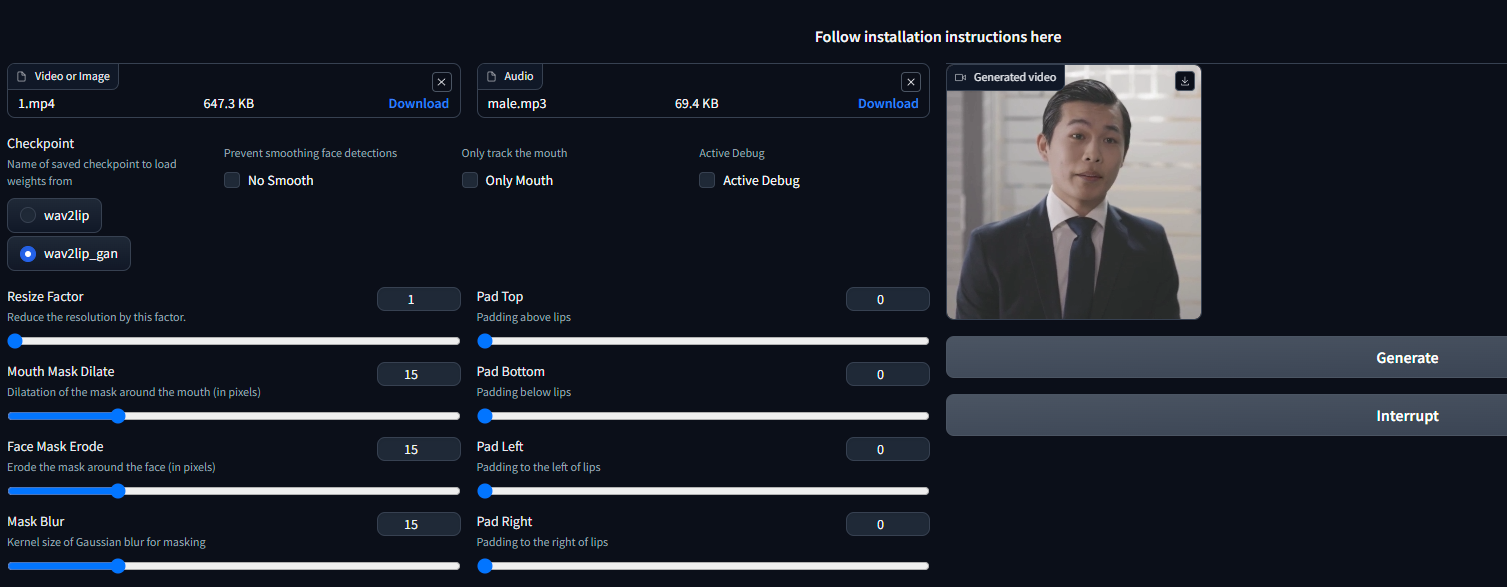
gr.Markdown("<div align='center'> <h3> Follow installation instructions <a href='https://github.com/numz/sd-wav2lip-uhq'> here </a> </h3> </div>")
|
||||
with gr.Row():
|
||||
video = gr.File(label="Video or Image", info="Filepath of video/image that contains faces to use")
|
||||
audio = gr.File(label="Audio", info="Filepath of video/audio file to use as raw audio source")
|
||||
with gr.Column():
|
||||
checkpoint = gr.Radio(["wav2lip", "wav2lip_gan"], value="wav2lip_gan", label="Checkpoint", info="Name of saved checkpoint to load weights from")
|
||||
no_smooth = gr.Checkbox(label="No Smooth", info="Prevent smoothing face detections over a short temporal window")
|
||||
resize_factor = gr.Slider(minimum=1, maximum=4, step=1, label="Resize Factor", info="Reduce the resolution by this factor. Sometimes, best results are obtained at 480p or 720p")
|
||||
generate_btn = gr.Button("Generate")
|
||||
interrupt_btn = gr.Button('Interrupt', elem_id=f"interrupt", visible=True)
|
||||
|
||||
gr.Markdown(
|
||||
"<div align='center'> <h3><a href='https://github.com/numz/sd-wav2lip-uhq'> Follow installation instructions here </a> </h3> </div>")
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
pad_top = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Top", info="Padding above lips")
|
||||
pad_bottom = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Bottom", info="Padding below lips")
|
||||
pad_left = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Left", info="Padding to the left of lips")
|
||||
pad_right = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Right", info="Padding to the right of lips")
|
||||
with gr.Row():
|
||||
video = gr.File(label="Video or Image", info="Filepath of video/image that contains faces to use",
|
||||
file_types=["mp4", "png", "jpg", "jpeg", "avi"])
|
||||
audio = gr.File(label="Audio", info="Filepath of video/audio file to use as raw audio source",
|
||||
file_types=["mp3", "wav"])
|
||||
with gr.Row():
|
||||
checkpoint = gr.Radio(["wav2lip", "wav2lip_gan"], value="wav2lip_gan", label="Checkpoint",
|
||||
info="Name of saved checkpoint to load weights from")
|
||||
no_smooth = gr.Checkbox(label="No Smooth", info="Prevent smoothing face detections")
|
||||
only_mouth = gr.Checkbox(label="Only Mouth", info="Only track the mouth")
|
||||
active_debug = gr.Checkbox(label="Active Debug", info="Active Debug")
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
resize_factor = gr.Slider(minimum=1, maximum=4, step=1, label="Resize Factor",
|
||||
info="Reduce the resolution by this factor.")
