Initialisation
parent
83695a793b
commit
4e688d3068
|
|
@ -0,0 +1,16 @@
|
|||
.idea/*
|
||||
demo/*
|
||||
**/__pycache__/
|
||||
scripts/wav2lip/checkpoints/wav2lip_gan.pth
|
||||
scripts/wav2lip/checkpoints/wav2lip.pth
|
||||
scripts/wav2lip/checkpoints/visual_quality_disc_.pth
|
||||
scripts/wav2lip/checkpoints/lipsync_expert_.pth
|
||||
scripts/wav2lip/face_detection/detection/sfd/s3fd.pth
|
||||
scripts/wav2lip/predicator/shape_predictor_68_face_landmarks.dat
|
||||
scripts/wav2lip/output/debug/*.png
|
||||
scripts/wav2lip/output/final/*.png
|
||||
scripts/wav2lip/output/images/*.png
|
||||
scripts/wav2lip/output/masks/*.png
|
||||
scripts/wav2lip/output/*.mp4
|
||||
scripts/wav2lip/output/*.aac
|
||||
scripts/wav2lip/results/result_voice.mp4
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
# Default ignored files
|
||||
/shelf/
|
||||
/workspace.xml
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
<component name="InspectionProjectProfileManager">
|
||||
<profile version="1.0">
|
||||
<option name="myName" value="Project Default" />
|
||||
<inspection_tool class="PyCompatibilityInspection" enabled="true" level="WARNING" enabled_by_default="true">
|
||||
<option name="ourVersions">
|
||||
<value>
|
||||
<list size="1">
|
||||
<item index="0" class="java.lang.String" itemvalue="3.9" />
|
||||
</list>
|
||||
</value>
|
||||
</option>
|
||||
</inspection_tool>
|
||||
<inspection_tool class="PyPep8NamingInspection" enabled="true" level="WEAK WARNING" enabled_by_default="true">
|
||||
<option name="ignoredErrors">
|
||||
<list>
|
||||
<option value="N806" />
|
||||
</list>
|
||||
</option>
|
||||
</inspection_tool>
|
||||
</profile>
|
||||
</component>
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
<component name="InspectionProjectProfileManager">
|
||||
<settings>
|
||||
<option name="USE_PROJECT_PROFILE" value="false" />
|
||||
<version value="1.0" />
|
||||
</settings>
|
||||
</component>
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="ProjectModuleManager">
|
||||
<modules>
|
||||
<module fileurl="file://$PROJECT_DIR$/.idea/sd-wav2lip-uhq.iml" filepath="$PROJECT_DIR$/.idea/sd-wav2lip-uhq.iml" />
|
||||
</modules>
|
||||
</component>
|
||||
</project>
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<module type="PYTHON_MODULE" version="4">
|
||||
<component name="NewModuleRootManager">
|
||||
<content url="file://$MODULE_DIR$" />
|
||||
<orderEntry type="inheritedJdk" />
|
||||
<orderEntry type="sourceFolder" forTests="false" />
|
||||
</component>
|
||||
<component name="PyDocumentationSettings">
|
||||
<option name="format" value="PLAIN" />
|
||||
<option name="myDocStringFormat" value="Plain" />
|
||||
</component>
|
||||
</module>
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="VcsDirectoryMappings">
|
||||
<mapping directory="$PROJECT_DIR$" vcs="Git" />
|
||||
</component>
|
||||
</project>
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
# Contributing to sd-wav2lip-uhq
|
||||
|
||||
Thank you for your interest in contributing to sd-wav2lip-uhq! We appreciate your effort and to help us incorporate your contribution in the best way possible, please follow the following contribution guidelines.
|
||||
|
||||
## Reporting Bugs
|
||||
|
||||
If you find a bug in the project, we encourage you to report it. Here's how:
|
||||
|
||||
1. First, check the [existing Issues](url_of_issues) to see if the issue has already been reported. If it has, please add a comment to the existing issue rather than creating a new one.
|
||||
2. If you can't find an existing issue that matches your bug, create a new issue. Make sure to include as many details as possible so we can understand and reproduce the problem.
|
||||
|
||||
## Proposing Changes
|
||||
|
||||
We welcome code contributions from the community. Here's how to propose changes:
|
||||
|
||||
1. Fork this repository to your own GitHub account.
|
||||
2. Create a new branch on your fork for your changes.
|
||||
3. Make your changes in this branch.
|
||||
4. When you are ready, submit a pull request to the `main` branch of this repository.
|
||||
|
||||
Please note that we use the GitHub Flow workflow, so all pull requests should be made to the `main` branch.
|
||||
|
||||
Before submitting a pull request, please make sure your code adheres to the project's coding conventions and it has passed all tests. If you are adding features, please also add appropriate tests.
|
||||
|
||||
## Contact
|
||||
|
||||
If you have any questions or need help, please ping the developer via email at numzzz@hotmail.com to make sure your addition will fit well into such a large project and to get help if needed.
|
||||
|
||||
Thank you again for your contribution!
|
||||
|
|
@ -0,0 +1,202 @@
|
|||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright 2023 NumZ
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
81
README.md
81
README.md
|
|
@ -1,2 +1,79 @@
|
|||
# sd-wav2lip-uhq
|
||||
Wav2Lip UHQ extension for Automatic1111
|
||||
# Wav2Lip UHQ Improvement extension for Stable diffusion webui automatic1111
|
||||
|
||||
|
||||

|
||||
|
||||
Result video can be find here : https://www.youtube.com/watch?v=-3WLUxz6XKM
|
||||
|
||||
https://user-images.githubusercontent.com/800903/258114796-c3962b79-b07e-4399-9046-665b9090ef6a.mp4
|
||||
|
||||
## Description
|
||||
This repository contains an extension for Automatic1111 designed to enhance videos generated by the [Wav2Lip tool](https://github.com/Rudrabha/Wav2Lip) with stable diffusion.
|
||||
It improves the quality of the lip-sync videos by applying specific post-processing techniques with Stable diffusion.
|
||||
|
||||

|
||||
|
||||
## Requirements
|
||||
- latest version of Stable diffusion webui automatic1111
|
||||
- FFmpeg
|
||||
|
||||
1. You can install Stable Diffusion Webui by following the instructions on the [Stable Diffusion Webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) repository.
|
||||
2. FFmpeg : download it from the [official FFmpeg site](https://ffmpeg.org/download.html). Follow the instructions appropriate for your operating system, note ffmpeg have to be accessible from the command line.
|
||||
|
||||
## Installation
|
||||
|
||||
1. Launch automatic1111
|
||||
2. go to extensions tab enter the following url in the "Install from URL" field and click "Install":
|
||||
|
||||
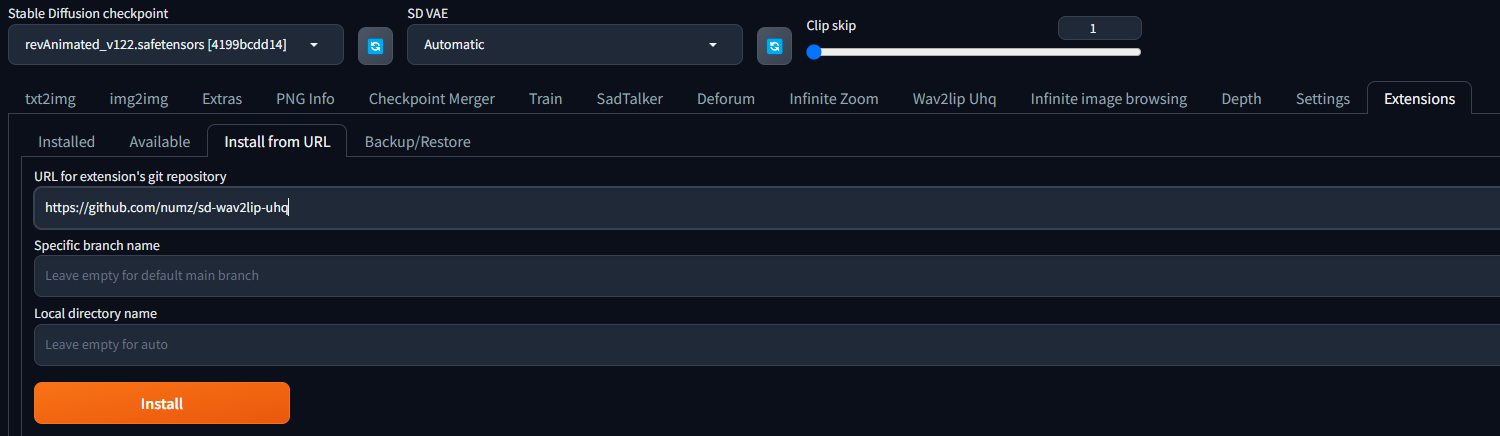
|
||||
|
||||
3. go to Installed Tab in extensions tab and click "Apply and quit"
|
||||
|
||||

|
||||
|
||||
5. Restart automatic1111
|
||||
|
||||
6. 🔥 Getting the weights IMPORTANT :
|
||||
|
||||
| Model | Description | Link to the model | install folder |
|
||||
|:-------------------:|:----------------------------------------------------------------------------------:| :---------------: |:------------------------------------------------------------------------------------------:|
|
||||
| Wav2Lip | Highly accurate lip-sync | [Link](https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/Eb3LEzbfuKlJiR600lQWRxgBIY27JZg80f7V9jtMfbNDaQ?e=TBFBVW) | extensions\sd-wav2lip-uhq\wav2lip\scripts\checkpoints\ |
|
||||
| Wav2Lip + GAN | Slightly inferior lip-sync, but better visual quality | [Link](https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/EdjI7bZlgApMqsVoEUUXpLsBxqXbn5z8VTmoxp55YNDcIA?e=n9ljGW) | extensions\sd-wav2lip-uhq\wav2lip\scripts\checkpoints\ |
|
||||
| s3fd | Face Detection pre trained model | [Link](ttps://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth) | extensions\sd-wav2lip-uhq\scripts\wav2lip\face_detection\detection\sfd\s3fd.pth |
|
||||
| s3fd | Face Detection pre trained model (alternate link) | [Link](https://iiitaphyd-my.sharepoint.com/:u:/g/personal/prajwal_k_research_iiit_ac_in/EZsy6qWuivtDnANIG73iHjIBjMSoojcIV0NULXV-yiuiIg?e=qTasa8) | extensions\sd-wav2lip-uhq\scripts\wav2lip\face_detection\detection\sfd\s3fd.pth |
|
||||
| landmark predicator | Dlib 68 point face landmark prediction | [Link](https://huggingface.co/spaces/asdasdasdasd/Face-forgery-detection/resolve/ccfc24642e0210d4d885bc7b3dbc9a68ed948ad6/shape_predictor_68_face_landmarks.dat) | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
|
||||
| landmark predicator | Dlib 68 point face landmark prediction (alternate link click on the download icon) | [Link](https://github.com/italojs/facial-landmarks-recognition/blob/master/shape_predictor_68_face_landmarks.dat) | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
|
||||
|
||||
|
||||
## Usage
|
||||
1. Choose a video or an image
|
||||
2. Choose an audio file with speech
|
||||
3. choose a checkpoint (see table above)
|
||||
4. **Padding** is use by wav2lip to add a black border around the mouth, it's usefull to avoid the mouth to be cropped by the face detection. you can change the padding value to your needs but default value give good results.
|
||||
5. **No Smooth**: if checked, the mouth will not be smoothed, it can be usefull if you want to keep the original mouth shape.
|
||||
6. **Resize Factor**: resize factor for the video, default value is 1.0, you can change it to your needs. Usefull if video size is too big.
|
||||
7. Choose a good Stable diffusion checkpoint, like [delibarate_v2](https://civitai.com/models/4823/deliberate) or [revAnimated_v122](https://civitai.com/models/7371) (SDXL models seems doesn't work).
|
||||
8. Click on "Generate" button
|
||||
|
||||
## Behind the scenes
|
||||
|
||||
This extension operates in several stages to improve the quality of Wav2Lip-generated videos:
|
||||
|
||||
1. **Generate a Wav2lip video**: The script first generates a low-quality Wav2Lip video using the input video and audio.
|
||||
2. **Mask Creation**: The script creates a mask around the mouth and try to keep other face motion like cheeks and chin.
|
||||
3. **Video Quality Enhancement**: It takes the low-quality Wav2Lip video and overlays the low-quality mouth onto the high-quality original video.
|
||||
4. **Img2Img**: The script then sends the original image with the low-quality mouth and the mouth mask into Img2Img.
|
||||
|
||||
## Quality tips
|
||||
- use a high quality video as input
|
||||
- use a high quality model in stable diffusion webui like [delibarate_v2](https://civitai.com/models/4823/deliberate) or [revAnimated_v122](https://civitai.com/models/7371)
|
||||
|
||||
## Contributing
|
||||
|
||||
Contributions to this project are welcome. Please ensure any pull requests are accompanied by a detailed description of the changes made.
|
||||
|
||||
## License
|
||||
* The code in this repository is released under the MIT license as found in the [LICENSE file](LICENSE).
|
||||
* The models weights in this repository are released under the CC-BY-NC 4.0 license as found in the [LICENSE_weights file](LICENSE_weights).