|
||||
mouth_mask_dilatation = gr.Slider(minimum=0, maximum=64, step=1, value=15,
|
||||
label="Mouth Mask Dilate",
|
||||
info="Dilatation of the mask around the mouth (in pixels)")
|
||||
erode_face_mask = gr.Slider(minimum=0, maximum=64, step=1, value=15, label="Face Mask Erode",
|
||||
info="Erode the mask around the face (in pixels)")
|
||||
mask_blur = gr.Slider(minimum=0, maximum=64, step=1, value=15, label="Mask Blur",
|
||||
info="Kernel size of Gaussian blur for masking")
|
||||
with gr.Column():
|
||||
pad_top = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Top",
|
||||
info="Padding above lips")
|
||||
pad_bottom = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Bottom",
|
||||
info="Padding below lips")
|
||||
pad_left = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Left",
|
||||
info="Padding to the left of lips")
|
||||
pad_right = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Right",
|
||||
info="Padding to the right of lips")
|
||||
|
||||
with gr.Column():
|
||||
with gr.Tabs(elem_id="wav2lip_generated"):
|
||||
result = gr.Video(label="Generated video", format="mp4").style(width=256)
|
||||
|
||||
result = gr.Video(label="Generated video", format="mp4").style(width=512)
|
||||
generate_btn = gr.Button("Generate")
|
||||
interrupt_btn = gr.Button('Interrupt', elem_id=f"interrupt", visible=True)
|
||||
|
||||
def on_interrupt():
|
||||
state.interrupt()
|
||||
return "Interrupted"
|
||||
|
||||
def generate(video, audio, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right):
|
||||
def generate(video, audio, checkpoint, no_smooth, only_mouth, resize_factor, mouth_mask_dilatation,
|
||||
erode_face_mask, mask_blur, pad_top, pad_bottom, pad_left, pad_right, active_debug):
|
||||
state.begin()
|
||||
if video is None or audio is None or checkpoint is None:
|
||||
return
|
||||
w2l = W2l(video.name, audio.name, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right)
|
||||
w2l = W2l(video.name, audio.name, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left,
|
||||
pad_right)
|
||||
w2l.execute()
|
||||
|
||||
w2luhq = Wav2LipUHQ(video.name, audio.name)
|
||||
w2luhq.execute()
|
||||
return str(Path("extensions/sd-wav2lip-uhq/scripts/wav2lip/output/output_video.mp4"))
|
||||
w2luhq = Wav2LipUHQ(video.name, audio.name, mouth_mask_dilatation, erode_face_mask, mask_blur, only_mouth,
|
||||
resize_factor, active_debug)
|
||||
|
||||
return w2luhq.execute()
|
||||
|
||||
generate_btn.click(
|
||||
generate,
|
||||
[video, audio, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right],
|
||||
generate,
|
||||
[video, audio, checkpoint, no_smooth, only_mouth, resize_factor, mouth_mask_dilatation, erode_face_mask,
|
||||
mask_blur, pad_top, pad_bottom, pad_left, pad_right, active_debug],
|
||||
result)
|
||||
|
||||
interrupt_btn.click(on_interrupt)
|
||||
|
||||
|
||||
return [(wav2lip_uhq_interface, "Wav2lip Uhq", "wav2lip_uhq_interface")]
|
||||
|
|
|
|||
|
|
@ -1,7 +1,6 @@
|
|||
import librosa
|
||||
import librosa.filters
|
||||
import numpy as np
|
||||
# import tensorflow as tf
|
||||
from scipy import signal
|
||||
from scipy.io import wavfile
|
||||
from scripts.wav2lip.hparams import hparams as hp
|
||||
|
|
@ -13,7 +12,6 @@ def load_wav(path, sr):
|
|||
|
||||
def save_wav(wav, path, sr):
|
||||
wav *= 32767 / max(0.01, np.max(np.abs(wav)))
|
||||
# proposed by @dsmiller
|
||||
wavfile.write(path, sr, wav.astype(np.int16))
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,16 +1,11 @@
|
|||
from __future__ import print_function
|
||||
import os
|
||||
import torch
|
||||
from torch.utils.model_zoo import load_url
|
||||
from enum import Enum
|
||||
import numpy as np
|
||||
import cv2
|
||||
|
||||
try:
|
||||
import urllib.request as request_file
|
||||
except BaseException:
|
||||
import urllib as request_file
|
||||
|
||||
from .models import FAN, ResNetDepth
|
||||
from .utils import *
|
||||
|
||||
|
||||
|
|
@ -41,8 +36,10 @@ class NetworkSize(Enum):
|
|||
def __int__(self):
|
||||
return self.value
|
||||
|
||||
|
||||
ROOT = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
|
||||
class FaceAlignment:
|
||||
def __init__(self, landmarks_type, network_size=NetworkSize.LARGE,
|
||||
device='cuda', flip_input=False, face_detector='sfd', verbose=False):
|
||||
|
|
@ -72,8 +69,8 @@ class FaceAlignment:
|
|||
continue
|
||||
d = d[0]
|
||||
d = np.clip(d, 0, None)
|
||||
|
||||
|
||||
x1, y1, x2, y2 = map(int, d[:-1])
|
||||
results.append((x1, y1, x2, y2))
|
||||
|
||||
return results
|
||||
return results
|
||||
|
|
|
|||
|
|
@ -1,101 +1,103 @@
|
|||
from glob import glob
|
||||
import os
|
||||
|
||||
|
||||
def get_image_list(data_root, split):
|
||||
filelist = []
|
||||
filelist = []
|
||||
|
||||
with open('filelists/{}.txt'.format(split)) as f:
|
||||
for line in f:
|
||||
line = line.strip()
|
||||
if ' ' in line: line = line.split()[0]
|
||||
filelist.append(os.path.join(data_root, line))
|
||||
with open('filelists/{}.txt'.format(split)) as f:
|
||||
for line in f:
|
||||
line = line.strip()
|
||||
if ' ' in line: line = line.split()[0]
|
||||
filelist.append(os.path.join(data_root, line))
|
||||
|
||||
return filelist
|
||||
|
||||
return filelist
|
||||
|
||||
class HParams:
|
||||
def __init__(self, **kwargs):
|
||||
self.data = {}
|
||||
def __init__(self, **kwargs):
|
||||
self.data = {}
|
||||
|
||||
for key, value in kwargs.items():
|
||||
self.data[key] = value
|
||||
for key, value in kwargs.items():
|
||||
self.data[key] = value
|
||||
|
||||
def __getattr__(self, key):
|
||||
if key not in self.data:
|
||||
raise AttributeError("'HParams' object has no attribute %s" % key)
|
||||
return self.data[key]
|
||||
def __getattr__(self, key):
|
||||
if key not in self.data:
|
||||
raise AttributeError("'HParams' object has no attribute %s" % key)
|
||||
return self.data[key]
|
||||
|
||||
def set_hparam(self, key, value):
|
||||
self.data[key] = value
|
||||
def set_hparam(self, key, value):
|
||||
self.data[key] = value
|
||||
|
||||
|
||||
# Default hyperparameters
|
||||
hparams = HParams(
|
||||
num_mels=80, # Number of mel-spectrogram channels and local conditioning dimensionality
|
||||
# network
|
||||
rescale=True, # Whether to rescale audio prior to preprocessing
|
||||
rescaling_max=0.9, # Rescaling value
|
||||
|
||||
# Use LWS (https://github.com/Jonathan-LeRoux/lws) for STFT and phase reconstruction
|
||||
# It"s preferred to set True to use with https://github.com/r9y9/wavenet_vocoder
|
||||
# Does not work if n_ffit is not multiple of hop_size!!
|
||||
use_lws=False,
|
||||
|
||||
n_fft=800, # Extra window size is filled with 0 paddings to match this parameter
|
||||
hop_size=200, # For 16000Hz, 200 = 12.5 ms (0.0125 * sample_rate)
|
||||
win_size=800, # For 16000Hz, 800 = 50 ms (If None, win_size = n_fft) (0.05 * sample_rate)
|
||||
sample_rate=16000, # 16000Hz (corresponding to librispeech) (sox --i <filename>)
|
||||
|
||||
frame_shift_ms=None, # Can replace hop_size parameter. (Recommended: 12.5)
|
||||
|
||||
# Mel and Linear spectrograms normalization/scaling and clipping
|
||||
signal_normalization=True,
|
||||
# Whether to normalize mel spectrograms to some predefined range (following below parameters)
|
||||
allow_clipping_in_normalization=True, # Only relevant if mel_normalization = True
|
||||
symmetric_mels=True,
|
||||
# Whether to scale the data to be symmetric around 0. (Also multiplies the output range by 2,
|
||||
# faster and cleaner convergence)
|
||||
max_abs_value=4.,
|
||||
# max absolute value of data. If symmetric, data will be [-max, max] else [0, max] (Must not
|
||||
# be too big to avoid gradient explosion,
|
||||
# not too small for fast convergence)
|
||||
# Contribution by @begeekmyfriend
|
||||
# Spectrogram Pre-Emphasis (Lfilter: Reduce spectrogram noise and helps model certitude
|
||||
# levels. Also allows for better G&L phase reconstruction)
|
||||
preemphasize=True, # whether to apply filter
|
||||
preemphasis=0.97, # filter coefficient.