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,10 @@
|
|||
import launch
|
||||
import os
|
||||
|
||||
req_file = os.path.join(os.path.dirname(os.path.realpath(__file__)), "requirements.txt")
|
||||
|
||||
with open(req_file) as file:
|
||||
for lib in file:
|
||||
lib = lib.strip()
|
||||
if not launch.is_installed(lib):
|
||||
launch.run_pip(f"install {lib}", f"wav2lip_uhq requirement: {lib}")
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
imutils
|
||||
dlib
|
||||
numpy
|
||||
opencv-python
|
||||
scipy
|
||||
requests
|
||||
pillow
|
||||
librosa
|
||||
opencv-contrib-python
|
||||
tqdm
|
||||
numba
|
||||
imutils
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
from scripts.wav2lip_uhq_extend_paths import wav2lip_uhq_sys_extend
|
||||
import gradio as gr
|
||||
from scripts.wav2lip.w2l import W2l
|
||||
from scripts.wav2lip.wav2lip_uhq import Wav2LipUHQ
|
||||
from modules.shared import opts, state
|
||||
|
||||
def on_ui_tabs():
|
||||
wav2lip_uhq_sys_extend()
|
||||
|
||||
with gr.Blocks(analytics_enabled=False) as wav2lip_uhq_interface:
|
||||
with gr.Row():
|
||||
video = gr.File(label="Video or Image", info="Filepath of video/image that contains faces to use")
|
||||
audio = gr.File(label="Audio", info="Filepath of video/audio file to use as raw audio source")
|
||||
with gr.Column():
|
||||
checkpoint = gr.Radio(["wav2lip", "wav2lip_gan"], value="wav2lip_gan", label="Checkpoint", info="Name of saved checkpoint to load weights from")
|
||||
no_smooth = gr.Checkbox(label="No Smooth", info="Prevent smoothing face detections over a short temporal window")
|
||||
resize_factor = gr.Slider(minimum=1, maximum=4, step=1, label="Resize Factor", info="Reduce the resolution by this factor. Sometimes, best results are obtained at 480p or 720p")
|
||||
generate_btn = gr.Button("Generate")
|
||||
interrupt_btn = gr.Button('Interrupt', elem_id=f"interrupt", visible=True)
|
||||
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
pad_top = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Top", info="Padding above lips")
|
||||
pad_bottom = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Bottom", info="Padding below lips")
|
||||
pad_left = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Left", info="Padding to the left of lips")
|
||||
pad_right = gr.Slider(minimum=0, maximum=50, step=1, value=0, label="Pad Right", info="Padding to the right of lips")
|
||||
|
||||
with gr.Column():
|
||||
with gr.Tabs(elem_id="wav2lip_generated"):
|
||||
result = gr.Video(label="Generated video", format="mp4").style(width=256)
|
||||
|
||||
|
||||
def on_interrupt():
|
||||
state.interrupt()
|
||||
return "Interrupted"
|
||||
|
||||
def generate(video, audio, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right):
|
||||
state.begin()
|
||||
if video is None or audio is None or checkpoint is None:
|
||||
return
|
||||
w2l = W2l(video.name, audio.name, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right)
|
||||
w2l.execute()
|
||||
|
||||
w2luhq = Wav2LipUHQ(video.name, audio.name)
|
||||
w2luhq.execute()
|
||||
return "extensions\\sd-wav2lip-uhq\\scripts\\wav2lip\\output\\output_video.mp4"
|
||||
|
||||
generate_btn.click(
|
||||
generate,
|
||||
[video, audio, checkpoint, no_smooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right],
|
||||
result)
|
||||
|
||||
interrupt_btn.click(on_interrupt)
|
||||
|
||||
return [(wav2lip_uhq_interface, "Wav2lip Uhq", "wav2lip_uhq_interface")]
|
||||
|
|
@ -0,0 +1,136 @@
|
|||
import librosa
|
||||
import librosa.filters
|
||||
import numpy as np
|
||||
# import tensorflow as tf
|
||||
from scipy import signal
|
||||
from scipy.io import wavfile
|
||||
from scripts.wav2lip.hparams import hparams as hp
|
||||
|
||||
def load_wav(path, sr):
|
||||
return librosa.core.load(path, sr=sr)[0]
|
||||
|
||||
def save_wav(wav, path, sr):
|
||||
wav *= 32767 / max(0.01, np.max(np.abs(wav)))
|
||||
#proposed by @dsmiller
|
||||
wavfile.write(path, sr, wav.astype(np.int16))
|
||||
|
||||
def save_wavenet_wav(wav, path, sr):
|
||||
librosa.output.write_wav(path, wav, sr=sr)
|
||||
|
||||
def preemphasis(wav, k, preemphasize=True):
|
||||
if preemphasize:
|
||||
return signal.lfilter([1, -k], [1], wav)
|
||||
return wav
|
||||
|
||||
def inv_preemphasis(wav, k, inv_preemphasize=True):
|
||||
if inv_preemphasize:
|
||||
return signal.lfilter([1], [1, -k], wav)
|
||||
return wav
|
||||
|
||||
def get_hop_size():
|
||||
hop_size = hp.hop_size
|
||||
if hop_size is None:
|
||||
assert hp.frame_shift_ms is not None
|
||||
hop_size = int(hp.frame_shift_ms / 1000 * hp.sample_rate)
|
||||
return hop_size
|
||||
|
||||
def linearspectrogram(wav):
|
||||
D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize))
|
||||
S = _amp_to_db(np.abs(D)) - hp.ref_level_db
|
||||
|
||||
if hp.signal_normalization:
|
||||
return _normalize(S)
|
||||
return S
|
||||
|
||||
def melspectrogram(wav):
|
||||
D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize))
|
||||
S = _amp_to_db(_linear_to_mel(np.abs(D))) - hp.ref_level_db
|
||||
|
||||
if hp.signal_normalization:
|
||||
return _normalize(S)
|
||||
return S
|
||||
|
||||
def _lws_processor():
|
||||
import lws
|
||||
return lws.lws(hp.n_fft, get_hop_size(), fftsize=hp.win_size, mode="speech")
|
||||
|
||||
def _stft(y):
|
||||
if hp.use_lws:
|
||||
return _lws_processor(hp).stft(y).T
|
||||
else:
|
||||
return librosa.stft(y=y, n_fft=hp.n_fft, hop_length=get_hop_size(), win_length=hp.win_size)
|
||||
|
||||
##########################################################
|
||||
#Those are only correct when using lws!!! (This was messing with Wavenet quality for a long time!)
|
||||
def num_frames(length, fsize, fshift):
|
||||
"""Compute number of time frames of spectrogram
|
||||
"""
|
||||
pad = (fsize - fshift)
|
||||
if length % fshift == 0:
|
||||
M = (length + pad * 2 - fsize) // fshift + 1
|
||||
else:
|
||||
M = (length + pad * 2 - fsize) // fshift + 2
|
||||
return M
|
||||
|
||||
|
||||
def pad_lr(x, fsize, fshift):
|
||||
"""Compute left and right padding
|
||||
"""
|
||||
M = num_frames(len(x), fsize, fshift)
|
||||
pad = (fsize - fshift)
|
||||
T = len(x) + 2 * pad
|
||||
r = (M - 1) * fshift + fsize - T
|
||||
return pad, pad + r
|
||||
##########################################################
|
||||
#Librosa correct padding
|
||||
def librosa_pad_lr(x, fsize, fshift):
|
||||
return 0, (x.shape[0] // fshift + 1) * fshift - x.shape[0]
|
||||
|
||||
# Conversions
|
||||
_mel_basis = None
|
||||
|
||||
def _linear_to_mel(spectogram):
|
||||
global _mel_basis
|
||||
if _mel_basis is None:
|
||||
_mel_basis = _build_mel_basis()
|
||||
return np.dot(_mel_basis, spectogram)
|
||||
|
||||
def _build_mel_basis():
|
||||
assert hp.fmax <= hp.sample_rate // 2
|
||||
return librosa.filters.mel(hp.sample_rate, hp.n_fft, n_mels=hp.num_mels,
|
||||
fmin=hp.fmin, fmax=hp.fmax)
|
||||
|
||||
def _amp_to_db(x):
|
||||
min_level = np.exp(hp.min_level_db / 20 * np.log(10))
|
||||
return 20 * np.log10(np.maximum(min_level, x))
|
||||
|
||||
def _db_to_amp(x):
|
||||
return np.power(10.0, (x) * 0.05)
|
||||
|
||||
def _normalize(S):
|
||||
if hp.allow_clipping_in_normalization:
|
||||
if hp.symmetric_mels:
|
||||
return np.clip((2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value,
|
||||
-hp.max_abs_value, hp.max_abs_value)
|
||||
else:
|
||||
return np.clip(hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db)), 0, hp.max_abs_value)
|
||||
|
||||
assert S.max() <= 0 and S.min() - hp.min_level_db >= 0
|
||||
if hp.symmetric_mels:
|
||||
return (2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value
|
||||
else:
|
||||
return hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db))
|
||||
|
||||
def _denormalize(D):
|
||||
if hp.allow_clipping_in_normalization:
|
||||
if hp.symmetric_mels:
|
||||
return (((np.clip(D, -hp.max_abs_value,
|
||||
hp.max_abs_value) + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value))
|
||||
+ hp.min_level_db)
|
||||
else:
|
||||
return ((np.clip(D, 0, hp.max_abs_value) * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db)
|
||||
|
||||
if hp.symmetric_mels:
|
||||
return (((D + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value)) + hp.min_level_db)
|
||||
else:
|
||||
return ((D * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db)
|
||||
|
|
@ -0,0 +1 @@
|
|||
Place all your checkpoints (.pth files) here.
|
||||
|
|
@ -0,0 +1 @@
|
|||
The code for Face Detection in this folder has been taken from the wonderful [face_alignment](https://github.com/1adrianb/face-alignment) repository. This has been modified to take batches of faces at a time.
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
|
||||
__author__ = """Adrian Bulat"""
|
||||
__email__ = 'adrian.bulat@nottingham.ac.uk'
|
||||
__version__ = '1.0.1'
|
||||
|
||||
from .api import FaceAlignment, LandmarksType, NetworkSize
|
||||
|
|
@ -0,0 +1,79 @@
|
|||
from __future__ import print_function
|
||||
import os
|
||||
import torch
|
||||
from torch.utils.model_zoo import load_url
|
||||
from enum import Enum
|
||||
import numpy as np
|
||||
import cv2
|
||||
try:
|
||||
import urllib.request as request_file
|
||||
except BaseException:
|
||||
import urllib as request_file
|
||||
|
||||
from .models import FAN, ResNetDepth
|
||||
from .utils import *
|
||||
|
||||
|
||||
class LandmarksType(Enum):
|
||||
"""Enum class defining the type of landmarks to detect.
|
||||
|
||||
``_2D`` - the detected points ``(x,y)`` are detected in a 2D space and follow the visible contour of the face
|
||||
``_2halfD`` - this points represent the projection of the 3D points into 3D
|
||||
``_3D`` - detect the points ``(x,y,z)``` in a 3D space
|
||||
|
||||
"""
|
||||
_2D = 1
|
||||
_2halfD = 2
|
||||
_3D = 3
|
||||
|
||||
|
||||
class NetworkSize(Enum):
|
||||
# TINY = 1
|
||||
# SMALL = 2
|
||||
# MEDIUM = 3
|
||||
LARGE = 4
|
||||
|
||||
def __new__(cls, value):
|
||||
member = object.__new__(cls)
|
||||
member._value_ = value
|
||||
return member
|
||||
|
||||
def __int__(self):
|
||||
return self.value
|
||||
|
||||
ROOT = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
class FaceAlignment:
|
||||
def __init__(self, landmarks_type, network_size=NetworkSize.LARGE,
|
||||
device='cuda', flip_input=False, face_detector='sfd', verbose=False):
|
||||
self.device = device
|
||||
self.flip_input = flip_input
|
||||
self.landmarks_type = landmarks_type
|
||||
self.verbose = verbose
|
||||
|
||||
network_size = int(network_size)
|
||||
|
||||
if 'cuda' in device:
|
||||
torch.backends.cudnn.benchmark = True
|
||||
|
||||
# Get the face detector
|
||||
face_detector_module = __import__('scripts.wav2lip.face_detection.detection.' + face_detector,
|
||||
globals(), locals(), [face_detector], 0)
|
||||
self.face_detector = face_detector_module.FaceDetector(device=device, verbose=verbose)
|
||||
|
||||
def get_detections_for_batch(self, images):
|
||||
images = images[..., ::-1]
|
||||
detected_faces = self.face_detector.detect_from_batch(images.copy())
|
||||
results = []
|
||||
|
||||
for i, d in enumerate(detected_faces):
|
||||
if len(d) == 0:
|
||||
results.append(None)
|
||||
continue
|
||||
d = d[0]
|
||||
d = np.clip(d, 0, None)
|
||||
|
||||
x1, y1, x2, y2 = map(int, d[:-1])
|
||||
results.append((x1, y1, x2, y2))
|
||||
|
||||
return results
|
||||
|
|
@ -0,0 +1 @@
|
|||
from .core import FaceDetector
|
||||
|
|
@ -0,0 +1,130 @@
|
|||
import logging
|
||||
import glob
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
import torch
|
||||
import cv2
|
||||
|
||||
|
||||
class FaceDetector(object):
|
||||
"""An abstract class representing a face detector.
|
||||
|
||||
Any other face detection implementation must subclass it. All subclasses
|
||||
must implement ``detect_from_image``, that return a list of detected
|
||||
bounding boxes. Optionally, for speed considerations detect from path is
|
||||
recommended.
|
||||
"""
|
||||
|
||||
def __init__(self, device, verbose):
|
||||
self.device = device
|
||||
self.verbose = verbose
|
||||
|
||||
if verbose:
|
||||
if 'cpu' in device:
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.warning("Detection running on CPU, this may be potentially slow.")
|
||||
|
||||
if 'cpu' not in device and 'cuda' not in device:
|
||||
if verbose:
|
||||
logger.error("Expected values for device are: {cpu, cuda} but got: %s", device)
|
||||
raise ValueError
|
||||
|
||||
def detect_from_image(self, tensor_or_path):
|
||||
"""Detects faces in a given image.
|
||||
|
||||
This function detects the faces present in a provided BGR(usually)
|
||||
image. The input can be either the image itself or the path to it.
|
||||
|
||||
Arguments:
|
||||
tensor_or_path {numpy.ndarray, torch.tensor or string} -- the path
|
||||
to an image or the image itself.
|
||||
|
||||
Example::
|
||||
|
||||
>>> path_to_image = 'data/image_01.jpg'
|
||||
... detected_faces = detect_from_image(path_to_image)
|
||||
[A list of bounding boxes (x1, y1, x2, y2)]
|
||||
>>> image = cv2.imread(path_to_image)
|
||||
... detected_faces = detect_from_image(image)
|
||||
[A list of bounding boxes (x1, y1, x2, y2)]
|
||||
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
def detect_from_directory(self, path, extensions=['.jpg', '.png'], recursive=False, show_progress_bar=True):
|
||||
"""Detects faces from all the images present in a given directory.
|
||||
|
||||
Arguments:
|
||||
path {string} -- a string containing a path that points to the folder containing the images
|
||||
|
||||
Keyword Arguments:
|
||||
extensions {list} -- list of string containing the extensions to be
|
||||
consider in the following format: ``.extension_name`` (default:
|
||||
{['.jpg', '.png']}) recursive {bool} -- option wherever to scan the
|
||||
folder recursively (default: {False}) show_progress_bar {bool} --
|
||||
display a progressbar (default: {True})
|
||||
|
||||
Example:
|
||||
>>> directory = 'data'
|
||||
... detected_faces = detect_from_directory(directory)
|
||||
{A dictionary of [lists containing bounding boxes(x1, y1, x2, y2)]}
|
||||
|
||||
"""
|
||||
if self.verbose:
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
if len(extensions) == 0:
|
||||
if self.verbose:
|
||||
logger.error("Expected at list one extension, but none was received.")
|
||||
raise ValueError
|
||||
|
||||
if self.verbose:
|
||||
logger.info("Constructing the list of images.")
|
||||
additional_pattern = '/**/*' if recursive else '/*'
|
||||
files = []
|
||||
for extension in extensions:
|
||||
files.extend(glob.glob(path + additional_pattern + extension, recursive=recursive))
|
||||
|
||||
if self.verbose:
|
||||
logger.info("Finished searching for images. %s images found", len(files))
|
||||
logger.info("Preparing to run the detection.")