|
||||
|
||||
# Limits
|
||||
min_level_db=-100,
|
||||
ref_level_db=20,
|
||||
fmin=55,
|
||||
# Set this to 55 if your speaker is male! if female, 95 should help taking off noise. (To
|
||||
# test depending on dataset. Pitch info: male~[65, 260], female~[100, 525])
|
||||
fmax=7600, # To be increased/reduced depending on data.
|
||||
num_mels=80, # Number of mel-spectrogram channels and local conditioning dimensionality
|
||||
# network
|
||||
rescale=True, # Whether to rescale audio prior to preprocessing
|
||||
rescaling_max=0.9, # Rescaling value
|
||||
|
||||
###################### Our training parameters #################################
|
||||
img_size=96,
|
||||
fps=25,
|
||||
|
||||
batch_size=16,
|
||||
initial_learning_rate=1e-4,
|
||||
nepochs=200000000000000000, ### ctrl + c, stop whenever eval loss is consistently greater than train loss for ~10 epochs
|
||||
num_workers=16,
|
||||
checkpoint_interval=3000,
|
||||
eval_interval=3000,
|
||||
# Use LWS (https://github.com/Jonathan-LeRoux/lws) for STFT and phase reconstruction
|
||||
# It"s preferred to set True to use with https://github.com/r9y9/wavenet_vocoder
|
||||
# Does not work if n_ffit is not multiple of hop_size!!
|
||||
use_lws=False,
|
||||
|
||||
n_fft=800, # Extra window size is filled with 0 paddings to match this parameter
|
||||
hop_size=200, # For 16000Hz, 200 = 12.5 ms (0.0125 * sample_rate)
|
||||
win_size=800, # For 16000Hz, 800 = 50 ms (If None, win_size = n_fft) (0.05 * sample_rate)
|
||||
sample_rate=16000, # 16000Hz (corresponding to librispeech) (sox --i <filename>)
|
||||
|
||||
frame_shift_ms=None, # Can replace hop_size parameter. (Recommended: 12.5)
|
||||
|
||||
# Mel and Linear spectrograms normalization/scaling and clipping
|
||||
signal_normalization=True,
|
||||
# Whether to normalize mel spectrograms to some predefined range (following below parameters)
|
||||
allow_clipping_in_normalization=True, # Only relevant if mel_normalization = True
|
||||
symmetric_mels=True,
|
||||
# Whether to scale the data to be symmetric around 0. (Also multiplies the output range by 2,
|
||||
# faster and cleaner convergence)
|
||||
max_abs_value=4.,
|
||||
# max absolute value of data. If symmetric, data will be [-max, max] else [0, max] (Must not
|
||||
# be too big to avoid gradient explosion,
|
||||
# not too small for fast convergence)
|
||||
# Contribution by @begeekmyfriend
|
||||
# Spectrogram Pre-Emphasis (Lfilter: Reduce spectrogram noise and helps model certitude
|
||||
# levels. Also allows for better G&L phase reconstruction)
|
||||
preemphasize=True, # whether to apply filter
|
||||
preemphasis=0.97, # filter coefficient.
|
||||
|
||||
# Limits
|
||||
min_level_db=-100,
|
||||
ref_level_db=20,
|
||||
fmin=55,
|
||||
# Set this to 55 if your speaker is male! if female, 95 should help taking off noise. (To
|
||||
# test depending on dataset. Pitch info: male~[65, 260], female~[100, 525])
|
||||
fmax=7600, # To be increased/reduced depending on data.
|
||||
|
||||
###################### Our training parameters #################################
|
||||
img_size=96,
|
||||
fps=25,
|
||||
|
||||
batch_size=16,
|
||||
initial_learning_rate=1e-4,
|
||||
nepochs=200000000000000000,
|
||||
### ctrl + c, stop whenever eval loss is consistently greater than train loss for ~10 epochs
|
||||
num_workers=16,
|
||||
checkpoint_interval=3000,
|
||||
eval_interval=3000,
|
||||
save_optimizer_state=True,
|
||||
|
||||
syncnet_wt=0.0, # is initially zero, will be set automatically to 0.03 later. Leads to faster convergence.
|
||||
syncnet_batch_size=64,
|
||||
syncnet_lr=1e-4,
|
||||
syncnet_eval_interval=10000,
|
||||
syncnet_checkpoint_interval=10000,
|
||||
syncnet_wt=0.0, # is initially zero, will be set automatically to 0.03 later. Leads to faster convergence.
|
||||
syncnet_batch_size=64,
|
||||
syncnet_lr=1e-4,
|
||||
syncnet_eval_interval=10000,
|
||||
syncnet_checkpoint_interval=10000,
|
||||
|
||||
disc_wt=0.07,
|
||||
disc_initial_learning_rate=1e-4,
|
||||
disc_wt=0.07,
|
||||
disc_initial_learning_rate=1e-4,
|
||||
)
|
||||
|
||||
|
||||
def hparams_debug_string():
|
||||
values = hparams.values()
|
||||
hp = [" %s: %s" % (name, values[name]) for name in sorted(values) if name != "sentences"]
|
||||
return "Hyperparameters:\n" + "\n".join(hp)
|
||||
values = hparams.values()
|
||||
hp = [" %s: %s" % (name, values[name]) for name in sorted(values) if name != "sentences"]
|
||||
return "Hyperparameters:\n" + "\n".join(hp)
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
images send to stable diffusion
|
||||
|
|
@ -1 +0,0 @@
|
|||
mask send to stable diffusion
|
||||
|
|
@ -4,10 +4,10 @@ import subprocess
|
|||
from tqdm import tqdm
|
||||
import torch, scripts.wav2lip.face_detection as face_detection
|
||||
from scripts.wav2lip.models import Wav2Lip
|
||||
import platform
|
||||
import modules.shared as shared
|
||||
from pkg_resources import resource_filename
|
||||
|
||||
|
||||
class W2l:
|
||||
def __init__(self, face, audio, checkpoint, nosmooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right):
|
||||
self.wav2lip_folder = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-1])
|
||||
|
|
@ -86,7 +86,8 @@ class W2l:
|
|||
for rect, image in zip(predictions, images):
|
||||
if rect is None:
|
||||
print("Hum : " + str(n))
|
||||
cv2.imwrite(self.wav2lip_folder + '/temp/faulty_frame.jpg', image) # check this frame where the face was not detected.
|
||||
cv2.imwrite(self.wav2lip_folder + '/temp/faulty_frame.jpg',
|
||||
image) # check this frame where the face was not detected.
|
||||
raise ValueError('Face not detected! Ensure the video contains a face in all the frames.')
|
||||
|
||||
y1 = max(0, rect[1] - pady1)
|
||||
|
|
|
|||
|
|
@ -1,29 +1,32 @@
|
|||
import os
|
||||
import requests
|
||||
import base64
|
||||
import io
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import cv2
|
||||
import dlib
|
||||
import torch
|
||||
import scripts.wav2lip.face_detection as face_detection
|
||||
from imutils import face_utils
|
||||
import subprocess
|
||||
|
||||
from modules import processing
|
||||
from modules.shared import state
|
||||
from pkg_resources import resource_filename
|
||||
import modules.face_restoration
|
||||
|
||||
|
||||
class Wav2LipUHQ:
|
||||
def __init__(self, face, audio):
|
||||
def __init__(self, face, audio,mouth_mask_dilatation,erode_face_mask, mask_blur, only_mouth, resize_factor, debug=False):
|
||||
self.wav2lip_folder = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-1])
|
||||
self.original_video = face
|
||||
self.audio = audio
|
||||
self.mouth_mask_dilatation = mouth_mask_dilatation
|
||||
self.erode_face_mask = erode_face_mask
|
||||
self.mask_blur = mask_blur
|
||||
self.only_mouth = only_mouth
|
||||
self.w2l_video = self.wav2lip_folder + '/results/result_voice.mp4'
|
||||
self.original_is_image = self.original_video.lower().endswith(
|
||||
('.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif'))
|
||||
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
self.ffmpeg_binary = self.find_ffmpeg_binary()
|
||||
self.resize_factor = resize_factor
|
||||
self.debug = debug
|
||||
|
||||
def find_ffmpeg_binary(self):
|
||||
for package in ['imageio_ffmpeg', 'imageio-ffmpeg']:
|
||||
|
|
@ -72,73 +75,6 @@ class Wav2LipUHQ:
|
|||
"experimental", self.wav2lip_folder + "/output/output_video.mp4"]
|
||||
self.execute_command(command)
|
||||
|
||||
def create_image(self, image, mask, payload, shape, img_count):
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