|
||||
|
||||
predictions = {}
|
||||
for image_path in tqdm(files, disable=not show_progress_bar):
|
||||
if self.verbose:
|
||||
logger.info("Running the face detector on image: %s", image_path)
|
||||
predictions[image_path] = self.detect_from_image(image_path)
|
||||
|
||||
if self.verbose:
|
||||
logger.info("The detector was successfully run on all %s images", len(files))
|
||||
|
||||
return predictions
|
||||
|
||||
@property
|
||||
def reference_scale(self):
|
||||
raise NotImplementedError
|
||||
|
||||
@property
|
||||
def reference_x_shift(self):
|
||||
raise NotImplementedError
|
||||
|
||||
@property
|
||||
def reference_y_shift(self):
|
||||
raise NotImplementedError
|
||||
|
||||
@staticmethod
|
||||
def tensor_or_path_to_ndarray(tensor_or_path, rgb=True):
|
||||
"""Convert path (represented as a string) or torch.tensor to a numpy.ndarray
|
||||
|
||||
Arguments:
|
||||
tensor_or_path {numpy.ndarray, torch.tensor or string} -- path to the image, or the image itself
|
||||
"""
|
||||
if isinstance(tensor_or_path, str):
|
||||
return cv2.imread(tensor_or_path) if not rgb else cv2.imread(tensor_or_path)[..., ::-1]
|
||||
elif torch.is_tensor(tensor_or_path):
|
||||
# Call cpu in case its coming from cuda
|
||||
return tensor_or_path.cpu().numpy()[..., ::-1].copy() if not rgb else tensor_or_path.cpu().numpy()
|
||||
elif isinstance(tensor_or_path, np.ndarray):
|
||||
return tensor_or_path[..., ::-1].copy() if not rgb else tensor_or_path
|
||||
else:
|
||||
raise TypeError
|
||||
|
|
@ -0,0 +1 @@
|
|||
from .sfd_detector import SFDDetector as FaceDetector
|
||||
|
|
@ -0,0 +1,129 @@
|
|||
from __future__ import print_function
|
||||
import os
|
||||
import sys
|
||||
import cv2
|
||||
import random
|
||||
import datetime
|
||||
import time
|
||||
import math
|
||||
import argparse
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
try:
|
||||
from iou import IOU
|
||||
except BaseException:
|
||||
# IOU cython speedup 10x
|
||||
def IOU(ax1, ay1, ax2, ay2, bx1, by1, bx2, by2):
|
||||
sa = abs((ax2 - ax1) * (ay2 - ay1))
|
||||
sb = abs((bx2 - bx1) * (by2 - by1))
|
||||
x1, y1 = max(ax1, bx1), max(ay1, by1)
|
||||
x2, y2 = min(ax2, bx2), min(ay2, by2)
|
||||
w = x2 - x1
|
||||
h = y2 - y1
|
||||
if w < 0 or h < 0:
|
||||
return 0.0
|
||||
else:
|
||||
return 1.0 * w * h / (sa + sb - w * h)
|
||||
|
||||
|
||||
def bboxlog(x1, y1, x2, y2, axc, ayc, aww, ahh):
|
||||
xc, yc, ww, hh = (x2 + x1) / 2, (y2 + y1) / 2, x2 - x1, y2 - y1
|
||||
dx, dy = (xc - axc) / aww, (yc - ayc) / ahh
|
||||
dw, dh = math.log(ww / aww), math.log(hh / ahh)
|
||||
return dx, dy, dw, dh
|
||||
|
||||
|
||||
def bboxloginv(dx, dy, dw, dh, axc, ayc, aww, ahh):
|
||||
xc, yc = dx * aww + axc, dy * ahh + ayc
|
||||
ww, hh = math.exp(dw) * aww, math.exp(dh) * ahh
|
||||
x1, x2, y1, y2 = xc - ww / 2, xc + ww / 2, yc - hh / 2, yc + hh / 2
|
||||
return x1, y1, x2, y2
|
||||
|
||||
|
||||
def nms(dets, thresh):
|
||||
if 0 == len(dets):
|
||||
return []
|
||||
x1, y1, x2, y2, scores = dets[:, 0], dets[:, 1], dets[:, 2], dets[:, 3], dets[:, 4]
|
||||
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
||||
order = scores.argsort()[::-1]
|
||||
|
||||
keep = []
|
||||
while order.size > 0:
|
||||
i = order[0]
|
||||
keep.append(i)
|
||||
xx1, yy1 = np.maximum(x1[i], x1[order[1:]]), np.maximum(y1[i], y1[order[1:]])
|
||||
xx2, yy2 = np.minimum(x2[i], x2[order[1:]]), np.minimum(y2[i], y2[order[1:]])
|
||||
|
||||
w, h = np.maximum(0.0, xx2 - xx1 + 1), np.maximum(0.0, yy2 - yy1 + 1)
|
||||
ovr = w * h / (areas[i] + areas[order[1:]] - w * h)
|
||||
|
||||
inds = np.where(ovr <= thresh)[0]
|
||||
order = order[inds + 1]
|
||||
|
||||
return keep
|
||||
|
||||
|
||||
def encode(matched, priors, variances):
|
||||
"""Encode the variances from the priorbox layers into the ground truth boxes
|
||||
we have matched (based on jaccard overlap) with the prior boxes.
|
||||
Args:
|
||||
matched: (tensor) Coords of ground truth for each prior in point-form
|
||||
Shape: [num_priors, 4].
|
||||
priors: (tensor) Prior boxes in center-offset form
|
||||
Shape: [num_priors,4].
|
||||
variances: (list[float]) Variances of priorboxes
|
||||
Return:
|
||||
encoded boxes (tensor), Shape: [num_priors, 4]
|
||||
"""
|
||||
|
||||
# dist b/t match center and prior's center
|
||||
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
|
||||
# encode variance
|
||||
g_cxcy /= (variances[0] * priors[:, 2:])
|
||||
# match wh / prior wh
|
||||
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
|
||||
g_wh = torch.log(g_wh) / variances[1]
|
||||
# return target for smooth_l1_loss
|
||||
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
|
||||
|
||||
|
||||
def decode(loc, priors, variances):
|
||||
"""Decode locations from predictions using priors to undo
|
||||
the encoding we did for offset regression at train time.
|
||||
Args:
|
||||
loc (tensor): location predictions for loc layers,
|
||||
Shape: [num_priors,4]
|
||||
priors (tensor): Prior boxes in center-offset form.
|
||||
Shape: [num_priors,4].
|
||||
variances: (list[float]) Variances of priorboxes
|
||||
Return:
|
||||
decoded bounding box predictions
|
||||
"""
|
||||
|
||||
boxes = torch.cat((
|
||||
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
|
||||
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
|
||||
boxes[:, :2] -= boxes[:, 2:] / 2
|
||||
boxes[:, 2:] += boxes[:, :2]
|
||||
return boxes
|
||||
|
||||
def batch_decode(loc, priors, variances):
|
||||
"""Decode locations from predictions using priors to undo
|
||||
the encoding we did for offset regression at train time.
|
||||
Args:
|
||||
loc (tensor): location predictions for loc layers,
|
||||
Shape: [num_priors,4]
|
||||
priors (tensor): Prior boxes in center-offset form.
|
||||
Shape: [num_priors,4].
|
||||
variances: (list[float]) Variances of priorboxes
|
||||
Return:
|
||||
decoded bounding box predictions
|
||||
"""
|
||||
|
||||
boxes = torch.cat((
|
||||
priors[:, :, :2] + loc[:, :, :2] * variances[0] * priors[:, :, 2:],
|
||||
priors[:, :, 2:] * torch.exp(loc[:, :, 2:] * variances[1])), 2)
|
||||
boxes[:, :, :2] -= boxes[:, :, 2:] / 2
|
||||
boxes[:, :, 2:] += boxes[:, :, :2]
|
||||
return boxes
|
||||
|
|
@ -0,0 +1,112 @@
|
|||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
import os
|
||||
import sys
|
||||
import cv2
|
||||
import random
|
||||
import datetime
|
||||
import math
|
||||
import argparse
|
||||
import numpy as np
|
||||
|
||||
import scipy.io as sio
|
||||
import zipfile
|
||||
from .net_s3fd import s3fd
|
||||
from .bbox import *
|
||||
|
||||
|
||||
def detect(net, img, device):
|
||||
img = img - np.array([104, 117, 123])
|
||||
img = img.transpose(2, 0, 1)
|
||||
img = img.reshape((1,) + img.shape)
|
||||
|
||||
if 'cuda' in device:
|
||||
torch.backends.cudnn.benchmark = True
|
||||
|
||||
img = torch.from_numpy(img).float().to(device)
|
||||
BB, CC, HH, WW = img.size()
|
||||
with torch.no_grad():
|
||||
olist = net(img)
|
||||
|
||||
bboxlist = []
|
||||
for i in range(len(olist) // 2):
|
||||
olist[i * 2] = F.softmax(olist[i * 2], dim=1)
|
||||
olist = [oelem.data.cpu() for oelem in olist]
|
||||
for i in range(len(olist) // 2):
|
||||
ocls, oreg = olist[i * 2], olist[i * 2 + 1]
|
||||
FB, FC, FH, FW = ocls.size() # feature map size
|
||||
stride = 2**(i + 2) # 4,8,16,32,64,128
|
||||
anchor = stride * 4
|
||||
poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
|
||||
for Iindex, hindex, windex in poss:
|
||||
axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
|
||||
score = ocls[0, 1, hindex, windex]
|
||||
loc = oreg[0, :, hindex, windex].contiguous().view(1, 4)
|
||||
priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]])
|
||||
variances = [0.1, 0.2]
|
||||
box = decode(loc, priors, variances)
|
||||
x1, y1, x2, y2 = box[0] * 1.0
|
||||
# cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
|
||||
bboxlist.append([x1, y1, x2, y2, score])
|
||||
bboxlist = np.array(bboxlist)
|
||||
if 0 == len(bboxlist):
|
||||
bboxlist = np.zeros((1, 5))
|
||||
|
||||
return bboxlist
|
||||
|
||||
def batch_detect(net, imgs, device):
|
||||
imgs = imgs - np.array([104, 117, 123])
|
||||
imgs = imgs.transpose(0, 3, 1, 2)
|
||||
|
||||
if 'cuda' in device:
|
||||
torch.backends.cudnn.benchmark = True
|
||||
|
||||
imgs = torch.from_numpy(imgs).float().to(device)
|
||||
BB, CC, HH, WW = imgs.size()
|
||||
with torch.no_grad():
|
||||
olist = net(imgs)
|
||||
|
||||
bboxlist = []
|
||||
for i in range(len(olist) // 2):
|
||||
olist[i * 2] = F.softmax(olist[i * 2], dim=1)
|
||||
olist = [oelem.data.cpu() for oelem in olist]
|
||||
for i in range(len(olist) // 2):
|
||||
ocls, oreg = olist[i * 2], olist[i * 2 + 1]
|
||||
FB, FC, FH, FW = ocls.size() # feature map size
|
||||
stride = 2**(i + 2) # 4,8,16,32,64,128
|
||||
anchor = stride * 4
|
||||
poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
|
||||
for Iindex, hindex, windex in poss:
|
||||
axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
|
||||
score = ocls[:, 1, hindex, windex]
|
||||
loc = oreg[:, :, hindex, windex].contiguous().view(BB, 1, 4)
|
||||
priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]]).view(1, 1, 4)
|
||||
variances = [0.1, 0.2]
|
||||
box = batch_decode(loc, priors, variances)
|
||||
box = box[:, 0] * 1.0
|
||||
# cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
|
||||
bboxlist.append(torch.cat([box, score.unsqueeze(1)], 1).cpu().numpy())
|
||||
bboxlist = np.array(bboxlist)
|
||||
if 0 == len(bboxlist):
|
||||
bboxlist = np.zeros((1, BB, 5))
|
||||
|
||||
return bboxlist
|
||||
|
||||
def flip_detect(net, img, device):
|
||||
img = cv2.flip(img, 1)
|
||||
b = detect(net, img, device)
|
||||
|
||||
bboxlist = np.zeros(b.shape)
|
||||
bboxlist[:, 0] = img.shape[1] - b[:, 2]
|
||||
bboxlist[:, 1] = b[:, 1]
|
||||
bboxlist[:, 2] = img.shape[1] - b[:, 0]
|
||||
bboxlist[:, 3] = b[:, 3]
|
||||
bboxlist[:, 4] = b[:, 4]
|
||||
return bboxlist
|
||||
|
||||
|
||||
def pts_to_bb(pts):
|
||||
min_x, min_y = np.min(pts, axis=0)
|
||||
max_x, max_y = np.max(pts, axis=0)
|
||||
return np.array([min_x, min_y, max_x, max_y])
|
||||
|
|
@ -0,0 +1,129 @@
|
|||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class L2Norm(nn.Module):
|
||||
def __init__(self, n_channels, scale=1.0):
|
||||
super(L2Norm, self).__init__()
|
||||
self.n_channels = n_channels
|
||||
self.scale = scale
|
||||
self.eps = 1e-10
|
||||
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
|
||||
self.weight.data *= 0.0
|
||||
self.weight.data += self.scale
|
||||
|
||||
def forward(self, x):
|
||||
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() + self.eps
|
||||
x = x / norm * self.weight.view(1, -1, 1, 1)
|
||||
return x
|
||||
|
||||
|
||||
class s3fd(nn.Module):
|
||||
def __init__(self):
|
||||
super(s3fd, self).__init__()
|
||||
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
|
||||
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
|
||||
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
|
||||
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
|
||||
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
|
||||
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
||||
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
||||
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
||||
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.fc6 = nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=3)
|
||||
self.fc7 = nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
self.conv6_1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
|
||||
self.conv6_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)
|
||||
|
||||
self.conv7_1 = nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0)
|
||||
self.conv7_2 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)
|
||||
|
||||
self.conv3_3_norm = L2Norm(256, scale=10)
|
||||
self.conv4_3_norm = L2Norm(512, scale=8)
|
||||
self.conv5_3_norm = L2Norm(512, scale=5)
|
||||
|
||||
self.conv3_3_norm_mbox_conf = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
||||
self.conv3_3_norm_mbox_loc = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
||||
self.conv4_3_norm_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
||||
self.conv4_3_norm_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
||||
self.conv5_3_norm_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
||||
self.conv5_3_norm_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.fc7_mbox_conf = nn.Conv2d(1024, 2, kernel_size=3, stride=1, padding=1)
|
||||
self.fc7_mbox_loc = nn.Conv2d(1024, 4, kernel_size=3, stride=1, padding=1)
|
||||
self.conv6_2_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
||||
self.conv6_2_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
||||
self.conv7_2_mbox_conf = nn.Conv2d(256, 2, kernel_size=3, stride=1, padding=1)
|
||||
self.conv7_2_mbox_loc = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
h = F.relu(self.conv1_1(x))
|
||||
h = F.relu(self.conv1_2(h))
|
||||
h = F.max_pool2d(h, 2, 2)
|
||||
|
||||
h = F.relu(self.conv2_1(h))
|
||||
h = F.relu(self.conv2_2(h))
|
||||
h = F.max_pool2d(h, 2, 2)
|
||||
|
||||
h = F.relu(self.conv3_1(h))
|
||||
h = F.relu(self.conv3_2(h))
|
||||
h = F.relu(self.conv3_3(h))
|
||||
f3_3 = h
|
||||
h = F.max_pool2d(h, 2, 2)
|
||||
|
||||
h = F.relu(self.conv4_1(h))
|
||||
h = F.relu(self.conv4_2(h))
|
||||
h = F.relu(self.conv4_3(h))
|
||||
f4_3 = h
|
||||
h = F.max_pool2d(h, 2, 2)
|
||||
|
||||
h = F.relu(self.conv5_1(h))
|
||||
h = F.relu(self.conv5_2(h))
|
||||
h = F.relu(self.conv5_3(h))
|
||||
f5_3 = h
|
||||
h = F.max_pool2d(h, 2, 2)
|
||||
|
||||
h = F.relu(self.fc6(h))
|
||||
h = F.relu(self.fc7(h))
|
||||
ffc7 = h
|
||||
h = F.relu(self.conv6_1(h))