image = open(image, "rb").read()
|
||||
image_mask = open(mask, "rb").read()
|
||||
url = payload["url"]
|
||||
payload = payload["payload"]
|
||||
payload["init_images"] = ["data:image/png;base64," + base64.b64encode(image).decode('UTF-8')]
|
||||
payload["mask"] = "data:image/png;base64," + base64.b64encode(image_mask).decode('UTF-8')
|
||||
|
||||
path = output_dir
|
||||
response = requests.post(url=f'{url}', json=payload)
|
||||
r = response.json()
|
||||
for idx in range(len(r['images'])):
|
||||
i = r['images'][idx]
|
||||
image = Image.open(io.BytesIO(base64.b64decode(i.split(",", 1)[0])))
|
||||
image_name = path + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
image.save(image_name)
|
||||
|
||||
def create_img(self, image, mask, shape, img_count):
|
||||
image = Image.open(image).convert('RGB')
|
||||
mask = Image.open(mask).convert('RGB')
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
p = processing.StableDiffusionProcessingImg2Img(
|
||||
outpath_samples=output_dir,
|
||||
) # we'll set up the rest later
|
||||
|
||||
p.c = None
|
||||
p.extra_network_data = None
|
||||
p.image_conditioning = None
|
||||
p.init_latent = None
|
||||
p.mask_for_overlay = None
|
||||
p.negative_prompts = None
|
||||
p.nmask = None
|
||||
p.overlay_images = None
|
||||
p.paste_to = None
|
||||
p.prompts = None
|
||||
p.width, p.height = shape[0], shape[1]
|
||||
p.steps = 150
|
||||
p.seed = 65541238
|
||||
p.seed_resize_from_h = 0
|
||||
p.seed_resize_from_w = 0
|
||||
p.seeds = None
|
||||
p.subseeds = None
|
||||
p.uc = None
|
||||
p.sampler = None
|
||||
p.sampler_name = "Euler a"
|
||||
p.tiling = False
|
||||
p.restore_faces = True
|
||||
p.do_not_save_samples = True
|
||||
p.do_not_save_grid = True
|
||||
p.mask_blur = 4
|
||||
p.extra_generation_params["Mask blur"] = 4
|
||||
p.denoising_strength = 0
|
||||
p.cfg_scale = 1
|
||||
p.inpainting_mask_invert = 0
|
||||
p.inpainting_fill = 1
|
||||
p.inpaint_full_res = 0
|
||||
p.inpaint_full_res_padding = 32
|
||||
|
||||
p.init_images = [image]
|
||||
p.image_mask = mask
|
||||
|
||||
processed = processing.process_images(p)
|
||||
results = processed.images[0]
|
||||
image_name = output_dir + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
results.save(image_name)
|
||||
|
||||
def initialize_dlib_predictor(self):
|
||||
print("[INFO] Loading the predictor...")
|
||||
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,
|
||||
|
|
@ -158,7 +94,7 @@ class Wav2LipUHQ:
|
|||
def dilate_mouth(self, mouth, w, h):
|
||||
mask = np.zeros((w, h), dtype=np.uint8)
|
||||
cv2.fillPoly(mask, [mouth], 255)
|
||||
kernel = np.ones((10, 10), np.uint8)
|
||||
kernel = np.ones((self.mouth_mask_dilatation, self.mouth_mask_dilatation), np.uint8)
|
||||
dilated_mask = cv2.dilate(mask, kernel, iterations=1)
|
||||
contours, _ = cv2.findContours(dilated_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
dilated_points = contours[0].squeeze()
|
||||
|
|
@ -166,10 +102,8 @@ class Wav2LipUHQ:
|
|||
|
||||
def execute(self):
|
||||
output_dir = self.wav2lip_folder + '/output/'
|
||||
image_path = output_dir + "images/"
|
||||
mask_path = output_dir + "masks/"
|
||||
debug_path = output_dir + "debug/"
|
||||
|
||||
final_path = self.wav2lip_folder + '/output/final/'
|
||||
detector, predictor = self.initialize_dlib_predictor()
|
||||
vs, vi = self.initialize_video_streams()
|
||||
(mstart, mend) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
|
||||
|
|
@ -180,8 +114,11 @@ class Wav2LipUHQ:
|
|||
frame_number = 0
|
||||
|
||||
while True:
|
||||
print("Processing frame: " + str(frame_number) + " of " + max_frame + " - ")
|
||||
print("[INFO] Processing frame: " + str(frame_number) + " of " + max_frame + " - ", end="\r")
|
||||
if state.interrupted:
|
||||
break
|
||||
|
||||
# Read frame
|
||||
ret, w2l_frame = vs.read()
|
||||
if not ret:
|
||||
break
|
||||
|
|
@ -192,74 +129,121 @@ class Wav2LipUHQ:
|
|||
vi.set(cv2.CAP_PROP_POS_FRAMES, (frame_number % int(vi.get(cv2.CAP_PROP_FRAME_COUNT))) - 1)
|
||||
ret, original_frame = vi.read()
|
||||
|
||||
# Convert to gray
|
||||
w2l_gray = cv2.cvtColor(w2l_frame, cv2.COLOR_RGB2GRAY)
|
||||
original_gray = cv2.cvtColor(original_frame, cv2.COLOR_RGB2GRAY)
|
||||
if w2l_gray.shape != original_gray.shape:
|
||||
w2l_gray = cv2.resize(w2l_gray, (original_gray.shape[1], original_gray.shape[0]))
|
||||
w2l_frame = cv2.resize(w2l_frame, (original_gray.shape[1], original_gray.shape[0]))
|
||||
if self.resize_factor > 1:
|
||||
original_gray = cv2.resize(original_gray, (w2l_gray.shape[1], w2l_gray.shape[0]))
|
||||
original_frame = cv2.resize(original_frame, (w2l_gray.shape[1], w2l_gray.shape[0]))
|
||||
else:
|
||||
w2l_gray = cv2.resize(w2l_gray, (original_gray.shape[1], original_gray.shape[0]))
|
||||
w2l_frame = cv2.resize(w2l_frame, (original_gray.shape[1], original_gray.shape[0]))
|
||||
|
||||
# Calculate diff between frames and apply threshold
|
||||
diff = np.abs(original_gray - w2l_gray)
|
||||
diff[diff > 10] = 255
|
||||
diff[diff <= 10] = 0
|
||||
cv2.imwrite(debug_path + "diff_" + str(frame_number) + ".png", diff)
|
||||
|
||||
# Detect faces
|
||||
rects = detector.get_detections_for_batch(np.array([np.array(w2l_frame)]))
|
||||
|
||||
# Initialize mask
|
||||
mask = np.zeros_like(diff)
|
||||
|
||||
# Process each detected face
|
||||
for (i, rect) in enumerate(rects):
|
||||
# copy pixel from diff to mask where pixel is in rects
|
||||
shape = predictor(original_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
jaw = shape[jstart:jend][1:-1]
|
||||
nose = shape[nstart:nend][2]
|
||||
# Get face coordinates
|
||||
if not self.only_mouth:
|
||||
shape = predictor(original_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
jaw = shape[jstart:jend][1:-1]
|
||||
nose = shape[nstart:nend][2]
|
||||
|
||||
# Get mouth coordinates
|
||||
shape = predictor(w2l_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
mouth = shape[mstart:mend][:-8]
|
||||
mouth = np.delete(mouth, [3], axis=0)
|
||||
mouth = self.dilate_mouth(mouth, original_gray.shape[0], original_gray.shape[1])
|
||||
# affiche les points sur un clone de l'image
|
||||
clone = w2l_frame.copy()
|
||||
for (x, y) in np.concatenate((jaw, mouth, [nose])):
|
||||
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
|
||||
cv2.imwrite(debug_path + "points_" + str(frame_number) + ".png", clone)
|
||||
if self.mouth_mask_dilatation > 0:
|
||||
mouth = self.dilate_mouth(mouth, original_gray.shape[0], original_gray.shape[1])
|
||||
|
||||
external_shape = np.append(jaw, [nose], axis=0)
|
||||
kernel = np.ones((3, 3), np.uint8)
|
||||
external_shape_pts = external_shape.reshape((-1, 1, 2))
|
||||
mask = cv2.fillPoly(mask, [external_shape_pts], 255)
|
||||
mask = cv2.erode(mask, kernel, iterations=5)
|
||||
masked_diff = cv2.bitwise_and(diff, diff, mask=mask)
|
||||
# Create mask for face
|
||||
if not self.only_mouth:
|
||||
external_shape = np.append(jaw, [nose], axis=0)
|
||||
external_shape_pts = external_shape.reshape((-1, 1, 2))
|
||||
mask = cv2.fillPoly(mask, [external_shape_pts], 255)
|
||||
if self.erode_face_mask > 0:
|
||||
kernel = np.ones((self.erode_face_mask, self.erode_face_mask), np.uint8)
|
||||
mask = cv2.erode(mask, kernel, iterations=1)
|
||||
masked_diff = cv2.bitwise_and(diff, diff, mask=mask)
|
||||
else:
|
||||
masked_diff = mask
|
||||
|
||||
# Create mask for mouth
|
||||
cv2.fillConvexPoly(masked_diff, mouth, 255)
|
||||
masked_save = cv2.GaussianBlur(masked_diff, (15, 15), 0)
|
||||
|
||||
cv2.imwrite(mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png', masked_save)
|
||||
# Save mask
|
||||
if self.mask_blur > 0:
|
||||
blur = self.mask_blur if self.mask_blur % 2 == 1 else self.mask_blur - 1
|
||||
masked_save = cv2.GaussianBlur(masked_diff, (blur, blur), 0)
|
||||
else:
|
||||
masked_save = masked_diff
|
||||
|
||||
# Prepare for restoration
|
||||
masked_diff = np.uint8(masked_diff / 255)
|
||||