|
||||
h = F.relu(self.conv6_2(h))
|
||||
f6_2 = h
|
||||
h = F.relu(self.conv7_1(h))
|
||||
h = F.relu(self.conv7_2(h))
|
||||
f7_2 = h
|
||||
|
||||
f3_3 = self.conv3_3_norm(f3_3)
|
||||
f4_3 = self.conv4_3_norm(f4_3)
|
||||
f5_3 = self.conv5_3_norm(f5_3)
|
||||
|
||||
cls1 = self.conv3_3_norm_mbox_conf(f3_3)
|
||||
reg1 = self.conv3_3_norm_mbox_loc(f3_3)
|
||||
cls2 = self.conv4_3_norm_mbox_conf(f4_3)
|
||||
reg2 = self.conv4_3_norm_mbox_loc(f4_3)
|
||||
cls3 = self.conv5_3_norm_mbox_conf(f5_3)
|
||||
reg3 = self.conv5_3_norm_mbox_loc(f5_3)
|
||||
cls4 = self.fc7_mbox_conf(ffc7)
|
||||
reg4 = self.fc7_mbox_loc(ffc7)
|
||||
cls5 = self.conv6_2_mbox_conf(f6_2)
|
||||
reg5 = self.conv6_2_mbox_loc(f6_2)
|
||||
cls6 = self.conv7_2_mbox_conf(f7_2)
|
||||
reg6 = self.conv7_2_mbox_loc(f7_2)
|
||||
|
||||
# max-out background label
|
||||
chunk = torch.chunk(cls1, 4, 1)
|
||||
bmax = torch.max(torch.max(chunk[0], chunk[1]), chunk[2])
|
||||
cls1 = torch.cat([bmax, chunk[3]], dim=1)
|
||||
|
||||
return [cls1, reg1, cls2, reg2, cls3, reg3, cls4, reg4, cls5, reg5, cls6, reg6]
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
import os
|
||||
import cv2
|
||||
from torch.utils.model_zoo import load_url
|
||||
import modules.shared as shared
|
||||
from ..core import FaceDetector
|
||||
|
||||
from .net_s3fd import s3fd
|
||||
from .bbox import *
|
||||
from .detect import *
|
||||
|
||||
models_urls = {
|
||||
's3fd': 'https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth',
|
||||
}
|
||||
|
||||
|
||||
class SFDDetector(FaceDetector):
|
||||
def __init__(self, device, path_to_detector=os.path.join(os.path.dirname(os.path.abspath(__file__)), 's3fd.pth'), verbose=False):
|
||||
super(SFDDetector, self).__init__(device, verbose)
|
||||
shared.cmd_opts.disable_safe_unpickle = True
|
||||
# Initialise the face detector
|
||||
if not os.path.isfile(path_to_detector):
|
||||
model_weights = load_url(models_urls['s3fd'])
|
||||
else:
|
||||
model_weights = torch.load(path_to_detector)
|
||||
|
||||
self.face_detector = s3fd()
|
||||
self.face_detector.load_state_dict(model_weights)
|
||||
self.face_detector.to(device)
|
||||
self.face_detector.eval()
|
||||
shared.cmd_opts.disable_safe_unpickle = False
|
||||
|
||||
def detect_from_image(self, tensor_or_path):
|
||||
image = self.tensor_or_path_to_ndarray(tensor_or_path)
|
||||
|
||||
bboxlist = detect(self.face_detector, image, device=self.device)
|
||||
keep = nms(bboxlist, 0.3)
|
||||
bboxlist = bboxlist[keep, :]
|
||||
bboxlist = [x for x in bboxlist if x[-1] > 0.5]
|
||||
|
||||
return bboxlist
|
||||
|
||||
def detect_from_batch(self, images):
|
||||
bboxlists = batch_detect(self.face_detector, images, device=self.device)
|
||||
keeps = [nms(bboxlists[:, i, :], 0.3) for i in range(bboxlists.shape[1])]
|
||||
bboxlists = [bboxlists[keep, i, :] for i, keep in enumerate(keeps)]
|
||||
bboxlists = [[x for x in bboxlist if x[-1] > 0.5] for bboxlist in bboxlists]
|
||||
|
||||
return bboxlists
|
||||
|
||||
@property
|
||||
def reference_scale(self):
|
||||
return 195
|
||||
|
||||
@property
|
||||
def reference_x_shift(self):
|
||||
return 0
|
||||
|
||||
@property
|
||||
def reference_y_shift(self):
|
||||
return 0
|
||||
|
|
@ -0,0 +1,261 @@
|
|||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import math
|
||||
|
||||
|
||||
def conv3x3(in_planes, out_planes, strd=1, padding=1, bias=False):
|
||||
"3x3 convolution with padding"
|
||||
return nn.Conv2d(in_planes, out_planes, kernel_size=3,
|
||||
stride=strd, padding=padding, bias=bias)
|
||||
|
||||
|
||||
class ConvBlock(nn.Module):
|
||||
def __init__(self, in_planes, out_planes):
|
||||
super(ConvBlock, self).__init__()
|
||||
self.bn1 = nn.BatchNorm2d(in_planes)
|
||||
self.conv1 = conv3x3(in_planes, int(out_planes / 2))
|
||||
self.bn2 = nn.BatchNorm2d(int(out_planes / 2))
|
||||
self.conv2 = conv3x3(int(out_planes / 2), int(out_planes / 4))
|
||||
self.bn3 = nn.BatchNorm2d(int(out_planes / 4))
|
||||
self.conv3 = conv3x3(int(out_planes / 4), int(out_planes / 4))
|
||||
|
||||
if in_planes != out_planes:
|
||||
self.downsample = nn.Sequential(
|
||||
nn.BatchNorm2d(in_planes),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(in_planes, out_planes,
|
||||
kernel_size=1, stride=1, bias=False),
|
||||
)
|
||||
else:
|
||||
self.downsample = None
|
||||
|
||||
def forward(self, x):
|
||||
residual = x
|
||||
|
||||
out1 = self.bn1(x)
|
||||
out1 = F.relu(out1, True)
|
||||
out1 = self.conv1(out1)
|
||||
|
||||
out2 = self.bn2(out1)
|
||||
out2 = F.relu(out2, True)
|
||||
out2 = self.conv2(out2)
|
||||
|
||||
out3 = self.bn3(out2)
|
||||
out3 = F.relu(out3, True)
|
||||
out3 = self.conv3(out3)
|
||||
|
||||
out3 = torch.cat((out1, out2, out3), 1)
|
||||
|
||||
if self.downsample is not None:
|
||||
residual = self.downsample(residual)
|
||||
|
||||
out3 += residual
|
||||
|
||||
return out3
|
||||
|
||||
|
||||
class Bottleneck(nn.Module):
|
||||
|
||||
expansion = 4
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
||||
super(Bottleneck, self).__init__()
|
||||
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(planes)
|
||||
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
|
||||
padding=1, bias=False)
|
||||
self.bn2 = nn.BatchNorm2d(planes)
|
||||
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
|
||||
self.bn3 = nn.BatchNorm2d(planes * 4)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.downsample = downsample
|
||||
self.stride = stride
|
||||
|
||||
def forward(self, x):
|
||||
residual = x
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv3(out)
|
||||
out = self.bn3(out)
|
||||
|
||||
if self.downsample is not None:
|
||||
residual = self.downsample(x)
|
||||
|
||||
out += residual
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class HourGlass(nn.Module):
|
||||
def __init__(self, num_modules, depth, num_features):
|
||||
super(HourGlass, self).__init__()
|
||||
self.num_modules = num_modules
|
||||
self.depth = depth
|
||||
self.features = num_features
|
||||
|
||||
self._generate_network(self.depth)
|
||||
|
||||
def _generate_network(self, level):
|
||||
self.add_module('b1_' + str(level), ConvBlock(self.features, self.features))
|
||||
|
||||
self.add_module('b2_' + str(level), ConvBlock(self.features, self.features))
|
||||
|
||||
if level > 1:
|
||||
self._generate_network(level - 1)
|
||||
else:
|
||||
self.add_module('b2_plus_' + str(level), ConvBlock(self.features, self.features))
|
||||
|
||||
self.add_module('b3_' + str(level), ConvBlock(self.features, self.features))
|
||||
|
||||
def _forward(self, level, inp):
|
||||
# Upper branch
|
||||
up1 = inp
|
||||
up1 = self._modules['b1_' + str(level)](up1)
|
||||
|
||||
# Lower branch
|
||||
low1 = F.avg_pool2d(inp, 2, stride=2)
|
||||
low1 = self._modules['b2_' + str(level)](low1)
|
||||
|
||||
if level > 1:
|
||||
low2 = self._forward(level - 1, low1)
|
||||
else:
|
||||
low2 = low1
|
||||
low2 = self._modules['b2_plus_' + str(level)](low2)
|
||||
|
||||
low3 = low2
|
||||
low3 = self._modules['b3_' + str(level)](low3)
|
||||
|
||||
up2 = F.interpolate(low3, scale_factor=2, mode='nearest')
|
||||
|
||||
return up1 + up2
|
||||
|
||||
def forward(self, x):
|
||||
return self._forward(self.depth, x)
|
||||
|
||||
|
||||
class FAN(nn.Module):
|
||||
|
||||
def __init__(self, num_modules=1):
|
||||
super(FAN, self).__init__()
|
||||
self.num_modules = num_modules
|
||||
|
||||
# Base part
|
||||
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
|
||||
self.bn1 = nn.BatchNorm2d(64)
|
||||
self.conv2 = ConvBlock(64, 128)
|
||||
self.conv3 = ConvBlock(128, 128)
|
||||
self.conv4 = ConvBlock(128, 256)
|
||||
|
||||
# Stacking part
|
||||
for hg_module in range(self.num_modules):
|
||||
self.add_module('m' + str(hg_module), HourGlass(1, 4, 256))
|
||||
self.add_module('top_m_' + str(hg_module), ConvBlock(256, 256))
|
||||
self.add_module('conv_last' + str(hg_module),
|
||||
nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
|
||||
self.add_module('bn_end' + str(hg_module), nn.BatchNorm2d(256))
|
||||
self.add_module('l' + str(hg_module), nn.Conv2d(256,
|
||||
68, kernel_size=1, stride=1, padding=0))
|
||||
|
||||
if hg_module < self.num_modules - 1:
|
||||
self.add_module(
|
||||
'bl' + str(hg_module), nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
|
||||
self.add_module('al' + str(hg_module), nn.Conv2d(68,
|
||||
256, kernel_size=1, stride=1, padding=0))
|
||||
|
||||
def forward(self, x):
|
||||
x = F.relu(self.bn1(self.conv1(x)), True)
|
||||
x = F.avg_pool2d(self.conv2(x), 2, stride=2)
|
||||
x = self.conv3(x)
|
||||
x = self.conv4(x)
|
||||
|
||||
previous = x
|
||||
|
||||
outputs = []
|
||||
for i in range(self.num_modules):
|
||||
hg = self._modules['m' + str(i)](previous)
|
||||
|
||||
ll = hg
|
||||
ll = self._modules['top_m_' + str(i)](ll)
|
||||
|
||||
ll = F.relu(self._modules['bn_end' + str(i)]
|
||||
(self._modules['conv_last' + str(i)](ll)), True)
|
||||
|
||||
# Predict heatmaps
|
||||
tmp_out = self._modules['l' + str(i)](ll)
|
||||
outputs.append(tmp_out)
|
||||
|
||||
if i < self.num_modules - 1:
|
||||
ll = self._modules['bl' + str(i)](ll)
|
||||
tmp_out_ = self._modules['al' + str(i)](tmp_out)
|
||||
previous = previous + ll + tmp_out_
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class ResNetDepth(nn.Module):
|
||||
|
||||
def __init__(self, block=Bottleneck, layers=[3, 8, 36, 3], num_classes=68):
|
||||
self.inplanes = 64
|
||||
super(ResNetDepth, self).__init__()
|
||||
self.conv1 = nn.Conv2d(3 + 68, 64, kernel_size=7, stride=2, padding=3,
|
||||
bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(64)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
||||
self.layer1 = self._make_layer(block, 64, layers[0])
|
||||
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
||||
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
||||
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
|
||||
self.avgpool = nn.AvgPool2d(7)
|
||||
self.fc = nn.Linear(512 * block.expansion, num_classes)
|
||||
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
||||
m.weight.data.normal_(0, math.sqrt(2. / n))
|
||||
elif isinstance(m, nn.BatchNorm2d):
|
||||
m.weight.data.fill_(1)
|
||||
m.bias.data.zero_()
|
||||
|
||||
def _make_layer(self, block, planes, blocks, stride=1):
|
||||
downsample = None
|
||||
if stride != 1 or self.inplanes != planes * block.expansion:
|
||||
downsample = nn.Sequential(
|
||||
nn.Conv2d(self.inplanes, planes * block.expansion,
|
||||
kernel_size=1, stride=stride, bias=False),
|
||||
nn.BatchNorm2d(planes * block.expansion),
|
||||
)
|
||||
|
||||
layers = []
|
||||
layers.append(block(self.inplanes, planes, stride, downsample))
|
||||
self.inplanes = planes * block.expansion
|
||||
for i in range(1, blocks):
|
||||
layers.append(block(self.inplanes, planes))
|
||||
|
||||
return nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x)
|
||||
x = self.bn1(x)
|
||||
x = self.relu(x)
|
||||
x = self.maxpool(x)
|
||||
|
||||
x = self.layer1(x)
|
||||
x = self.layer2(x)
|
||||
x = self.layer3(x)
|
||||
x = self.layer4(x)
|
||||
|
||||
x = self.avgpool(x)
|
||||
x = x.view(x.size(0), -1)
|
||||
x = self.fc(x)
|
||||
|
||||
return x
|
||||
|
|
@ -0,0 +1,313 @@
|
|||
from __future__ import print_function
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
import torch
|
||||
import math
|
||||
import numpy as np
|
||||
import cv2
|
||||
|
||||
|
||||
def _gaussian(
|
||||
size=3, sigma=0.25, amplitude=1, normalize=False, width=None,
|
||||
height=None, sigma_horz=None, sigma_vert=None, mean_horz=0.5,
|
||||
mean_vert=0.5):
|
||||
# handle some defaults
|
||||
if width is None:
|
||||
width = size
|
||||
if height is None:
|
||||
height = size
|
||||
if sigma_horz is None:
|
||||
sigma_horz = sigma
|
||||
if sigma_vert is None:
|
||||
sigma_vert = sigma
|
||||
center_x = mean_horz * width + 0.5
|
||||
center_y = mean_vert * height + 0.5
|
||||
gauss = np.empty((height, width), dtype=np.float32)
|
||||
# generate kernel
|
||||
for i in range(height):
|
||||
for j in range(width):
|
||||
gauss[i][j] = amplitude * math.exp(-(math.pow((j + 1 - center_x) / (
|
||||
sigma_horz * width), 2) / 2.0 + math.pow((i + 1 - center_y) / (sigma_vert * height), 2) / 2.0))
|
||||
if normalize:
|
||||
gauss = gauss / np.sum(gauss)
|
||||
return gauss
|
||||
|
||||
|
||||
def draw_gaussian(image, point, sigma):
|
||||
# Check if the gaussian is inside
|
||||
ul = [math.floor(point[0] - 3 * sigma), math.floor(point[1] - 3 * sigma)]
|
||||
br = [math.floor(point[0] + 3 * sigma), math.floor(point[1] + 3 * sigma)]
|
||||
if (ul[0] > image.shape[1] or ul[1] > image.shape[0] or br[0] < 1 or br[1] < 1):
|
||||
return image
|
||||
size = 6 * sigma + 1
|
||||
g = _gaussian(size)
|
||||
g_x = [int(max(1, -ul[0])), int(min(br[0], image.shape[1])) - int(max(1, ul[0])) + int(max(1, -ul[0]))]
|
||||
g_y = [int(max(1, -ul[1])), int(min(br[1], image.shape[0])) - int(max(1, ul[1])) + int(max(1, -ul[1]))]
|
||||
img_x = [int(max(1, ul[0])), int(min(br[0], image.shape[1]))]
|
||||
img_y = [int(max(1, ul[1])), int(min(br[1], image.shape[0]))]
|
||||
assert (g_x[0] > 0 and g_y[1] > 0)
|
||||
image[img_y[0] - 1:img_y[1], img_x[0] - 1:img_x[1]
|
||||
] = image[img_y[0] - 1:img_y[1], img_x[0] - 1:img_x[1]] + g[g_y[0] - 1:g_y[1], g_x[0] - 1:g_x[1]]
|
||||
image[image > 1] = 1
|
||||
return image
|
||||
|
||||
|
||||
def transform(point, center, scale, resolution, invert=False):
|
||||
"""Generate and affine transformation matrix.
|
||||
|
||||
Given a set of points, a center, a scale and a targer resolution, the
|
||||
function generates and affine transformation matrix. If invert is ``True``
|
||||
it will produce the inverse transformation.
|
||||
|
||||
Arguments:
|
||||
point {torch.tensor} -- the input 2D point
|
||||
center {torch.tensor or numpy.array} -- the center around which to perform the transformations
|
||||
scale {float} -- the scale of the face/object
|
||||
resolution {float} -- the output resolution
|
||||
|
||||
Keyword Arguments:
|
||||
invert {bool} -- define wherever the function should produce the direct or the
|
||||
inverse transformation matrix (default: {False})
|
||||
"""
|
||||
_pt = torch.ones(3)
|
||||
_pt[0] = point[0]
|
||||
_pt[1] = point[1]
|
||||
|
||||
h = 200.0 * scale
|
||||
t = torch.eye(3)
|
||||
t[0, 0] = resolution / h
|
||||
t[1, 1] = resolution / h
|
||||
t[0, 2] = resolution * (-center[0] / h + 0.5)
|
||||
t[1, 2] = resolution * (-center[1] / h + 0.5)
|
||||
|
||||
if invert:
|
||||
t = torch.inverse(t)
|
||||
|
||||
new_point = (torch.matmul(t, _pt))[0:2]
|
||||
|
||||
return new_point.int()
|
||||
|
||||
|
||||
def crop(image, center, scale, resolution=256.0):
|
||||
"""Center crops an image or set of heatmaps
|
||||
|
||||
Arguments:
|
||||
image {numpy.array} -- an rgb image
|
||||
center {numpy.array} -- the center of the object, usually the same as of the bounding box
|
||||
scale {float} -- scale of the face
|
||||
|
||||
Keyword Arguments:
|
||||
resolution {float} -- the size of the output cropped image (default: {256.0})
|
||||
|
||||
Returns:
|
||||
[type] -- [description]
|
||||
""" # Crop around the center point
|
||||
""" Crops the image around the center. Input is expected to be an np.ndarray """
|
||||
ul = transform([1, 1], center, scale, resolution, True)
|
||||
br = transform([resolution, resolution], center, scale, resolution, True)
|
||||
# pad = math.ceil(torch.norm((ul - br).float()) / 2.0 - (br[0] - ul[0]) / 2.0)
|
||||
if image.ndim > 2:
|
||||
newDim = np.array([br[1] - ul[1], br[0] - ul[0],
|
||||
image.shape[2]], dtype=np.int32)
|
||||
newImg = np.zeros(newDim, dtype=np.uint8)
|
||||
else:
|
||||
newDim = np.array([br[1] - ul[1], br[0] - ul[0]], dtype=np.int)
|
||||
newImg = np.zeros(newDim, dtype=np.uint8)
|
||||
ht = image.shape[0]
|
||||
wd = image.shape[1]
|
||||
newX = np.array(
|
||||
[max(1, -ul[0] + 1), min(br[0], wd) - ul[0]], dtype=np.int32)
|
||||
newY = np.array(
|
||||
[max(1, -ul[1] + 1), min(br[1], ht) - ul[1]], dtype=np.int32)
|
||||
oldX = np.array([max(1, ul[0] + 1), min(br[0], wd)], dtype=np.int32)
|
||||
oldY = np.array([max(1, ul[1] + 1), min(br[1], ht)], dtype=np.int32)
|
||||
newImg[newY[0] - 1:newY[1], newX[0] - 1:newX[1]
|
||||
] = image[oldY[0] - 1:oldY[1], oldX[0] - 1:oldX[1], :]
|
||||
newImg = cv2.resize(newImg, dsize=(int(resolution), int(resolution)),
|
||||
interpolation=cv2.INTER_LINEAR)
|
||||
return newImg
|
||||
|
||||
|
||||
def get_preds_fromhm(hm, center=None, scale=None):
|
||||
"""Obtain (x,y) coordinates given a set of N heatmaps. If the center
|
||||
and the scale is provided the function will return the points also in
|
||||
the original coordinate frame.
|
||||
|
||||
Arguments:
|
||||
hm {torch.tensor} -- the predicted heatmaps, of shape [B, N, W, H]
|
||||
|
||||
Keyword Arguments:
|
||||
center {torch.tensor} -- the center of the bounding box (default: {None})
|
||||
scale {float} -- face scale (default: {None})
|
||||
"""
|
||||
max, idx = torch.max(
|
||||
hm.view(hm.size(0), hm.size(1), hm.size(2) * hm.size(3)), 2)
|
||||
idx += 1
|
||||
preds = idx.view(idx.size(0), idx.size(1), 1).repeat(1, 1, 2).float()
|
||||
preds[..., 0].apply_(lambda x: (x - 1) % hm.size(3) + 1)
|
||||
preds[..., 1].add_(-1).div_(hm.size(2)).floor_().add_(1)
|
||||
|
||||
for i in range(preds.size(0)):
|
||||
for j in range(preds.size(1)):
|
||||
hm_ = hm[i, j, :]
|
||||
pX, pY = int(preds[i, j, 0]) - 1, int(preds[i, j, 1]) - 1
|
||||
if pX > 0 and pX < 63 and pY > 0 and pY < 63:
|
||||
diff = torch.FloatTensor(
|
||||
[hm_[pY, pX + 1] - hm_[pY, pX - 1],
|
||||
hm_[pY + 1, pX] - hm_[pY - 1, pX]])
|
||||
preds[i, j].add_(diff.sign_().mul_(.25))
|
||||
|
||||
preds.add_(-.5)
|
||||
|
||||
preds_orig = torch.zeros(preds.size())
|
||||
if center is not None and scale is not None:
|
||||
for i in range(hm.size(0)):
|
||||
for j in range(hm.size(1)):
|
||||
preds_orig[i, j] = transform(
|
||||
preds[i, j], center, scale, hm.size(2), True)
|
||||
|
||||
return preds, preds_orig
|
||||
|
||||
def get_preds_fromhm_batch(hm, centers=None, scales=None):
|
||||
"""Obtain (x,y) coordinates given a set of N heatmaps. If the centers
|
||||
and the scales is provided the function will return the points also in
|
||||
the original coordinate frame.
|
||||
|
||||
Arguments:
|
||||
hm {torch.tensor} -- the predicted heatmaps, of shape [B, N, W, H]
|
||||
|
||||
Keyword Arguments:
|
||||
centers {torch.tensor} -- the centers of the bounding box (default: {None})
|
||||
scales {float} -- face scales (default: {None})
|
||||
"""
|
||||
max, idx = torch.max(
|
||||
hm.view(hm.size(0), hm.size(1), hm.size(2) * hm.size(3)), 2)
|
||||
idx += 1
|
||||
preds = idx.view(idx.size(0), idx.size(1), 1).repeat(1, 1, 2).float()
|
||||
preds[..., 0].apply_(lambda x: (x - 1) % hm.size(3) + 1)
|
||||
preds[..., 1].add_(-1).div_(hm.size(2)).floor_().add_(1)
|
||||
|
||||
for i in range(preds.size(0)):
|
||||
for j in range(preds.size(1)):
|
||||
hm_ = hm[i, j, :]
|
||||
pX, pY = int(preds[i, j, 0]) - 1, int(preds[i, j, 1]) - 1
|
||||
if pX > 0 and pX < 63 and pY > 0 and pY < 63:
|
||||
diff = torch.FloatTensor(
|
||||
[hm_[pY, pX + 1] - hm_[pY, pX - 1],
|
||||
hm_[pY + 1, pX] - hm_[pY - 1, pX]])
|
||||
preds[i, j].add_(diff.sign_().mul_(.25))
|
||||
|
||||
preds.add_(-.5)
|
||||
|
||||
preds_orig = torch.zeros(preds.size())
|
||||
if centers is not None and scales is not None:
|
||||
for i in range(hm.size(0)):
|
||||
for j in range(hm.size(1)):
|
||||
preds_orig[i, j] = transform(
|
||||
preds[i, j], centers[i], scales[i], hm.size(2), True)
|
||||
|
||||
return preds, preds_orig
|
||||
|
||||
def shuffle_lr(parts, pairs=None):
|
||||
"""Shuffle the points left-right according to the axis of symmetry
|
||||
of the object.
|
||||
|
||||
Arguments:
|
||||
parts {torch.tensor} -- a 3D or 4D object containing the
|
||||
heatmaps.
|
||||
|
||||
Keyword Arguments:
|
||||
pairs {list of integers} -- [order of the flipped points] (default: {None})
|
||||
"""
|
||||
if pairs is None:
|
||||
pairs = [16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0,
|
||||
26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 27, 28, 29, 30, 35,
|
||||
34, 33, 32, 31, 45, 44, 43, 42, 47, 46, 39, 38, 37, 36, 41,
|
||||
40, 54, 53, 52, 51, 50, 49, 48, 59, 58, 57, 56, 55, 64, 63,
|
||||
62, 61, 60, 67, 66, 65]
|
||||
if parts.ndimension() == 3:
|
||||
parts = parts[pairs, ...]
|
||||
else:
|
||||
parts = parts[:, pairs, ...]
|
||||
|
||||
return parts
|
||||
|
||||
|
||||
def flip(tensor, is_label=False):
|
||||
"""Flip an image or a set of heatmaps left-right
|
||||
|
||||
Arguments:
|
||||
tensor {numpy.array or torch.tensor} -- [the input image or heatmaps]
|
||||
|
||||
Keyword Arguments:
|
||||
is_label {bool} -- [denote wherever the input is an image or a set of heatmaps ] (default: {False})
|
||||
"""
|
||||
if not torch.is_tensor(tensor):
|
||||
tensor = torch.from_numpy(tensor)
|
||||
|
||||
if is_label:
|
||||
tensor = shuffle_lr(tensor).flip(tensor.ndimension() - 1)
|
||||
else:
|
||||
tensor = tensor.flip(tensor.ndimension() - 1)
|
||||
|
||||
return tensor
|
||||
|
||||
# From pyzolib/paths.py (https://bitbucket.org/pyzo/pyzolib/src/tip/paths.py)
|
||||
|
||||
|
||||
def appdata_dir(appname=None, roaming=False):
|
||||
""" appdata_dir(appname=None, roaming=False)
|
||||
|
||||
Get the path to the application directory, where applications are allowed
|
||||
to write user specific files (e.g. configurations). For non-user specific
|
||||
data, consider using common_appdata_dir().
|
||||
If appname is given, a subdir is appended (and created if necessary).
|
||||
If roaming is True, will prefer a roaming directory (Windows Vista/7).
|
||||
"""
|
||||
|
||||
# Define default user directory
|
||||
userDir = os.getenv('FACEALIGNMENT_USERDIR', None)
|
||||
if userDir is None:
|
||||
userDir = os.path.expanduser('~')
|
||||
if not os.path.isdir(userDir): # pragma: no cover
|
||||
userDir = '/var/tmp' # issue #54
|
||||
|
||||
# Get system app data dir
|
||||
path = None
|
||||
if sys.platform.startswith('win'):
|
||||
path1, path2 = os.getenv('LOCALAPPDATA'), os.getenv('APPDATA')
|
||||
path = (path2 or path1) if roaming else (path1 or path2)
|
||||
elif sys.platform.startswith('darwin'):
|
||||
path = os.path.join(userDir, 'Library', 'Application Support')
|
||||
# On Linux and as fallback
|
||||
if not (path and os.path.isdir(path)):
|
||||
path = userDir
|
||||
|
||||
# Maybe we should store things local to the executable (in case of a
|
||||
# portable distro or a frozen application that wants to be portable)
|
||||
prefix = sys.prefix
|
||||
if getattr(sys, 'frozen', None):
|
||||
prefix = os.path.abspath(os.path.dirname(sys.executable))
|
||||
for reldir in ('settings', '../settings'):
|
||||
localpath = os.path.abspath(os.path.join(prefix, reldir))
|
||||
if os.path.isdir(localpath): # pragma: no cover
|
||||
try:
|
||||
open(os.path.join(localpath, 'test.write'), 'wb').close()
|
||||
os.remove(os.path.join(localpath, 'test.write'))
|
||||
except IOError:
|
||||
pass # We cannot write in this directory
|
||||
else:
|
||||
path = localpath
|
||||
break
|
||||
|
||||
# Get path specific for this app
|
||||
if appname:
|
||||
if path == userDir:
|
||||
appname = '.' + appname.lstrip('.') # Make it a hidden directory
|
||||
path = os.path.join(path, appname)
|
||||
if not os.path.isdir(path): # pragma: no cover
|
||||
os.mkdir(path)
|
||||
|
||||
# Done
|
||||
return path
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
from glob import glob
|
||||
import os
|
||||
|
||||
def get_image_list(data_root, split):
|
||||
filelist = []
|
||||
|
||||
with open('filelists/{}.txt'.format(split)) as f:
|
||||
for line in f:
|
||||
line = line.strip()
|
||||
if ' ' in line: line = line.split()[0]
|
||||
filelist.append(os.path.join(data_root, line))
|
||||
|
||||
return filelist
|
||||
|
||||
class HParams:
|
||||
def __init__(self, **kwargs):
|
||||
self.data = {}
|
||||
|
||||
for key, value in kwargs.items():
|
||||
self.data[key] = value
|
||||
|
||||
def __getattr__(self, key):
|
||||
if key not in self.data:
|
||||
raise AttributeError("'HParams' object has no attribute %s" % key)
|
||||
return self.data[key]
|
||||
|
||||
def set_hparam(self, key, value):
|
||||
self.data[key] = value
|
||||
|
||||
|
||||
# Default hyperparameters
|
||||
hparams = HParams(
|
||||
num_mels=80, # Number of mel-spectrogram channels and local conditioning dimensionality
|
||||
# network
|
||||
rescale=True, # Whether to rescale audio prior to preprocessing
|
||||
rescaling_max=0.9, # Rescaling value
|
||||
|
||||
# Use LWS (https://github.com/Jonathan-LeRoux/lws) for STFT and phase reconstruction
|
||||
# It"s preferred to set True to use with https://github.com/r9y9/wavenet_vocoder
|
||||
# Does not work if n_ffit is not multiple of hop_size!!
|
||||
use_lws=False,
|
||||
|
||||
n_fft=800, # Extra window size is filled with 0 paddings to match this parameter
|
||||
hop_size=200, # For 16000Hz, 200 = 12.5 ms (0.0125 * sample_rate)
|
||||
win_size=800, # For 16000Hz, 800 = 50 ms (If None, win_size = n_fft) (0.05 * sample_rate)
|
||||
sample_rate=16000, # 16000Hz (corresponding to librispeech) (sox --i <filename>)
|
||||
|
||||
frame_shift_ms=None, # Can replace hop_size parameter. (Recommended: 12.5)
|
||||
|
||||
# Mel and Linear spectrograms normalization/scaling and clipping
|
||||
signal_normalization=True,
|
||||
# Whether to normalize mel spectrograms to some predefined range (following below parameters)
|
||||
allow_clipping_in_normalization=True, # Only relevant if mel_normalization = True
|
||||
symmetric_mels=True,
|
||||
# Whether to scale the data to be symmetric around 0. (Also multiplies the output range by 2,
|
||||
# faster and cleaner convergence)
|
||||
max_abs_value=4.,
|
||||
# max absolute value of data. If symmetric, data will be [-max, max] else [0, max] (Must not
|
||||
# be too big to avoid gradient explosion,
|
||||
# not too small for fast convergence)
|
||||
# Contribution by @begeekmyfriend
|
||||
# Spectrogram Pre-Emphasis (Lfilter: Reduce spectrogram noise and helps model certitude
|
||||
# levels. Also allows for better G&L phase reconstruction)
|
||||
preemphasize=True, # whether to apply filter
|
||||
preemphasis=0.97, # filter coefficient.
|
||||
|
||||
# Limits
|
||||
min_level_db=-100,
|
||||
ref_level_db=20,
|
||||
fmin=55,
|
||||
# Set this to 55 if your speaker is male! if female, 95 should help taking off noise. (To
|
||||
# test depending on dataset. Pitch info: male~[65, 260], female~[100, 525])
|
||||
fmax=7600, # To be increased/reduced depending on data.
|
||||
|
||||
###################### Our training parameters #################################
|
||||
img_size=96,
|
||||
fps=25,
|
||||
|
||||
batch_size=16,
|
||||
initial_learning_rate=1e-4,
|
||||
nepochs=200000000000000000, ### ctrl + c, stop whenever eval loss is consistently greater than train loss for ~10 epochs
|
||||
num_workers=16,
|
||||
checkpoint_interval=3000,
|
||||
eval_interval=3000,
|
||||
save_optimizer_state=True,
|
||||
|
||||
syncnet_wt=0.0, # is initially zero, will be set automatically to 0.03 later. Leads to faster convergence.
|
||||
syncnet_batch_size=64,
|
||||
syncnet_lr=1e-4,
|
||||
syncnet_eval_interval=10000,
|
||||
syncnet_checkpoint_interval=10000,
|
||||
|
||||
disc_wt=0.07,
|
||||
disc_initial_learning_rate=1e-4,
|
||||
)
|
||||
|
||||
|
||||
def hparams_debug_string():
|
||||
values = hparams.values()
|
||||
hp = [" %s: %s" % (name, values[name]) for name in sorted(values) if name != "sentences"]
|
||||
return "Hyperparameters:\n" + "\n".join(hp)
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
from .wav2lip import Wav2Lip, Wav2Lip_disc_qual
|
||||
from .syncnet import SyncNet_color
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
class Conv2d(nn.Module):
|
||||
def __init__(self, cin, cout, kernel_size, stride, padding, residual=False, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.conv_block = nn.Sequential(
|
||||
nn.Conv2d(cin, cout, kernel_size, stride, padding),
|
||||
nn.BatchNorm2d(cout)
|
||||
)
|
||||
self.act = nn.ReLU()
|
||||
self.residual = residual
|
||||
|
||||
def forward(self, x):
|
||||
out = self.conv_block(x)
|
||||
if self.residual:
|
||||
out += x
|
||||
return self.act(out)
|
||||
|
||||
class nonorm_Conv2d(nn.Module):
|
||||
def __init__(self, cin, cout, kernel_size, stride, padding, residual=False, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.conv_block = nn.Sequential(
|
||||
nn.Conv2d(cin, cout, kernel_size, stride, padding),
|
||||
)
|
||||
self.act = nn.LeakyReLU(0.01, inplace=True)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.conv_block(x)
|
||||
return self.act(out)
|
||||
|
||||
class Conv2dTranspose(nn.Module):
|
||||
def __init__(self, cin, cout, kernel_size, stride, padding, output_padding=0, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.conv_block = nn.Sequential(
|
||||
nn.ConvTranspose2d(cin, cout, kernel_size, stride, padding, output_padding),
|
||||
nn.BatchNorm2d(cout)
|
||||
)
|
||||
self.act = nn.ReLU()
|
||||
|
||||
def forward(self, x):
|
||||
out = self.conv_block(x)
|
||||
return self.act(out)
|
||||
|
|
@ -0,0 +1,66 @@
|
|||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
from .conv import Conv2d
|
||||
|
||||
class SyncNet_color(nn.Module):
|
||||
def __init__(self):
|
||||
super(SyncNet_color, self).__init__()
|
||||
|
||||
self.face_encoder = nn.Sequential(
|
||||
Conv2d(15, 32, kernel_size=(7, 7), stride=1, padding=3),
|
||||
|
||||
Conv2d(32, 64, kernel_size=5, stride=(1, 2), padding=1),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(256, 512, kernel_size=3, stride=2, padding=1),
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=0),
|
||||
Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
|
||||
|
||||
self.audio_encoder = nn.Sequential(
|
||||
Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
|
||||
Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
|
||||
|
||||
def forward(self, audio_sequences, face_sequences): # audio_sequences := (B, dim, T)
|
||||
face_embedding = self.face_encoder(face_sequences)
|
||||
audio_embedding = self.audio_encoder(audio_sequences)
|
||||
|
||||
audio_embedding = audio_embedding.view(audio_embedding.size(0), -1)
|
||||
face_embedding = face_embedding.view(face_embedding.size(0), -1)
|
||||
|
||||
audio_embedding = F.normalize(audio_embedding, p=2, dim=1)
|
||||
face_embedding = F.normalize(face_embedding, p=2, dim=1)
|
||||
|
||||
|
||||
return audio_embedding, face_embedding
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
import math
|
||||
|
||||
from .conv import Conv2dTranspose, Conv2d, nonorm_Conv2d
|
||||
|
||||
class Wav2Lip(nn.Module):
|
||||
def __init__(self):
|
||||
super(Wav2Lip, self).__init__()
|
||||
|
||||
self.face_encoder_blocks = nn.ModuleList([
|
||||
nn.Sequential(Conv2d(6, 16, kernel_size=7, stride=1, padding=3)), # 96,96
|
||||
|
||||
nn.Sequential(Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 48,48
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True)),
|
||||
|
||||
nn.Sequential(Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 24,24
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True)),
|
||||
|
||||
nn.Sequential(Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 12,12
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True)),
|
||||
|
||||
nn.Sequential(Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # 6,6
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True)),
|
||||
|
||||
nn.Sequential(Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 3,3
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
|
||||
|
||||
nn.Sequential(Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 1, 1
|
||||
Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),])
|
||||
|
||||
self.audio_encoder = nn.Sequential(
|
||||
Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
|
||||
Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
|
||||
Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
|
||||
|
||||
self.face_decoder_blocks = nn.ModuleList([
|
||||
nn.Sequential(Conv2d(512, 512, kernel_size=1, stride=1, padding=0),),
|
||||
|
||||
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=1, padding=0), # 3,3
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
|
||||
|
||||
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),), # 6, 6
|
||||
|
||||
nn.Sequential(Conv2dTranspose(768, 384, kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),), # 12, 12
|
||||
|
||||
nn.Sequential(Conv2dTranspose(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),), # 24, 24
|
||||
|
||||
nn.Sequential(Conv2dTranspose(320, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),), # 48, 48
|
||||
|
||||
nn.Sequential(Conv2dTranspose(160, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
|
||||
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),),]) # 96,96
|
||||
|
||||
self.output_block = nn.Sequential(Conv2d(80, 32, kernel_size=3, stride=1, padding=1),
|
||||
nn.Conv2d(32, 3, kernel_size=1, stride=1, padding=0),
|
||||
nn.Sigmoid())
|
||||
|
||||
def forward(self, audio_sequences, face_sequences):
|
||||
# audio_sequences = (B, T, 1, 80, 16)
|
||||
B = audio_sequences.size(0)
|
||||
|
||||
input_dim_size = len(face_sequences.size())
|
||||
if input_dim_size > 4:
|
||||
audio_sequences = torch.cat([audio_sequences[:, i] for i in range(audio_sequences.size(1))], dim=0)
|
||||
face_sequences = torch.cat([face_sequences[:, :, i] for i in range(face_sequences.size(2))], dim=0)
|
||||
|
||||
audio_embedding = self.audio_encoder(audio_sequences) # B, 512, 1, 1
|
||||
|
||||
feats = []
|
||||
x = face_sequences
|
||||
for f in self.face_encoder_blocks:
|
||||
x = f(x)
|
||||
feats.append(x)
|
||||
|
||||
x = audio_embedding
|
||||
for f in self.face_decoder_blocks:
|
||||
x = f(x)
|
||||
try:
|
||||
x = torch.cat((x, feats[-1]), dim=1)
|
||||
except Exception as e:
|
||||
print(x.size())
|
||||
print(feats[-1].size())
|
||||
raise e
|
||||
|
||||
feats.pop()
|
||||
|
||||
x = self.output_block(x)
|
||||
|
||||
if input_dim_size > 4:
|
||||
x = torch.split(x, B, dim=0) # [(B, C, H, W)]
|
||||
outputs = torch.stack(x, dim=2) # (B, C, T, H, W)
|
||||
|
||||
else:
|
||||
outputs = x
|
||||
|
||||
return outputs
|
||||
|
||||
class Wav2Lip_disc_qual(nn.Module):
|
||||
def __init__(self):
|
||||
super(Wav2Lip_disc_qual, self).__init__()
|
||||
|
||||
self.face_encoder_blocks = nn.ModuleList([
|
||||
nn.Sequential(nonorm_Conv2d(3, 32, kernel_size=7, stride=1, padding=3)), # 48,96
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(32, 64, kernel_size=5, stride=(1, 2), padding=2), # 48,48
|
||||
nonorm_Conv2d(64, 64, kernel_size=5, stride=1, padding=2)),
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(64, 128, kernel_size=5, stride=2, padding=2), # 24,24
|
||||
nonorm_Conv2d(128, 128, kernel_size=5, stride=1, padding=2)),
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(128, 256, kernel_size=5, stride=2, padding=2), # 12,12
|
||||
nonorm_Conv2d(256, 256, kernel_size=5, stride=1, padding=2)),
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 6,6
|
||||
nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=1)),
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(512, 512, kernel_size=3, stride=2, padding=1), # 3,3
|
||||
nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=1),),
|
||||
|
||||
nn.Sequential(nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 1, 1
|
||||
nonorm_Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),])
|
||||
|
||||
self.binary_pred = nn.Sequential(nn.Conv2d(512, 1, kernel_size=1, stride=1, padding=0), nn.Sigmoid())
|
||||
self.label_noise = .0
|
||||
|
||||
def get_lower_half(self, face_sequences):
|
||||
return face_sequences[:, :, face_sequences.size(2)//2:]
|
||||
|
||||
def to_2d(self, face_sequences):
|
||||
B = face_sequences.size(0)
|
||||
face_sequences = torch.cat([face_sequences[:, :, i] for i in range(face_sequences.size(2))], dim=0)
|
||||
return face_sequences
|
||||
|
||||
def perceptual_forward(self, false_face_sequences):
|
||||
false_face_sequences = self.to_2d(false_face_sequences)
|
||||
false_face_sequences = self.get_lower_half(false_face_sequences)
|
||||
|
||||
false_feats = false_face_sequences
|
||||
for f in self.face_encoder_blocks:
|
||||
false_feats = f(false_feats)
|
||||
|
||||
false_pred_loss = F.binary_cross_entropy(self.binary_pred(false_feats).view(len(false_feats), -1),
|
||||
torch.ones((len(false_feats), 1)).cuda())
|
||||
|
||||
return false_pred_loss
|
||||
|
||||
def forward(self, face_sequences):
|
||||
face_sequences = self.to_2d(face_sequences)
|
||||
face_sequences = self.get_lower_half(face_sequences)
|
||||
|
||||
x = face_sequences
|
||||
for f in self.face_encoder_blocks:
|
||||
x = f(x)
|
||||
|
||||
return self.binary_pred(x).view(len(x), -1)
|
||||
|
|
@ -0,0 +1 @@
|
|||
debug folder
|
||||
|
|
@ -0,0 +1 @@
|
|||
image generated by stable diffusion
|
||||
|
|
@ -0,0 +1 @@
|
|||
images send to stable diffusion
|
||||
|
|
@ -0,0 +1 @@
|
|||
mask send to stable diffusion
|
||||
|
|
@ -0,0 +1 @@
|
|||
Place shape_predictor_68_face_landmarks.dat here
|
||||
|
|
@ -0,0 +1 @@
|
|||
Generated results will be placed in this folder by default.
|
||||
|
|
@ -0,0 +1 @@
|
|||
Temporary files at the time of inference/testing will be saved here. You can ignore them.
|
||||
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,271 @@
|
|||
import numpy as np
|
||||
import cv2, os, scripts.wav2lip.audio as audio
|
||||
import subprocess
|
||||
from tqdm import tqdm
|
||||
import torch, scripts.wav2lip.face_detection as face_detection
|
||||
from scripts.wav2lip.models import Wav2Lip
|
||||
import platform
|
||||
import modules.shared as shared
|
||||
|
||||
|
||||
class W2l:
|
||||
def __init__(self, face, audio, checkpoint, nosmooth, resize_factor, pad_top, pad_bottom, pad_left, pad_right):
|
||||
self.wav2lip_folder = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-1])
|
||||
self.static = False
|
||||
if os.path.isfile(face) and face.split('.')[1] in ['jpg', 'png', 'jpeg']:
|
||||
self.static = True
|
||||
|
||||
self.img_size = 96
|
||||
self.face = face
|
||||
self.audio = audio
|
||||
self.checkpoint = checkpoint
|
||||
self.mel_step_size = 16
|
||||
self.face_det_batch_size = 16
|
||||
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
self.pads = [pad_top, pad_bottom, pad_left, pad_right]
|
||||
self.nosmooth = nosmooth
|
||||
self.box = [-1, -1, -1, -1]
|
||||
self.wav2lip_batch_size = 128
|
||||
self.fps = 25
|
||||
self.resize_factor = resize_factor
|
||||
self.rotate = False
|
||||
self.crop = [0, -1, 0, -1]
|
||||
self.checkpoint_path = self.wav2lip_folder + '/checkpoints/' + self.checkpoint + '.pth'
|
||||
self.outfile = self.wav2lip_folder + '/results/result_voice.mp4'
|
||||
print('Using {} for inference.'.format(self.device))
|
||||
|
||||
def get_smoothened_boxes(self, boxes, T):
|
||||
for i in range(len(boxes)):
|
||||
if i + T > len(boxes):
|
||||
window = boxes[len(boxes) - T:]
|
||||
else:
|
||||
window = boxes[i: i + T]
|
||||
boxes[i] = np.mean(window, axis=0)
|
||||
return boxes
|
||||
|
||||
def face_detect(self, images):
|
||||
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,
|
||||
flip_input=False, device=self.device)
|
||||
|
||||
batch_size = self.face_det_batch_size
|
||||
|
||||
while 1:
|
||||
predictions = []
|
||||
try:
|
||||
for i in tqdm(range(0, len(images), batch_size)):
|
||||
predictions.extend(detector.get_detections_for_batch(np.array(images[i:i + batch_size])))
|
||||
except RuntimeError:
|
||||
if batch_size == 1:
|
||||
raise RuntimeError(
|
||||
'Image too big to run face detection on GPU. Please use the --resize_factor argument')
|
||||
batch_size //= 2
|
||||
print('Recovering from OOM error; New batch size: {}'.format(batch_size))
|
||||
continue
|
||||
break
|
||||
|
||||
results = []
|
||||
pady1, pady2, padx1, padx2 = self.pads
|
||||
n = 0
|
||||
for rect, image in zip(predictions, images):
|
||||
if rect is None:
|
||||
print("Hum : " + str(n))
|
||||
cv2.imwrite(self.wav2lip_folder + '/temp/faulty_frame.jpg', image) # check this frame where the face was not detected.
|
||||
raise ValueError('Face not detected! Ensure the video contains a face in all the frames.')
|
||||
|
||||
y1 = max(0, rect[1] - pady1)
|
||||
y2 = min(image.shape[0], rect[3] + pady2)
|
||||
x1 = max(0, rect[0] - padx1)
|
||||
x2 = min(image.shape[1], rect[2] + padx2)
|
||||
|
||||
results.append([x1, y1, x2, y2])
|
||||
n += 1
|
||||
|
||||
boxes = np.array(results)
|
||||
if not self.nosmooth: boxes = self.get_smoothened_boxes(boxes, T=5)
|
||||
results = [[image[y1: y2, x1:x2], (y1, y2, x1, x2)] for image, (x1, y1, x2, y2) in zip(images, boxes)]
|
||||
|
||||
del detector
|
||||
return results
|
||||
|
||||
def datagen(self, frames, mels):
|
||||
img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
|
||||
|
||||
if self.box[0] == -1:
|
||||
if not self.static:
|
||||
face_det_results = self.face_detect(frames) # BGR2RGB for CNN face detection
|
||||
else:
|
||||
face_det_results = self.face_detect([frames[0]])
|
||||
else:
|
||||
print('Using the specified bounding box instead of face detection...')
|
||||
y1, y2, x1, x2 = self.box
|
||||
face_det_results = [[f[y1: y2, x1:x2], (y1, y2, x1, x2)] for f in frames]
|
||||
|
||||
for i, m in enumerate(mels):
|
||||
idx = 0 if self.static else i % len(frames)
|
||||
frame_to_save = frames[idx].copy()
|
||||
face, coords = face_det_results[idx].copy()
|
||||
|
||||
face = cv2.resize(face, (self.img_size, self.img_size))
|
||||
|
||||
img_batch.append(face)
|
||||
mel_batch.append(m)
|
||||
frame_batch.append(frame_to_save)
|
||||
coords_batch.append(coords)
|
||||
|
||||
if len(img_batch) >= self.wav2lip_batch_size:
|
||||
img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
|
||||
|
||||
img_masked = img_batch.copy()
|
||||
img_masked[:, self.img_size // 2:] = 0
|
||||
|
||||
img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.
|
||||
mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
|
||||
|
||||
yield img_batch, mel_batch, frame_batch, coords_batch
|
||||
img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
|
||||
|
||||
if len(img_batch) > 0:
|
||||
img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
|
||||
|
||||
img_masked = img_batch.copy()
|
||||
img_masked[:, self.img_size // 2:] = 0
|
||||
|
||||
img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.
|
||||
mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
|
||||
|
||||
yield img_batch, mel_batch, frame_batch, coords_batch
|
||||
|
||||
def _load(self, checkpoint_path):
|
||||
shared.cmd_opts.disable_safe_unpickle = True
|
||||
if self.device == 'cuda':
|
||||
checkpoint = torch.load(checkpoint_path)
|
||||
else:
|
||||
checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
|
||||
shared.cmd_opts.disable_safe_unpickle = False
|
||||
return checkpoint
|
||||
|
||||
def load_model(self, path):
|
||||
model = Wav2Lip()
|
||||
print("Load checkpoint from: {}".format(path))
|
||||
checkpoint = self._load(path)
|
||||
s = checkpoint["state_dict"]
|
||||
new_s = {}
|
||||
for k, v in s.items():
|
||||
new_s[k.replace('module.', '')] = v
|
||||
model.load_state_dict(new_s)
|
||||
|
||||
model = model.to(self.device)
|
||||
return model.eval()
|
||||
|
||||
def execute(self):
|
||||
if not os.path.isfile(self.face):
|
||||
raise ValueError('--face argument must be a valid path to video/image file')
|
||||
|
||||
elif self.face.split('.')[1] in ['jpg', 'png', 'jpeg']:
|
||||
full_frames = [cv2.imread(self.face)]
|
||||
fps = self.fps
|
||||
|
||||
else:
|
||||
video_stream = cv2.VideoCapture(self.face)
|
||||
fps = video_stream.get(cv2.CAP_PROP_FPS)
|
||||
|
||||
print('Reading video frames...')
|
||||
|
||||
full_frames = []
|
||||
while 1:
|
||||
still_reading, frame = video_stream.read()
|
||||
if not still_reading:
|
||||
video_stream.release()
|
||||
break
|
||||
if self.resize_factor > 1:
|
||||
frame = cv2.resize(frame,
|
||||
(frame.shape[1] // self.resize_factor, frame.shape[0] // self.resize_factor))
|
||||
|
||||
if self.rotate:
|
||||
frame = cv2.rotate(frame, cv2.cv2.ROTATE_90_CLOCKWISE)
|
||||
|
||||
y1, y2, x1, x2 = self.crop
|
||||
if x2 == -1: x2 = frame.shape[1]
|
||||
if y2 == -1: y2 = frame.shape[0]
|
||||
|
||||
frame = frame[y1:y2, x1:x2]
|
||||
|
||||
full_frames.append(frame)
|
||||
|
||||
print("Number of frames available for inference: " + str(len(full_frames)))
|
||||
|
||||
if not self.audio.endswith('.wav'):
|
||||
print('Extracting raw audio...')
|
||||
command = 'ffmpeg -y -i {} -strict -2 {}'.format(self.audio, self.wav2lip_folder + '/temp/temp.wav')
|
||||
|
||||
#subprocess.call(command, shell=True)
|
||||
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
|
||||
stdout, stderr = process.communicate()
|
||||
if process.returncode != 0:
|
||||
raise RuntimeError(stderr)
|
||||
|
||||
self.audio = self.wav2lip_folder + '/temp/temp.wav'
|
||||
|
||||
|
||||
|
||||
wav = audio.load_wav(self.audio, 16000)
|
||||
mel = audio.melspectrogram(wav)
|
||||
print(mel.shape)
|
||||
|
||||
if np.isnan(mel.reshape(-1)).sum() > 0:
|
||||
raise ValueError(
|
||||
'Mel contains nan! Using a TTS voice? Add a small epsilon noise to the wav file and try again')
|
||||
|
||||
mel_chunks = []
|
||||
mel_idx_multiplier = 80. / fps
|
||||
i = 0
|
||||
while 1:
|
||||
start_idx = int(i * mel_idx_multiplier)
|
||||
if start_idx + self.mel_step_size > len(mel[0]):
|
||||
mel_chunks.append(mel[:, len(mel[0]) - self.mel_step_size:])
|
||||
break
|
||||
mel_chunks.append(mel[:, start_idx: start_idx + self.mel_step_size])
|
||||
i += 1
|
||||
|
||||
print("Length of mel chunks: {}".format(len(mel_chunks)))
|
||||
|
||||
full_frames = full_frames[:len(mel_chunks)]
|
||||
|
||||
batch_size = self.wav2lip_batch_size
|
||||
gen = self.datagen(full_frames.copy(), mel_chunks)
|
||||
|
||||
for i, (img_batch, mel_batch, frames, coords) in enumerate(tqdm(gen,
|
||||
total=int(
|
||||
np.ceil(
|
||||
float(len(mel_chunks)) / batch_size)))):
|
||||
if i == 0:
|
||||
model = self.load_model(self.checkpoint_path)
|
||||
print("Model loaded")
|
||||
|
||||
frame_h, frame_w = full_frames[0].shape[:-1]
|
||||
out = cv2.VideoWriter(self.wav2lip_folder + '/temp/result.avi',
|
||||
cv2.VideoWriter_fourcc(*'DIVX'), fps, (frame_w, frame_h))
|
||||
|
||||
img_batch = torch.FloatTensor(np.transpose(img_batch, (0, 3, 1, 2))).to(self.device)
|
||||
mel_batch = torch.FloatTensor(np.transpose(mel_batch, (0, 3, 1, 2))).to(self.device)
|
||||
|
||||
with torch.no_grad():
|
||||
pred = model(mel_batch, img_batch)
|
||||
|
||||
pred = pred.cpu().numpy().transpose(0, 2, 3, 1) * 255.
|
||||
|
||||
for p, f, c in zip(pred, frames, coords):
|
||||
y1, y2, x1, x2 = c
|
||||
p = cv2.resize(p.astype(np.uint8), (x2 - x1, y2 - y1))
|
||||
|
||||
f[y1:y2, x1:x2] = p
|
||||
out.write(f)
|
||||
|
||||
out.release()
|
||||
|
||||
command = 'ffmpeg -y -i {} -i {} -strict -2 -q:v 1 {}'.format(self.audio, self.wav2lip_folder + '/temp/result.avi', self.outfile)
|
||||
#subprocess.call(command, shell=platform.system() != 'Windows')
|
||||
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
|
||||
stdout, stderr = process.communicate()
|
||||
if process.returncode != 0:
|
||||
raise RuntimeError(stderr)
|
||||
|
|
@ -0,0 +1,254 @@
|
|||
import os
|
||||
import requests
|
||||
import base64
|
||||
import io
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import cv2
|
||||
import dlib
|
||||
import torch
|
||||
import scripts.wav2lip.face_detection as face_detection
|
||||
from imutils import face_utils
|
||||
import subprocess
|
||||
|
||||
from modules import processing
|
||||
|
||||
|
||||
class Wav2LipUHQ:
|
||||
def __init__(self, face, audio):
|
||||
self.wav2lip_folder = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-1])
|
||||
self.original_video = face
|
||||
self.audio = audio
|
||||
self.w2l_video = self.wav2lip_folder + '/results/result_voice.mp4'
|
||||
self.original_is_image = self.original_video.lower().endswith(
|
||||
('.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif'))
|
||||
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
|
||||
def assure_path_exists(self, path):
|
||||
dir = os.path.dirname(path)
|
||||
if not os.path.exists(dir):
|
||||
os.makedirs(dir)
|
||||
|
||||
def get_framerate(self, video_file):
|
||||
video = cv2.VideoCapture(video_file)
|
||||
fps = video.get(cv2.CAP_PROP_FPS)
|
||||
video.release()
|
||||
return fps
|
||||
|
||||
def execute_command(self, command):
|
||||
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
|
||||
stdout, stderr = process.communicate()
|
||||
if process.returncode != 0:
|
||||
raise RuntimeError(stderr)
|
||||
|
||||
def create_video_from_images(self, nb_frames):
|
||||
fps = str(self.get_framerate(self.w2l_video))
|
||||
command = "ffmpeg -y -framerate " + fps + " -start_number 0 -i " + \
|
||||
self.wav2lip_folder + "/output/final/output_%05d.png -vframes " + str(nb_frames) + \
|
||||
" -c:v libx264 -pix_fmt yuv420p -b:v 8000k " + self.wav2lip_folder + "/output/video.mp4"
|
||||
|
||||
self.execute_command(command)
|
||||
|
||||
def extract_audio_from_video(self):
|
||||
command = "ffmpeg -y -i " + self.w2l_video + " -vn -acodec copy " + \
|
||||
self.wav2lip_folder + "/output/output_audio.aac"
|
||||
self.execute_command(command)
|
||||
|
||||
def add_audio_to_video(self):
|
||||
command = "ffmpeg -y -framerate -i " + self.wav2lip_folder + "/output/video.mp4 -i " + \
|
||||
self.wav2lip_folder + "/output/output_audio.aac -c:v copy -c:a aac -strict experimental " + \
|
||||
self.wav2lip_folder + "/output/output_video.mp4"
|
||||
self.execute_command(command)
|
||||
|
||||
def create_image(self, image, mask, payload, shape, img_count):
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
image = open(image, "rb").read()
|
||||
image_mask = open(mask, "rb").read()
|
||||
url = payload["url"]
|
||||
payload = payload["payload"]
|
||||
payload["init_images"] = ["data:image/png;base64," + base64.b64encode(image).decode('UTF-8')]
|
||||
payload["mask"] = "data:image/png;base64," + base64.b64encode(image_mask).decode('UTF-8')
|
||||
|
||||
path = output_dir
|
||||
response = requests.post(url=f'{url}', json=payload)
|
||||
r = response.json()
|
||||
for idx in range(len(r['images'])):
|
||||
i = r['images'][idx]
|
||||
image = Image.open(io.BytesIO(base64.b64decode(i.split(",", 1)[0])))
|
||||
image_name = path + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
image.save(image_name)
|
||||
|
||||
def create_img(self, image, mask, shape, img_count):
|
||||
image = Image.open(image).convert('RGB')
|
||||
mask = Image.open(mask).convert('RGB')
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
p = processing.StableDiffusionProcessingImg2Img(
|
||||
outpath_samples=output_dir,
|
||||
) # we'll set up the rest later
|
||||
|
||||
p.c = None
|
||||
p.extra_network_data = None
|
||||
p.image_conditioning = None
|
||||
p.init_latent = None
|
||||
p.mask_for_overlay = None
|
||||
p.negative_prompts = None
|
||||
p.nmask = None
|
||||
p.overlay_images = None
|
||||
p.paste_to = None
|
||||
p.prompts = None
|
||||
p.width, p.height = shape[0], shape[1]
|
||||
p.steps = 150
|
||||
p.seed = 65541238
|
||||
p.seed_resize_from_h = 0
|
||||
p.seed_resize_from_w = 0
|
||||
p.seeds = None
|
||||
p.subseeds = None
|
||||
p.uc = None
|
||||
p.sampler = None
|
||||
p.sampler_name = "Euler a"
|
||||
p.tiling = False
|
||||
p.restore_faces = True
|
||||
p.do_not_save_samples = True
|
||||
p.mask_blur = 4
|
||||
p.extra_generation_params["Mask blur"] = 4
|
||||
p.denoising_strength = 0
|
||||
p.cfg_scale = 1
|
||||
p.inpainting_mask_invert = 0
|
||||
p.inpainting_fill = 1
|
||||
p.inpaint_full_res = 0
|
||||
p.inpaint_full_res_padding = 32
|
||||
p.info_text = [""]
|
||||
p.init_images = [image]
|
||||
p.image_mask = mask
|
||||
|
||||
processed = processing.process_images(p)
|
||||
results = processed.images[0]
|
||||
image_name = output_dir + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
results.save(image_name)
|
||||
|
||||
def initialize_dlib_predictor(self):
|
||||
print("[INFO] Loading the predictor...")
|
||||
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,
|
||||
flip_input=False, device=self.device)
|
||||
predictor = dlib.shape_predictor(self.wav2lip_folder + "/predicator/shape_predictor_68_face_landmarks.dat")
|
||||
return detector, predictor
|
||||
|
||||
def initialize_video_streams(self):
|
||||
print("[INFO] Loading File...")
|
||||
vs = cv2.VideoCapture(self.w2l_video)
|
||||
if self.original_is_image:
|
||||
vi = cv2.imread(self.original_video)
|
||||
else:
|
||||
vi = cv2.VideoCapture(self.original_video)
|
||||
return vs, vi
|
||||
|
||||
def dilate_mouth(self, mouth, w, h):
|
||||
mask = np.zeros((w, h), dtype=np.uint8)
|
||||
cv2.fillPoly(mask, [mouth], 255)
|
||||
kernel = np.ones((10, 10), np.uint8)
|
||||
dilated_mask = cv2.dilate(mask, kernel, iterations=1)
|
||||
contours, _ = cv2.findContours(dilated_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
dilated_points = contours[0].squeeze()
|
||||
return dilated_points
|
||||
|
||||
def execute(self):
|
||||
output_dir = self.wav2lip_folder + '/output/'
|
||||
image_path = output_dir + "images/"
|
||||
mask_path = output_dir + "masks/"
|
||||
debug_path = output_dir + "debug/"
|
||||
|
||||
detector, predictor = self.initialize_dlib_predictor()
|
||||
vs, vi = self.initialize_video_streams()
|
||||
(mstart, mend) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
|
||||
(jstart, jend) = face_utils.FACIAL_LANDMARKS_IDXS["jaw"]
|
||||
(nstart, nend) = face_utils.FACIAL_LANDMARKS_IDXS["nose"]
|
||||
|
||||
max_frame = str(int(vs.get(cv2.CAP_PROP_FRAME_COUNT)))
|
||||
frame_number = 0
|
||||
|
||||
while True:
|
||||
print("Processing frame: " + str(frame_number) + " of " + max_frame)
|
||||
|
||||
ret, w2l_frame = vs.read()
|
||||
if not ret:
|
||||
break
|
||||
|
||||
if self.original_is_image:
|
||||
original_frame = vi
|
||||
else:
|
||||
ret, original_frame = vi.read()
|
||||
if not ret:
|
||||
break
|
||||
|
||||
w2l_gray = cv2.cvtColor(w2l_frame, cv2.COLOR_RGB2GRAY)
|
||||
original_gray = cv2.cvtColor(original_frame, cv2.COLOR_RGB2GRAY)
|
||||
if w2l_gray.shape != original_gray.shape:
|
||||
w2l_gray = cv2.resize(w2l_gray, (original_gray.shape[1], original_gray.shape[0]))
|
||||
w2l_frame = cv2.resize(w2l_frame, (original_gray.shape[1], original_gray.shape[0]))
|
||||
|
||||
diff = np.abs(original_gray - w2l_gray)
|
||||
diff[diff > 10] = 255
|
||||
diff[diff <= 10] = 0
|
||||
cv2.imwrite(debug_path + "diff_" + str(frame_number) + ".png", diff)
|
||||
|
||||
rects = detector.get_detections_for_batch(np.array([np.array(w2l_frame)]))
|
||||
mask = np.zeros_like(diff)
|
||||
|
||||
# Process each detected face
|
||||
for (i, rect) in enumerate(rects):
|
||||
# copy pixel from diff to mask where pixel is in rects
|
||||
shape = predictor(original_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
jaw = shape[jstart:jend][1:-1]
|
||||
nose = shape[nstart:nend][2]
|
||||
|
||||
shape = predictor(w2l_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
mouth = shape[mstart:mend][:-8]
|
||||
mouth = np.delete(mouth, [3], axis=0)
|
||||
mouth = self.dilate_mouth(mouth, original_gray.shape[0], original_gray.shape[1])
|
||||
# affiche les points sur un clone de l'image
|
||||
clone = w2l_frame.copy()
|
||||
for (x, y) in np.concatenate((jaw, mouth, [nose])):
|
||||
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
|
||||
cv2.imwrite(debug_path + "points_" + str(frame_number) + ".png", clone)
|
||||
|
||||
external_shape = np.append(jaw, [nose], axis=0)
|
||||
kernel = np.ones((3, 3), np.uint8)
|
||||
external_shape_pts = external_shape.reshape((-1, 1, 2))
|
||||
mask = cv2.fillPoly(mask, [external_shape_pts], 255)
|
||||
mask = cv2.erode(mask, kernel, iterations=5)
|
||||
masked_diff = cv2.bitwise_and(diff, diff, mask=mask)
|
||||
cv2.fillConvexPoly(masked_diff, mouth, 255)
|
||||
masked_save = cv2.GaussianBlur(masked_diff, (15, 15), 0)
|
||||
|
||||
cv2.imwrite(mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png', masked_save)
|
||||
masked_diff = np.uint8(masked_diff / 255)
|
||||
masked_diff = cv2.cvtColor(masked_diff, cv2.COLOR_GRAY2BGR)
|
||||
dst = w2l_frame * masked_diff
|
||||
cv2.imwrite(debug_path + "dst_" + str(frame_number) + ".png", dst)
|
||||
original_frame = original_frame * (1 - masked_diff) + dst
|
||||
|
||||
height, width, _ = original_frame.shape
|
||||
image_name = image_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
mask_name = mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
cv2.imwrite(image_name, original_frame)
|
||||
self.create_img(image_name, mask_name, (width, height), frame_number)
|
||||
|
||||
frame_number += 1
|
||||
|
||||
cv2.destroyAllWindows()
|
||||
vs.release()
|
||||
if not self.original_is_image:
|
||||
vi.release()
|
||||
|
||||
print("[INFO] Create Video output!")
|
||||
self.create_video_from_images(frame_number - 1)
|
||||
print("[INFO] Extract Audio from input!")
|
||||
self.extract_audio_from_video()
|
||||
print("[INFO] Add Audio to Video!")
|
||||
self.add_audio_to_video()
|
||||
|
||||
print("[INFO] Done! file save in output/video_output.mp4")
|
||||
|
|
@ -0,0 +1,255 @@
|
|||
import os
|
||||
import requests
|
||||
import base64
|
||||
import io
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import cv2
|
||||
import dlib
|
||||
import torch
|
||||
import scripts.wav2lip.face_detection as face_detection
|
||||
from imutils import face_utils
|
||||
import subprocess
|
||||
|
||||
from modules import processing
|
||||
|
||||
|
||||
class Wav2LipUHQ:
|
||||
def __init__(self, face, audio):
|
||||
self.wav2lip_folder = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-1])
|
||||
self.original_video = face
|
||||
self.audio = audio
|
||||
self.w2l_video = self.wav2lip_folder + '/results/result_voice.mp4'
|
||||
self.original_is_image = self.original_video.lower().endswith(
|
||||
('.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif'))
|
||||
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
|
||||
def assure_path_exists(self, path):
|
||||
dir = os.path.dirname(path)
|
||||
if not os.path.exists(dir):
|
||||
os.makedirs(dir)
|
||||
|
||||
def get_framerate(self, video_file):
|
||||
video = cv2.VideoCapture(video_file)
|
||||
fps = video.get(cv2.CAP_PROP_FPS)
|
||||
video.release()
|
||||
return fps
|
||||
|
||||
def execute_command(self, command):
|
||||
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
|
||||
stdout, stderr = process.communicate()
|
||||
if process.returncode != 0:
|
||||
raise RuntimeError(stderr)
|
||||
|
||||
def create_video_from_images(self, nb_frames):
|
||||
fps = str(self.get_framerate(self.w2l_video))
|
||||
command = ["ffmpeg", "-y", "-framerate", fps, "-start_number", "0", "-i",
|
||||
self.wav2lip_folder + "/output/final/output_%05d.png", "-vframes",
|
||||
str(nb_frames), "-c:v", "libx264", "-pix_fmt", "yuv420p", "-b:v", "8000k",
|
||||
self.wav2lip_folder + "/output/video.mp4"]
|
||||
|
||||
self.execute_command(command)
|
||||
|
||||
def extract_audio_from_video(self):
|
||||
command = ["ffmpeg", "-y", "-i", self.w2l_video, "-vn", "-acodec", "copy",
|
||||
self.wav2lip_folder + "/output/output_audio.aac"]
|
||||
self.execute_command(command)
|
||||
|
||||
def add_audio_to_video(self):
|
||||
command = ["ffmpeg", "-y", "-i", self.wav2lip_folder + "/output/video.mp4", "-i",
|
||||
self.wav2lip_folder + "/output/output_audio.aac", "-c:v", "copy", "-c:a", "aac", "-strict",
|
||||
"experimental", self.wav2lip_folder + "/output/output_video.mp4"]
|
||||
self.execute_command(command)
|
||||
|
||||
def create_image(self, image, mask, payload, shape, img_count):
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
image = open(image, "rb").read()
|
||||
image_mask = open(mask, "rb").read()
|
||||
url = payload["url"]
|
||||
payload = payload["payload"]
|
||||
payload["init_images"] = ["data:image/png;base64," + base64.b64encode(image).decode('UTF-8')]
|
||||
payload["mask"] = "data:image/png;base64," + base64.b64encode(image_mask).decode('UTF-8')
|
||||
|
||||
path = output_dir
|
||||
response = requests.post(url=f'{url}', json=payload)
|
||||
r = response.json()
|
||||
for idx in range(len(r['images'])):
|
||||
i = r['images'][idx]
|
||||
image = Image.open(io.BytesIO(base64.b64decode(i.split(",", 1)[0])))
|
||||
image_name = path + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
image.save(image_name)
|
||||
|
||||
def create_img(self, image, mask, shape, img_count):
|
||||
image = Image.open(image).convert('RGB')
|
||||
mask = Image.open(mask).convert('RGB')
|
||||
output_dir = self.wav2lip_folder + '/output/final/'
|
||||
p = processing.StableDiffusionProcessingImg2Img(
|
||||
outpath_samples=output_dir,
|
||||
) # we'll set up the rest later
|
||||
|
||||
p.c = None
|
||||
p.extra_network_data = None
|
||||
p.image_conditioning = None
|
||||
p.init_latent = None
|
||||
p.mask_for_overlay = None
|
||||
p.negative_prompts = None
|
||||
p.nmask = None
|
||||
p.overlay_images = None
|
||||
p.paste_to = None
|
||||
p.prompts = None
|
||||
p.width, p.height = shape[0], shape[1]
|
||||
p.steps = 150
|
||||
p.seed = 65541238
|
||||
p.seed_resize_from_h = 0
|
||||
p.seed_resize_from_w = 0
|
||||
p.seeds = None
|
||||
p.subseeds = None
|
||||
p.uc = None
|
||||
p.sampler = None
|
||||
p.sampler_name = "Euler a"
|
||||
p.tiling = False
|
||||
p.restore_faces = True
|
||||
p.do_not_save_samples = True
|
||||
p.mask_blur = 4
|
||||
p.extra_generation_params["Mask blur"] = 4
|
||||
p.denoising_strength = 0
|
||||
p.cfg_scale = 1
|
||||
p.inpainting_mask_invert = 0
|
||||
p.inpainting_fill = 1
|
||||
p.inpaint_full_res = 0
|
||||
p.inpaint_full_res_padding = 32
|
||||
|
||||
p.init_images = [image]
|
||||
p.image_mask = mask
|
||||
|
||||
processed = processing.process_images(p)
|
||||
results = processed.images[0]
|
||||
image_name = output_dir + "output_" + str(img_count).rjust(5, '0') + ".png"
|
||||
results.save(image_name)
|
||||
|
||||
def initialize_dlib_predictor(self):
|
||||
print("[INFO] Loading the predictor...")
|
||||
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,
|
||||
flip_input=False, device=self.device)
|
||||
predictor = dlib.shape_predictor(self.wav2lip_folder + "/predicator/shape_predictor_68_face_landmarks.dat")
|
||||
return detector, predictor
|
||||
|
||||
def initialize_video_streams(self):
|
||||
print("[INFO] Loading File...")
|
||||
vs = cv2.VideoCapture(self.w2l_video)
|
||||
if self.original_is_image:
|
||||
vi = cv2.imread(self.original_video)
|
||||
else:
|
||||
vi = cv2.VideoCapture(self.original_video)
|
||||
return vs, vi
|
||||
|
||||
def dilate_mouth(self, mouth, w, h):
|
||||
mask = np.zeros((w, h), dtype=np.uint8)
|
||||
cv2.fillPoly(mask, [mouth], 255)
|
||||
kernel = np.ones((10, 10), np.uint8)
|
||||
dilated_mask = cv2.dilate(mask, kernel, iterations=1)
|
||||
contours, _ = cv2.findContours(dilated_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
dilated_points = contours[0].squeeze()
|
||||
return dilated_points
|
||||
|
||||
def execute(self):
|
||||
output_dir = self.wav2lip_folder + '/output/'
|
||||
image_path = output_dir + "images/"
|
||||
mask_path = output_dir + "masks/"
|
||||
debug_path = output_dir + "debug/"
|
||||
|
||||
detector, predictor = self.initialize_dlib_predictor()
|
||||
vs, vi = self.initialize_video_streams()
|
||||
(mstart, mend) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
|
||||
(jstart, jend) = face_utils.FACIAL_LANDMARKS_IDXS["jaw"]
|
||||
(nstart, nend) = face_utils.FACIAL_LANDMARKS_IDXS["nose"]
|
||||
|
||||
max_frame = str(int(vs.get(cv2.CAP_PROP_FRAME_COUNT)))
|
||||
frame_number = 0
|
||||
|
||||
while True:
|
||||
print("Processing frame: " + str(frame_number) + " of " + max_frame)
|
||||
|
||||
ret, w2l_frame = vs.read()
|
||||
if not ret:
|
||||
break
|
||||
|
||||
if self.original_is_image:
|
||||
original_frame = vi
|
||||
else:
|
||||
ret, original_frame = vi.read()
|
||||
if not ret:
|
||||
break
|
||||
|
||||
w2l_gray = cv2.cvtColor(w2l_frame, cv2.COLOR_RGB2GRAY)
|
||||
original_gray = cv2.cvtColor(original_frame, cv2.COLOR_RGB2GRAY)
|
||||
if w2l_gray.shape != original_gray.shape:
|
||||
w2l_gray = cv2.resize(w2l_gray, (original_gray.shape[1], original_gray.shape[0]))
|
||||
w2l_frame = cv2.resize(w2l_frame, (original_gray.shape[1], original_gray.shape[0]))
|
||||
|
||||
diff = np.abs(original_gray - w2l_gray)
|
||||
diff[diff > 10] = 255
|
||||
diff[diff <= 10] = 0
|
||||
cv2.imwrite(debug_path + "diff_" + str(frame_number) + ".png", diff)
|
||||
|
||||
rects = detector.get_detections_for_batch(np.array([np.array(w2l_frame)]))
|
||||
mask = np.zeros_like(diff)
|
||||
|
||||
# Process each detected face
|
||||
for (i, rect) in enumerate(rects):
|
||||
# copy pixel from diff to mask where pixel is in rects
|
||||
shape = predictor(original_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
jaw = shape[jstart:jend][1:-1]
|
||||
nose = shape[nstart:nend][2]
|
||||
|
||||
shape = predictor(w2l_gray, dlib.rectangle(*rect))
|
||||
shape = face_utils.shape_to_np(shape)
|
||||
|
||||
mouth = shape[mstart:mend][:-8]
|
||||
mouth = np.delete(mouth, [3], axis=0)
|
||||
mouth = self.dilate_mouth(mouth, original_gray.shape[0], original_gray.shape[1])
|
||||
# affiche les points sur un clone de l'image
|
||||
clone = w2l_frame.copy()
|
||||
for (x, y) in np.concatenate((jaw, mouth, [nose])):
|
||||
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
|
||||
cv2.imwrite(debug_path + "points_" + str(frame_number) + ".png", clone)
|
||||
|
||||
external_shape = np.append(jaw, [nose], axis=0)
|
||||
kernel = np.ones((3, 3), np.uint8)
|
||||
external_shape_pts = external_shape.reshape((-1, 1, 2))
|
||||
mask = cv2.fillPoly(mask, [external_shape_pts], 255)
|
||||
mask = cv2.erode(mask, kernel, iterations=5)
|
||||
masked_diff = cv2.bitwise_and(diff, diff, mask=mask)
|
||||
cv2.fillConvexPoly(masked_diff, mouth, 255)
|
||||
masked_save = cv2.GaussianBlur(masked_diff, (15, 15), 0)
|
||||
|
||||
cv2.imwrite(mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png', masked_save)
|
||||
masked_diff = np.uint8(masked_diff / 255)
|
||||
masked_diff = cv2.cvtColor(masked_diff, cv2.COLOR_GRAY2BGR)
|
||||
dst = w2l_frame * masked_diff
|
||||
cv2.imwrite(debug_path + "dst_" + str(frame_number) + ".png", dst)
|
||||
original_frame = original_frame * (1 - masked_diff) + dst
|
||||
|
||||
height, width, _ = original_frame.shape
|
||||
image_name = image_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
mask_name = mask_path + 'image_' + str(frame_number).rjust(5, '0') + '.png'
|
||||
cv2.imwrite(image_name, original_frame)
|
||||
self.create_img(image_name, mask_name, (width, height), frame_number)
|
||||
|
||||
frame_number += 1
|
||||
|
||||
cv2.destroyAllWindows()
|
||||
vs.release()
|
||||
if not self.original_is_image:
|
||||
vi.release()
|
||||
|
||||
print("[INFO] Create Video output!")
|
||||
self.create_video_from_images(frame_number - 1)
|
||||
print("[INFO] Extract Audio from input!")
|
||||
self.extract_audio_from_video()
|
||||
print("[INFO] Add Audio to Video!")
|
||||
self.add_audio_to_video()
|
||||
|
||||
print("[INFO] Done! file save in output/video_output.mp4")
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
import os
|
||||
import sys
|
||||
|
||||
def wav2lip_uhq_sys_extend():
|
||||
wav2lip_uhq_folder_name = os.path.sep.join(os.path.abspath(__file__).split(os.path.sep)[:-2])
|
||||
|
||||
basedirs = [os.getcwd()]
|
||||
for _ in basedirs:
|
||||
wav2lip_uhq_paths_to_ensure = [os.path.join(wav2lip_uhq_folder_name, 'scripts')]
|
||||
for wav2lip_uhq_scripts_path_fix in wav2lip_uhq_paths_to_ensure:
|
||||
if wav2lip_uhq_scripts_path_fix not in sys.path:
|
||||
sys.path.extend([wav2lip_uhq_scripts_path_fix])
|
||||
Loading…
Reference in New Issue