masked_diff = cv2.cvtColor(masked_diff, cv2.COLOR_GRAY2BGR)
|
||||
dst = w2l_frame * masked_diff
|
||||
cv2.imwrite(debug_path + "dst_" + str(frame_number) + ".png", dst)
|
||||
original = original_frame.copy()
|
||||
original_frame = original_frame * (1 - masked_diff) + dst
|
||||
|
||||
height, width, _ = original_frame.shape
|
||||
image_name = image_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
mask_name = mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
cv2.imwrite(image_name, original_frame)
|
||||
self.create_img(image_name, mask_name, (width, height), frame_number)
|
||||
# Restore face
|
||||
image_restored = modules.face_restoration.restore_faces(original_frame)
|
||||
|
||||
# Apply restored face to original image with mask attention
|
||||
extended_mask = np.stack([masked_save]*3, axis=-1)
|
||||
normalized_mask = extended_mask / 255.0
|
||||
dst2 = image_restored * normalized_mask
|
||||
original = original * (1 - normalized_mask) + dst2
|
||||
original = original.astype(np.uint8)
|
||||
|
||||
# Save final image
|
||||
cv2.imwrite(final_path + "output_" + str(frame_number).rjust(5, '0') + ".png", original)
|
||||
|
||||
if self.debug:
|
||||
clone = w2l_frame.copy()
|
||||
if not self.only_mouth:
|
||||
for (x, y) in np.concatenate((jaw, mouth, [nose])):
|
||||
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
|
||||
else:
|
||||
for (x, y) in mouth:
|
||||
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
|
||||
|
||||
f_number = str(frame_number).rjust(5, '0')
|
||||
cv2.imwrite(debug_path + "diff_" + f_number+ ".png", diff)
|
||||
cv2.imwrite(debug_path + "points_" + f_number + ".png", clone)
|
||||
cv2.imwrite(debug_path + 'mask_' + f_number + '.png', masked_save)
|
||||
cv2.imwrite(debug_path + "dst_" + f_number + ".png", dst)
|
||||
cv2.imwrite(debug_path + 'image_' + f_number + '.png', original_frame)
|
||||
cv2.imwrite(debug_path + "face_restore_" + f_number + ".png", image_restored)
|
||||
cv2.imwrite(debug_path + "dst2_" + f_number + ".png", dst2)
|
||||
|
||||
frame_number += 1
|
||||
|
||||
vs.release()
|
||||
if not self.original_is_image:
|
||||
vi.release()
|
||||
if not state.interrupted:
|
||||
vs.release()
|
||||
if not self.original_is_image:
|
||||
vi.release()
|
||||
|
||||
print("[INFO] Create Video output!")
|
||||
self.create_video_from_images(frame_number - 1)
|
||||
print("[INFO] Extract Audio from input!")
|
||||
self.extract_audio_from_video()
|
||||
print("[INFO] Add Audio to Video!")
|
||||
self.add_audio_to_video()
|
||||
|
||||
print("[INFO] Done! file save in output/video_output.mp4")
|
||||
print("[INFO] Create Video output!")
|
||||
self.create_video_from_images(frame_number - 1)
|
||||
print("[INFO] Extract Audio from input!")
|
||||
self.extract_audio_from_video()
|
||||
print("[INFO] Add Audio to Video!")
|
||||
self.add_audio_to_video()
|
||||
print("[INFO] Done! file save in output/video_output.mp4")
|
||||
return self.wav2lip_folder + "/output/output_video.mp4"
|
||||
else:
|
||||
print("[INFO] Interrupted!")
|
||||
return None
|
||||
|
|
|
|||
|
|
@ -1,15 +1,11 @@
|
|||
import os
|
||||
from modules import script_callbacks
|
||||
import modules.paths as ph
|
||||
from scripts.wav2lip_uhq_extend_paths import wav2lip_uhq_sys_extend
|
||||
|
||||
|
||||
def init_wav2lip_uhq():
|
||||
wav2lip_uhq_sys_extend()
|
||||
# import our on_ui_tabs and on_ui_settings functions from the respected files
|
||||
from ui import on_ui_tabs
|
||||
|
||||
# trigger webui's extensions mechanism using our imported main functions -
|
||||
# first to create the actual deforum gui, then to make the deforum tab in webui's settings section
|
||||
script_callbacks.on_ui_tabs(on_ui_tabs)
|
||||
|
||||
|
||||
init_wav2lip_uhq()
|
||||
|
|
|
|||
|
|
@ -1,6 +1,7 @@
|
|||
import os
|
||||
import sys
|
||||
|
||||
|
||||
def wav2lip_uhq_sys_extend():
|
||||
wav2lip_uhq_folder_name = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-2])
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue