add demofusion
parent
b14b43ee43
commit
6fbf987cc1
|
|
@ -0,0 +1,94 @@
|
|||
## Technical Part
|
||||
|
||||
For those who want to know how this works.
|
||||
|
||||
### Tiled VAE
|
||||
|
||||
The core technique is to estimate GroupNorm params for a seamless generation.
|
||||
|
||||
1. The image is split into tiles, which are then padded with 11/32 pixels' in the decoder/encoder.
|
||||
2. When Fast Mode is disabled:
|
||||
1. The original VAE forward is decomposed into a task queue and a task worker, which starts to process each tile.
|
||||
2. When GroupNorm is needed, it suspends, stores current GroupNorm mean and var, send everything to RAM, and turns to the next tile.
|
||||
3. After all GroupNorm means and vars are summarized, it applies group norm to tiles and continues.
|
||||
4. A zigzag execution order is used to reduce unnecessary data transfer.
|
||||
3. When Fast Mode is enabled:
|
||||
1. The original input is downsampled and passed to a separate task queue.
|
||||
2. Its group norm parameters are recorded and used by all tiles' task queues.
|
||||
3. Each tile is separately processed without any RAM-VRAM data transfer.
|
||||
4. After all tiles are processed, tiles are written to a result buffer and returned.
|
||||
|
||||
ℹ Encoder color fix = only estimate GroupNorm before downsampling, i.e., run in a semi-fast mode.
|
||||
|
||||
****
|
||||
|
||||
### Tiled Diffusion
|
||||
|
||||
1. The latent image is split into tiles.
|
||||
2. In MultiDiffusion:
|
||||
1. The UNet predicts the noise of each tile.
|
||||
2. The tiles are denoised by the original sampler for one time step.
|
||||
3. The tiles are added together but divided by how many times each pixel is added.
|
||||
3. In Mixture of Diffusers:
|
||||
1. The UNet predicts the noise of each tile
|
||||
2. All noises are fused with a gaussian weight mask.
|
||||
3. The denoiser denoises the whole image for one time step using fused noises.
|
||||
4. Repeat 2-3 until all timesteps are completed.
|
||||
|
||||
⚪ Advantages
|
||||
|
||||
- Draw super large resolution (2k~8k) images in limited VRAM
|
||||
- Seamless output without any post-processing
|
||||
|
||||
⚪ Drawbacks
|
||||
|
||||
- It will be significantly slower than the usual generation.
|
||||
- The gradient calculation is not compatible with this hack. It will break any backward() or torch.autograd.grad()
|
||||
|
||||
****
|
||||
|
||||
|
||||
## 技术部分
|
||||
|
||||
这部分内容是给想知道工作原理的人看的。
|
||||
|
||||
### Tiled VAE
|
||||
|
||||
核心技术是估算 GroupNorm 参数以实现无缝生成。
|
||||
|
||||
1. 图像被分成小块,然后在编码器 / 解码器中各进行了 11/32 像素的扩张。
|
||||
2. 当禁用快速模式时:
|
||||
1. 原始的 VAE 前向传播被分解为任务队列和任务工作器,开始处理每个小块。
|
||||
2. 当需要 GroupNorm 时,它会暂停,存储当前的 GroupNorm 均值和方差,将所有内容发送到内存中,然后转到下一个小块。
|
||||
3. 在汇总所有 GroupNorm 均值和方差之后,将结果应用到小块中并继续。
|
||||
4. 使用锯齿形执行顺序以减少不必要的数据传输。
|
||||
3. 当启用快速模式时:
|
||||
1. 原始输入被下采样并传递到单独的任务队列。
|
||||
2. 它的 GroupNorm 参数被记录并由所有小块的任务队列使用。
|
||||
3. 每个小块被单独处理,没有任何 内存 <-> 显存 的数据传输。
|
||||
4. 处理完所有小块后,小块被写入结果缓冲区并返回。
|
||||
|
||||
ℹ 编码器颜色修复 = 仅在下采样之前估计 GroupNorm,即以半快速模式运行。
|
||||
|
||||
### Tiled Diffusion
|
||||
|
||||
1. 潜在图像被分成小块。
|
||||
2. 在 MultiDiffusion 中:
|
||||
1. UNet 预测每个小块的噪声。
|
||||
2. 小块由原始采样器去噪一个时间步。
|
||||
3. 小块被加在一起,但除以每个像素的累加次数(即加权平均)。
|
||||
3. 在 Mixture of Diffusers 中:
|
||||
1. UNet 预测每个小块的噪声。
|
||||
2. 所有噪声与高斯权重蒙版融合。
|
||||
3. 降噪器对整个图像使用融合的噪声去噪一个时间步。
|
||||
4. 重复执行步骤 2-3,直到完成所有时间步长。
|
||||
|
||||
⚪ 优点
|
||||
|
||||
- 在有限的显存中绘制超大分辨率(2k~8k)图像
|
||||
- 无需任何后处理即可实现无缝输出
|
||||
|
||||
⚪ 缺点
|
||||
|
||||
- 它将明显比通常的生成速度慢。
|
||||
- 梯度计算与此技巧不兼容。它将破坏任何 backward() 或 torch.autograd.grad()。
|
||||
294
README.md
294
README.md
|
|
@ -4,20 +4,294 @@
|
|||
|
||||
English|[中文](README_CN.md)
|
||||
|
||||
Original project address https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
|
||||
Please be aware that the License of this repo has changed to prevent some web shops from deceiving the customers. This extension is licensed under [CC BY-NC-SA](https://creativecommons.org/licenses/by-nc-sa/4.0/), everyone is FREE of charge to access, use, modify and redistribute with the same license.
|
||||
**You cannot use versions after AOE 2023.3.28 for commercial sales (only refers to code of this repo, the derived artworks are NOT restricted).**
|
||||
|
||||
This fork is based on the original project's approach and adds a demofusion plugin based on k-diffusion implementation to the stable diffusion webui, using the same approach as the original project.
|
||||
|
||||
Note that during use:
|
||||
|
||||
- Do not enable tilediffusion and demofusion at the same time
|
||||
- Realistic visuals are more suitable for demofusion
|
||||
- High denoising intensity is required to obtain better images
|
||||
- In img2img mode, please describe your image as accurately as possible using text. If the image itself is generated by txt2img, it is recommended to use the original random seed, text, and image generation model
|
||||
- Same as the original project, compatible with stablesr, controllnet, and noise inversion
|
||||
由于部分无良商家销售WebUI,捆绑本插件做卖点收取智商税,本仓库的许可证已修改为 [CC BY-NC-SA](https://creativecommons.org/licenses/by-nc-sa/4.0/),任何人都可以自由获取、使用、修改、以相同协议重分发本插件。
|
||||
**自许可证修改之日(AOE 2023.3.28)起,之后的版本禁止用于商业贩售 (不可贩售本仓库代码,但衍生的艺术创作内容物不受此限制)。**
|
||||
|
||||
If you like the project, please give me a star! ⭐
|
||||
|
||||
[](https://ko-fi.com/pkuliyi2015)
|
||||
|
||||
****
|
||||
|
||||
The extension enables **large image drawing & upscaling with limited VRAM** via the following techniques:
|
||||
|
||||
1. Two SOTA diffusion tiling algorithms: [Mixture of Diffusers](https://github.com/albarji/mixture-of-diffusers) and [MultiDiffusion](https://multidiffusion.github.io), add [Demofusion](https://github.com/PRIS-CV/DemoFusion)
|
||||
2. My original Tiled VAE algorithm.
|
||||
3. My original TIled Noise Inversion for better upscaling.
|
||||
|
||||
|
||||
## Features
|
||||
|
||||
- [x] SDXL model support (no region control)
|
||||
- [x] [StableSR support](https://github.com/pkuliyi2015/sd-webui-stablesr)
|
||||
- [x] [Tiled Noise Inversion](#🆕-tiled-noise-inversion)
|
||||
- [x] [Tiled VAE](#🔥-tiled-vae)
|
||||
- [x] [Regional Prompt Control](#region-prompt-control)
|
||||
- [x] [Img2img upscale](#img2img-upscale)
|
||||
- [x] [Ultra-Large image generation](#ultra-large-image-generation)
|
||||
|
||||
=> Quickstart Tutorial: [Tutorial for multidiffusion upscaler for automatic1111](https://civitai.com/models/34726), thanks to [@PotatoBananaApple](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/discussions/120) 🎉
|
||||
|
||||
****
|
||||
|
||||
### 🆕 Combine with ControlNet v1.1 Tile Model
|
||||
|
||||
> High quality large images with tidy details.
|
||||
|
||||
- Our Tiled Noise Inversion feature can cooperate with ControlNet v1.1 tile model (CN Tile, for short) to produce amazingly clear results with proper details. [Example](https://imgsli.com/MTc2MDU0)
|
||||
- CN Tile with large denoising strengths (i.e. >= 0.4) tends to produce overly sufficient details, making the image look dirty or messy.
|
||||
- MultiDiffusion Noise Inversion tends to produce tidy but overly retouched images without enough details.
|
||||
- Combine the two, you get amazingly good results:
|
||||
- Clear lines, edges, and colors
|
||||
- Proper and reasonable details, no weird or dirty pieces.
|
||||
- Recommended settings:
|
||||
- Denoising Strength >= 0.75
|
||||
- Method = Mixture of Diffusers, Overlap = 8
|
||||
- Noise Inversion Steps >= 30
|
||||
- **Renoise strength = 0**
|
||||
- CN Tile preprocessor = tile_resample, downsampling rate = 2
|
||||
- If your result is blurry:
|
||||
- Try higher Noise Inversion Steps.
|
||||
- Try lower Denoising Strength.
|
||||
- Try another checkpoint.
|
||||
- Compare with pure CN Tile.
|
||||
- [Comparison1](https://imgsli.com/MTc1OTc3), 50 NI steps, denoise = 0.75
|
||||
- [Comparison2](https://imgsli.com/MTc1OTc4), 200 NI steps, denoise = 1
|
||||
- Note that high denoising strengths will change the image color. This is a known issue of CN Tile that cannot be fixed by us.
|
||||
|
||||
### Tiled Noise Inversion
|
||||
|
||||
> safe Img2Img without painting structure change
|
||||
|
||||
- **Ultra high-consistency image upscale**, up to 8k resolution in 12G memory.
|
||||
- Especially good when you don't want to wildly change your character's face.
|
||||
- 4x upscaling demo, denoising strength=0.4: [comparison 1](https://imgsli.com/MTY1NzM1), [comparison 2](https://imgsli.com/MTY2MTY5)
|
||||
- Compare to Ultimate SD Upscale, the algorithm is **much more faithful to the original image** and produces significantly fewer artifacts. See the Comparison with Ultimate SD Upcaler (at its optimal denoising strength=0.3) [comparison 1](https://imgsli.com/MTY1NzUw), [comparison 2](https://imgsli.com/MTY2MTcx)
|
||||
|
||||
⚠ Instead of generating an 8k image at once, you should first try the default parameters with a small image and a small upscale factor (i.e., 1.5) to see if it works.
|
||||
⚠ Generally, the denoising strength needs to be <= 0.6. It is not very sensitive to CFG values, so you can try it free.
|
||||
|
||||
****
|
||||
|
||||
### 🔥 Tiled VAE
|
||||
|
||||
> Dramatically save your VRAM usage on VAE encoding / decoding
|
||||
|
||||
- **It saves your VRAM at nearly no cost.**
|
||||
- You may not need --lowvram or --medvram anymore.
|
||||
- Take highres.fix as an example, if you can only do 1.5x upscale previously, you may do 2.0x upscale with it now.
|
||||
- Normally you can use default settings without changing them.
|
||||
- But if you see CUDA out of memory error, just lower the two tile sizes.
|
||||
|
||||
****
|
||||
|
||||
### Regional Prompt Control
|
||||
|
||||
> Draw large images by fusing multiple regions together.
|
||||
|
||||
⚠ we recommend you use custom regions to fill the whole canvas.
|
||||
|
||||
#### Example 1: draw multiple characters at a high resolution
|
||||
|
||||
- Params:
|
||||
- Ckpt: Anything V4.5, 1920 * 1280 (no highres), method=Mixture of Diffusers
|
||||
- Main prompt = masterpiece, best quality, highres, extremely clear 8k wallpaper, white room, sunlight
|
||||
- Negative prompt = ng_deepnegative_v1_75t EasyNegative
|
||||
- **The tile size parameters become useless; just ignore them.**
|
||||
|
||||
- Regions:
|
||||
- Region 1: Prompt = sofa, Type = Background
|
||||
- Region 2: Prompt = 1girl, gray skirt, (white sweater), (slim) waist, medium breast, long hair, black hair, looking at viewer, sitting on sofa, Type = Foreground, Feather = 0.2
|
||||
- Region 3: Prompt = 1girl, red silky dress, (black hair), (slim) waist, large breast, short hair, laughing, looking at viewer, sitting on sofa, Type = Foreground, Feather = 0.2
|
||||
|
||||
- Region Layout:
|
||||

|
||||
|
||||
- Result (2 out of 4)
|
||||

|
||||

|
||||
|
||||
#### Example 2: draw a full-body character
|
||||
|
||||
ℹ Usually, it is difficult to draw a full-body character at a high resolution (e.g., it may concatenate two bodies).
|
||||
ℹ By putting your character in your background, it becomes much easier.
|
||||
|
||||
- Params:
|
||||
- Ckpt: Anything V4.5, width = 1280, height = 1600 (no highres), method=MultiDiffusion
|
||||
- Main prompt: masterpiece, best quality, highres, extremely clear 8k wallpaper, beach, sea, forest
|
||||
- Neg prompt: ng_deepnegative_v1_75t EasyNegative
|
||||
|
||||
- Regions:
|
||||
- Region 1 Prompt = 1girl, black bikini, (white hair), (slim) waist, giant breast, long hair, Type = Foreground, Feather: 0.2
|
||||
- Region 2 Prompt = (empty), Type: Background
|
||||
|
||||
- Region Layout
|
||||
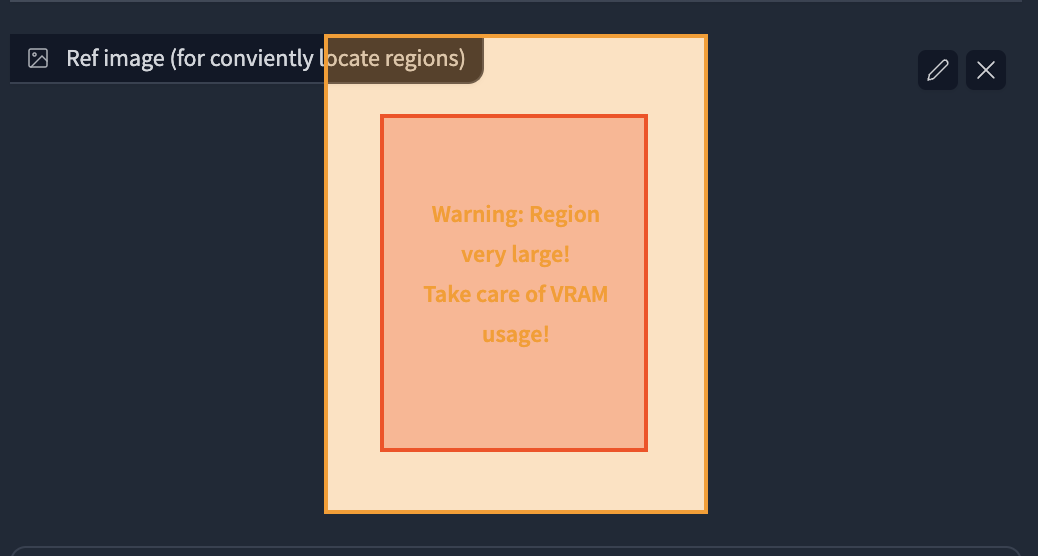
|
||||
|
||||
- Result: 32s, 4729 MB on NVIDIA V100. I was lucky to get this at once without cherry-picks.
|
||||

|
||||
- Also works well for 2.5D characters. For example, the 1024*1620 image generation
|
||||
- Great thanks to all settings from @辰熙. Click here for more of her artworks: https://space.bilibili.com/179819685
|
||||
- Cherry-picked from 20 generations.
|
||||

|
||||
|
||||
****
|
||||
|
||||
### Img2img upscale
|
||||
|
||||
> Leverage Tiled Diffusion to upscale & redraw large images
|
||||
|
||||
#### Example: 1024 * 800 -> 4096 * 3200 image, with default params
|
||||
|
||||
- Params:
|
||||
- denoise=0.4, steps=20, Sampler=Euler a, Upscaler=RealESRGAN++, Negative Prompts=EasyNegative,
|
||||
- Ckpt: Gf-style2 (4GB version), CFG Scale = 14, Clip Skip = 2
|
||||
- method = MultiDiffusion, tile batch size = 8, tile size height = 96, tile size width = 96, overlap = 32
|
||||
- Prompt = masterpiece, best quality, highres, extremely detailed 8k wallpaper, very clear, Neg prompt = EasyNegative.
|
||||
|
||||
- Before upscaling
|
||||

|
||||
- After 4x upscale, No cherry-picking. 1min12s on NVIDIA Tesla V100. (If 2x, it completes in 10s)
|
||||

|
||||
|
||||
****
|
||||
|
||||
### Ultra-Large image generation
|
||||
|
||||
ℹ Please use simple positive prompts at the top of the page, as they will be applied to each tile.
|
||||
ℹ If you want to add objects to a specific position, use **regional prompt control** and enable **draw full canvas background**
|
||||
|
||||
#### Example 1: masterpiece, best quality, highres, city skyline, night.
|
||||
|
||||

|
||||
|
||||
#### Example 2: cooperate with ControlNet to convert ancient wide paintings
|
||||
|
||||
- 22020 x 1080 ultra-wide image conversion
|
||||
- Masterpiece, best quality, highres, ultra-detailed 8k unity wallpaper, bird's-eye view, trees, ancient architectures, stones, farms, crowd, pedestrians
|
||||
- Before: [click for the raw image](https://github.com/pkuliyi2015/multidiffusion-img-demo/blob/master/ancient_city_origin.jpeg)
|
||||
- 
|
||||
- After: [click for the raw image](https://github.com/pkuliyi2015/multidiffusion-img-demo/blob/master/ancient_city.jpeg)
|
||||
- 
|
||||
|
||||
#### Example 3: 2560 * 1280 large image drawing
|
||||
|
||||
- ControlNet (canny edge)
|
||||
|
||||

|
||||

|
||||
|
||||
****
|
||||
|
||||
## Installation
|
||||
|
||||
⚪ Method 1: Official Market
|
||||
|
||||
- Open Automatic1111 WebUI -> Click Tab "Extensions" -> Click Tab "Available" -> Find "[TiledDiffusion with Tiled VAE]" -> Click "Install"
|
||||
|
||||
⚪ Method 2: URL Install
|
||||
|
||||
- Open Automatic1111 WebUI -> Click Tab "Extensions" -> Click Tab "Install from URL" -> type in https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git -> Click "Install"
|
||||
|
||||
|
||||
|
||||
****
|
||||
|
||||
## Usage
|
||||
|
||||
### Tiled VAE
|
||||
|
||||
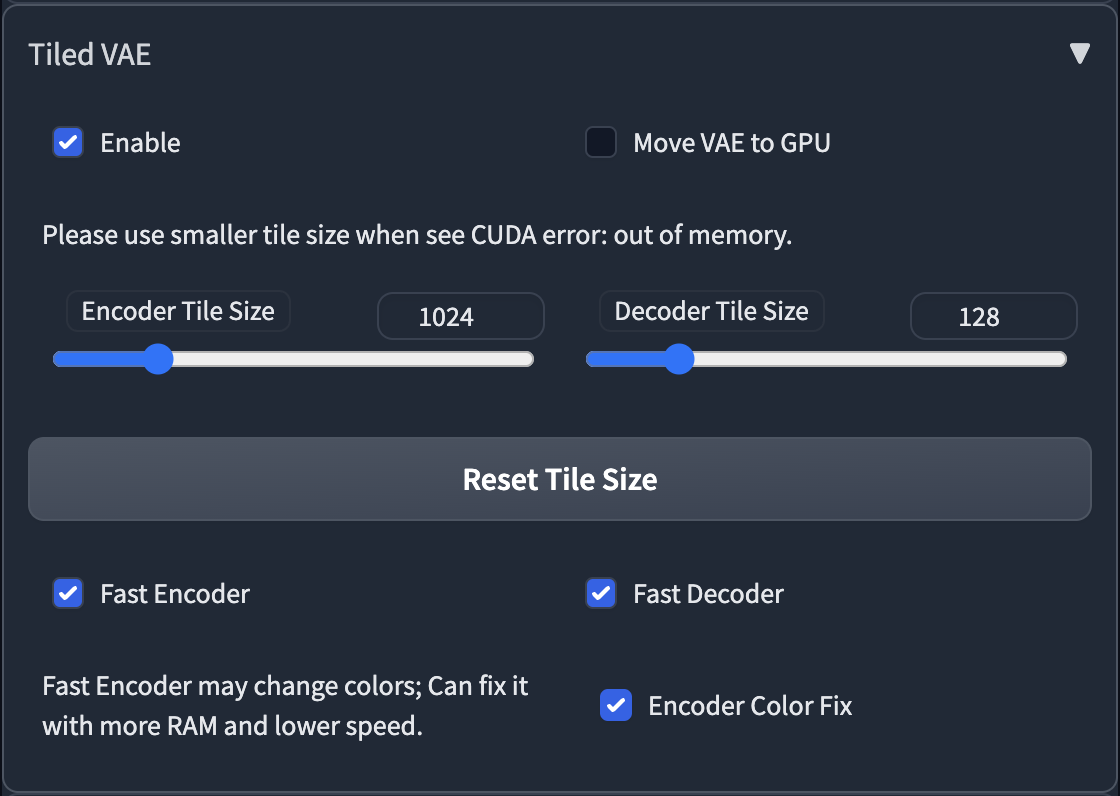
|
||||
|
||||
- The script will recommend settings for you when first use.
|
||||
- So normally, you don't need to change the default params.
|
||||
- You only need to change params in the following cases
|
||||
1. When you see CUDA out of memory error before generation, or after generation, please low down the tile size.
|
||||
2. If you use too small a tile size and the picture becomes gray and unclear, please enable Encoder Color Fix.
|
||||
|
||||
****
|
||||
|
||||
### Tiled Diffusion
|
||||
|
||||

|
||||
|
||||
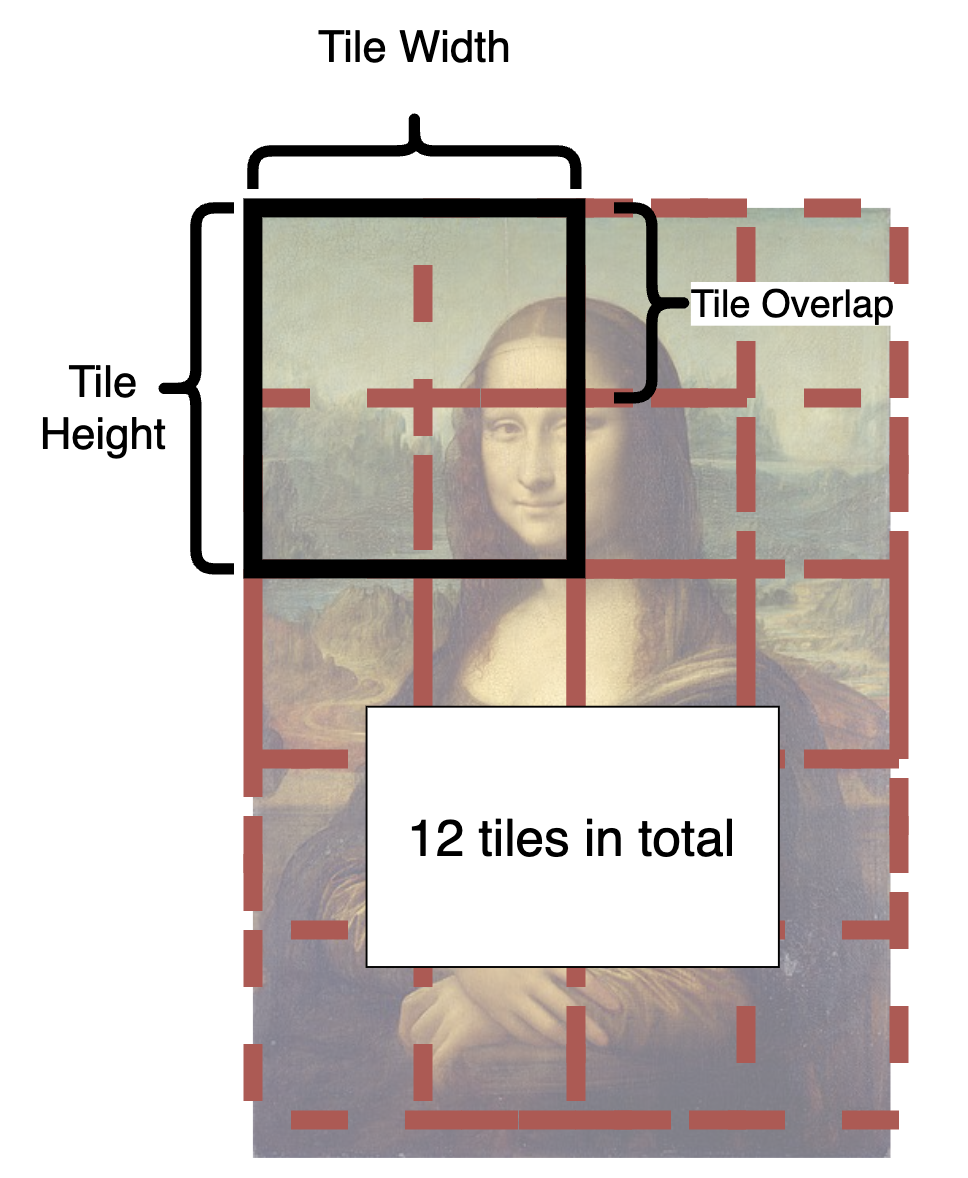
|
||||
|
||||
- From the illustration, you can see how is an image split into tiles.
|
||||
- In each step, each tile in the latent space will be sent to Stable Diffusion UNet.
|
||||
- The tiles are split and fused over and over again until all steps are completed.
|
||||
- What is a good tile size?
|
||||
- A larger tile size will increase the speed because it produces fewer tiles.
|
||||
- However, the optimal size depends on your checkpoint. The basic SD1.4 is only good at drawing 512 * 512 images (SD2.1 will be 768 * 768). And most checkpoints cannot generate good pictures larger than 1280 * 1280. So in latent space let's divide this by 8, and you will get 64 - 160.
|
||||
- Hence, you should pick a value between 64 - 160.
|
||||
- **Personally, I recommend 96 or 128 for fast speed.**
|
||||
- What is a good overlap?
|
||||
- The overlap reduces seams in fusion. Obviously, a larger overlap means fewer seams, but will **significantly reduce the speed** as it brings much more tiles to redraw.
|
||||
- Compared to MultiDiffusion, Mixture of Diffusers requires less overlap because it uses Gaussian smoothing (and therefore can be faster).
|
||||
- **Personally, I recommend 32 or 48 for MultiDiffusion, 16 or 32 for Mixture of Diffusers**
|
||||
- **Upscaler** will appear in i2i. You can select one to upscale your image in advance.
|
||||
|
||||
****
|
||||
|
||||
### Region Prompt Control
|
||||
|
||||
ℹ Normally, all tiles share the same main prompt. So you can't draw meaningful objects with the main prompt, it will draw your object everywhere and ruin your image.
|
||||
ℹ To handle this, we provide the powerful region prompt control tool.
|
||||
|
||||
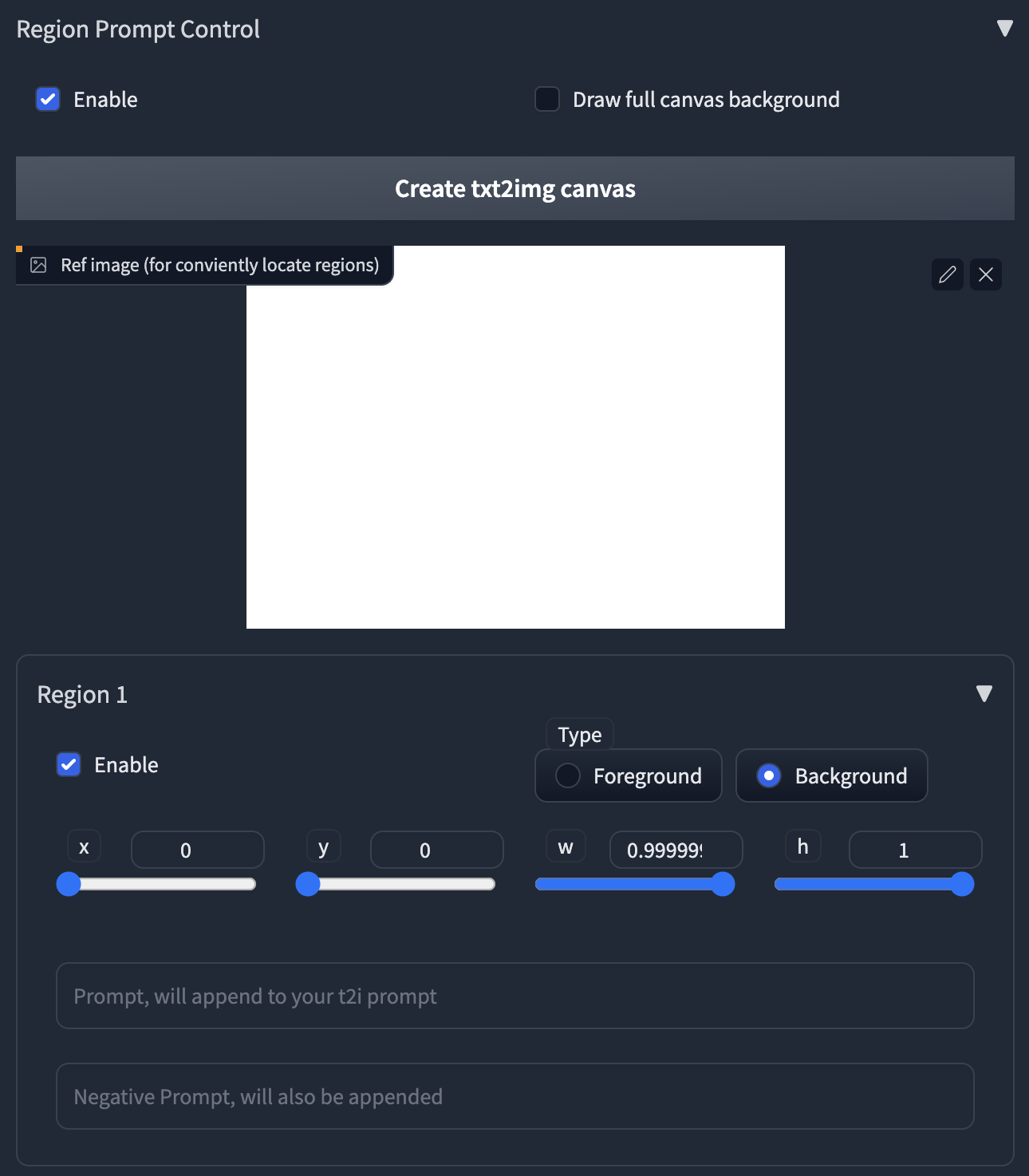
|
||||
|
||||
1. First, enable the region prompt control.
|
||||
- **NOTE: When you enable the control, the default tiling behavior will be disabled.**
|
||||
- If your custom regions can't fill the whole canvas, it will produce brown color (MultiDiffusion) or noises (Mixture of Diffusers) in those uncovered areas.
|
||||
- We recommend you use your own regions to fill the canvas, as it can be much faster when generation.
|
||||
- If you are lazy to draw, you can also enable the **Draw full canvas background.** However, this will be much slower when generation.
|
||||
2. Upload an image or click the button to create an empty image as a reference.
|
||||
3. Click the enable in Region 1, you will see a red rectangle appears in the image.
|
||||
- **Click and drag** the region with your mouse to move and resize them.
|
||||
4. Select region type. If you want to draw objects, select Foreground. Otherwise select Background.
|
||||
- **Feather** will appear if you select foreground.
|
||||
- The larger value will give you more smooth edges.
|
||||
5. Type in your prompt and negative prompt for the region.
|
||||
- **Note: your prompt will be appended to the prompt at the top of the page.**
|
||||
- You can leverage this to save your words, i.e., write common things like "masterpiece, best quality, highres..." and use embedding like EasyNegative at the top of the page.
|
||||
- **You can also use Textual Inversion and LoRA in the prompt**
|
||||
|
||||
****
|
||||
|
||||
### Special tips for Upscaling
|
||||
|
||||
- **Recommend Parameters for Efficient Upscaling.**
|
||||
- Sampler = Euler a, steps = 20, denoise = 0.35, method = Mixture of Diffusers, Latent tile height & width = 128, overlap = 16, tile batch size = 8 (reduce tile batch size if see CUDA out of memory).
|
||||
- We are compatible with masked inpainting
|
||||
- If you want to keep some parts, or the Tiled Diffusion gives you weird results, just mask these areas.
|
||||
- **The checkpoint is crucial.**
|
||||
- MultiDiffusion works very similar to highres.fix, so it highly relies on your checkpoint.
|
||||
- A checkpoint that is good at drawing details can add amazing details to your image.
|
||||
- A **full checkpoint** instead of a pruned one can yield much finer results.
|
||||
- **Don't include any concrete objects in your main prompts,** otherwise, the results get ruined.
|
||||
- Just use something like "highres, masterpiece, best quality, ultra-detailed 8k wallpaper, extremely clear".
|
||||
- And use regional prompt control for concrete objects if you like.
|
||||
- You don't need too large tile size, large overlap and many denoising steps, **or it can be very slow**.
|
||||
- **CFG scale can significantly affect the details.**
|
||||
- A large CFG scale (e.g., 14) gives you much more details.
|
||||
- You can control how much you want to change the original image with **denoising strength from 0.1 - 0.6**.
|
||||
- If your results are still not as satisfying as mine, [see our discussions here.](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/issues/3)
|
||||
|
||||
****
|
||||
|
||||
## License
|
||||
|
||||
This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
|
||||
|
||||
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
|
||||
|
||||
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
|
||||
[cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg
|
||||
|
||||
****
|
||||
|
||||
Thanks for reading!
|
||||
|
|
|
|||
293
README_CN.md
293
README_CN.md
|
|
@ -1,23 +1,292 @@
|
|||
# WebUI的Demofusion插件
|
||||
# 用 Tiled Diffusion & VAE 生成大型图像
|
||||
|
||||
[![CC 署名-非商用-相同方式共享 4.0][cc-by-nc-sa-shield]][cc-by-nc-sa]
|
||||
|
||||
[English](README.md) | 中文
|
||||
|
||||
原项目地址https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
|
||||
|
||||
这个fork基于原项目的思路,为stable diffusion webui增添了基于k-diffusion实现的demofusion插件,使用方式与原项目相同。
|
||||
|
||||
注意,在使用过程中:
|
||||
|
||||
- 不要同时开启tilediffusion和demofusion
|
||||
- 写实的画面会更适合demofusion
|
||||
- 需要保持较高的denoising强度才可以得到较好的图片
|
||||
- img2img模式下请尽可能用准确的text描述你的图片,如果图片本身就是txt2img生成的,建议用原来的随机种子、text以及生图模型
|
||||
- 与原项目相同,兼容stablesr、controlnet,以及noise inversion
|
||||
由于部分无良商家销售WebUI,捆绑本插件做卖点收取智商税,本仓库的许可证已修改为 [CC BY-NC-SA](https://creativecommons.org/licenses/by-nc-sa/4.0/),任何人都可以自由获取、使用、修改、以相同协议重分发本插件。
|
||||
**自许可证修改之日(AOE 2023.3.28)起,之后的版本禁止用于商业贩售 (不可贩售本仓库代码,但衍生的艺术创作内容物不受此限制)。**
|
||||
|
||||
如果你喜欢这个项目,请给作者一个 star!⭐
|
||||
|
||||
[](https://ko-fi.com/pkuliyi2015)
|
||||
|
||||
****
|
||||
|
||||
本插件通过以下三种技术实现了 **在有限的显存中进行大型图像绘制**:
|
||||
|
||||
1. SOTA diffusion tiling 算法:[Mixture of Diffusers](https://github.com/albarji/mixture-of-diffusers) 和 [MultiDiffusion](https://multidiffusion.github.io),新增[Demofusion](https://github.com/PRIS-CV/DemoFusion)
|
||||
2. 原创的 Tiled VAE 算法。
|
||||
3. 原创混合放大算法生成超高清图像
|
||||
|
||||
|
||||
## 功能列表
|
||||
|
||||
- [x] [StableSR支持](https://github.com/pkuliyi2015/sd-webui-stablesr)
|
||||
- [x] [Tiled Noise Inversion](#🆕-tiled-noise-inversion)
|
||||
- [x] [Tiled VAE](#🔥-tiled-vae)
|
||||
- [x] [区域提示控制](#区域提示控制)
|
||||
- [x] [Img2img 放大](#img2img-放大)
|
||||
- [x] [生成超大图像](#生成超大图像)
|
||||
|
||||
=> 快速入门教程: [Tutorial for multidiffusion upscaler for automatic1111](https://civitai.com/models/34726), 感谢由 [@PotatoBananaApple](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/discussions/120) 提供 🎉
|
||||
|
||||
****
|
||||
|
||||
### 🆕 结合 ControlNet v1.1 瓦片模型
|
||||
|
||||
> 高质量图像放大,产生清晰且整洁的细节。
|
||||
|
||||
- 本插件的 Tiled Noise Inversion 功能可以与 ControlNet v1.1 Tile模型 (简称 CN Tile) 协同工作,产出细节合适的高质量大图。[示例](https://imgsli.com/MTc2MDU0)
|
||||
- 高重绘幅度下(>= 0.4)CN Tile 倾向于产生过多的细节,使图像看起来脏乱。
|
||||
- MultiDiffusion Noise Inversion 倾向于产生整洁但过度磨皮的图像,缺乏足够的细节。
|
||||
- 然而把这两个功能结合,就能同时消除两者的缺陷
|
||||
- 能产生整洁清晰的线条、边缘和颜色
|
||||
- 能产生适当和合理的细节,不显得怪异或凌乱
|
||||
- 推荐的设置:
|
||||
- 重绘幅度 >= 0.75,采样步数25步
|
||||
- Method = Mixture of Diffusers,overlap = 8
|
||||
- Noise Inversion Steps >= 30
|
||||
- **Renoise strength = 0**
|
||||
- CN Tile 预处理器 = tile_resample,下采样率 = 2
|
||||
- 如果您的结果模糊:
|
||||
- 尝试增加 Noise Inversion Steps
|
||||
- 尝试降低重绘幅度
|
||||
- 尝试换一个模型
|
||||
- 与纯 CN Tile 对比,画面更加整洁:
|
||||
- [比较1](https://imgsli.com/MTc1OTc3),50 NI 步数,重绘幅度 = 0.75
|
||||
- [比较2](https://imgsli.com/MTc1OTc4),200 NI 步数,重绘幅度 = 1
|
||||
- 高重绘幅度下画面颜色会变,这是CN Tile的已知bug,我们无法修复
|
||||
|
||||
### Tiled Noise Inversion
|
||||
|
||||
> 适用于不想改变作画结构的 Img2Img
|
||||
|
||||
- 超高分辨率高质量图像放大,8k图仅需12G显存
|
||||
- 尤其适用于人像放大,当你不想大幅改变人脸时
|
||||
- 4x放大效果,去噪强度0.4:[对比图1](https://imgsli.com/MTY1NzM1),[对比图2](https://imgsli.com/MTY2MTY5)
|
||||
- 对比Ultimate SD Upscale, 这一的算法更加忠实于原图,且产生更少的奇怪结果。与Ultimate SD Upscale(实测最佳去噪强度0.3),对比如下 [对比图1](https://imgsli.com/MTY1NzUw),[对比图2](https://imgsli.com/MTY2MTcx)
|
||||
|
||||
⚠ 请不要一上来就放的非常大,建议先在小图上用1.5x测试。通常需要denoise小于0.6,CFG敏感度不大,可自行尝试。
|
||||
|
||||
****
|
||||
|
||||
### 🔥 Tiled VAE
|
||||
|
||||
> 极大降低 VAE 编解码大图所需的显存开销
|
||||
|
||||
- **几乎无成本的降低显存使用。**
|
||||
- 您可能不再需要 --lowvram 或 --medvram。
|
||||
- 以 highres.fix 为例,如果您之前只能进行 1.5 倍的放大,则现在可以使用 2.0 倍的放大。
|
||||
- 通常您可以使用默认设置而无需更改它们。
|
||||
- 但是如果您看到 CUDA 内存不足错误,请相对降低两项 tile 大小。
|
||||
|
||||
****
|
||||
|
||||
### 区域提示控制
|
||||
|
||||
> 通过融合多个区域进行大型图像绘制。
|
||||
|
||||
⚠ 我们建议您使用自定义区域来填充整个画布。
|
||||
|
||||
#### 示例 1:以高分辨率绘制多个角色
|
||||
|
||||
- 参数:
|
||||
- 模型:Anything V4.5, 高度 = 1920, 宽度 = 1280 (未使用highres.fix), 方法(Method) = Mixture of Diffusers
|
||||
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, white room, sunlight
|
||||
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
|
||||
- ** 块大小(tile size)参数将不起效,可以忽略它们。**
|
||||
|
||||
- 区域:
|
||||
- 区域 1:提示语 = sofa,类型 = Background
|
||||
- 区域 2:提示语 = 1girl, gray skirt, (white sweater), (slim) waist, medium breast, long hair, black hair, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
|
||||
- 区域 3:提示语 = 1girl, red silky dress, (black hair), (slim) waist, large breast, short hair, laughing, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
|
||||
|
||||
- 区域布局:
|
||||

|
||||
|
||||
- 结果 (4张中的2张)
|
||||

|
||||

|
||||
|
||||
#### 示例 2:绘制全身人物
|
||||
|
||||
ℹ 通常情况下,以高分辨率绘制全身人物会比较困难(例如可能会将两个身体连接在一起)。
|
||||
ℹ 通过将你的角色置入背景中,可以轻松的做到这一点。
|
||||
|
||||
- 参数:
|
||||
- 模型:Anything V4.5,宽度 = 1280,高度 = 1600 (未使用highres.fix),方法(Method) = MultiDiffusion
|
||||
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, beach, sea, forest
|
||||
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
|
||||
|
||||
- 区域:
|
||||
- 区域 1:提示语 = 1girl, black bikini, (white hair), (slim) waist, giant breast, long hair,类型(Type) = Foreground,羽化(Feather) = 0.2
|
||||
- 区域 2:提示语 = (空),类型(Type) = Background
|
||||
|
||||
- 区域布局:
|
||||

|
||||
|
||||
- 结果: NVIDIA V100 使用 4729 MB 显存用了 32 秒生成完毕。我很幸运的一次就得到了这个结果,没有进行任何挑选。
|
||||

|
||||
- 也适用于 2.5D 人物。例如,1024 * 1620像素的图像生成
|
||||
- 特别感谢 @辰熙 的所有设置。点击此处查看更多她的作品:https://space.bilibili.com/179819685
|
||||
- 从20次生成结果中精选而出。
|
||||

|
||||
|
||||
****
|
||||
|
||||
### Img2img 放大
|
||||
|
||||
> 利用 Tiled Diffusion 来放大或重绘图像
|
||||
|
||||
#### 示例:从1024 * 800 放大到 4096 * 3200 ,使用默认参数
|
||||
|
||||
- 参数:
|
||||
- 降噪 = 0.4,步数 = 20,采样器 = Euler a,放大器 = RealESRGAN++,负面提示语=EasyNegative,
|
||||
- 模型:Gf-style2 (4GB 版本), 提示词相关性(CFG Scale) = 14, Clip 跳过层(Clip Skip) = 2
|
||||
- 方法(Method) = MultiDiffusion, 分块批处理规模(tile batch size) = 8, 分块高度(tile size height) = 96, 分块宽度(tile size width) = 96, 分块重叠(overlap) = 32
|
||||
- 全局提示语 = masterpiece, best quality, highres, extremely detailed 8k wallpaper, very clear, 全局负面提示语 = EasyNegative.
|
||||
|
||||
- 放大前
|
||||

|
||||
- 4倍放大后:无精选,在 NVIDIA Tesla V100 上使用1分12秒生成完毕(如果只放大2倍,10秒即可生成完毕)
|
||||

|
||||
|
||||
****
|
||||
|
||||
### 生成超大图像
|
||||
|
||||
ℹ 请在页面顶部使用简单的正面提示语,因为它们将应用于每个区域。
|
||||
ℹ 如果要将对象添加到特定位置,请使用**区域提示控制**并启用**绘制完整的画布背景**
|
||||
|
||||
#### 示例 1:masterpiece, best quality, highres, city skyline, night.
|
||||
|
||||

|
||||
|
||||
#### 示例 2:与 ControlNet 配合转绘清明上河图
|
||||
|
||||
- 22020 x 1080 超宽图像转绘
|
||||
- Masterpiece, best quality, highres, ultra-detailed 8k unity wallpaper, bird's-eye view, trees, ancient architectures, stones, farms, crowd, pedestrians
|
||||
- 原图:[单击查看原图](https://github.com/pkuliyi2015/multidiffusion-img-demo/blob/master/ancient_city_origin.jpeg)
|
||||
- 
|
||||
- 转绘:[单击查看原图](https://github.com/pkuliyi2015/multidiffusion-img-demo/blob/master/ancient_city.jpeg)
|
||||
- 
|
||||
|
||||
#### 示例 3: 2560 * 1280 大型图像绘制
|
||||
|
||||
- ControlNet (canny edge)
|
||||
|
||||

|
||||

|
||||
|
||||
****
|
||||
|
||||
## 安装
|
||||
|
||||
⚪ 方法 1: 官方市场
|
||||
|
||||
- 打开Automatic1111 WebUI -> 点击“扩展”选项卡 -> 点击“可用”选项卡 -> 找到“[MultiDiffusion 放大器(TiledDiffusion with Tiled VAE)]” -> 点击“安装”
|
||||
|
||||
⚪ 方法 2: URL 安装
|
||||
|
||||
- 打开Automatic1111 WebUI -> 点击“扩展”选项卡 -> 点击“从网址安装”选项卡 -> 输入 https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git -> 点击“安装”
|
||||
|
||||

|
||||
|
||||
****
|
||||
|
||||
## 使用方法
|
||||
|
||||
### Tiled VAE
|
||||
|
||||

|
||||
|
||||
- 在第一次使用时,脚本会为您推荐设置。
|
||||
- 因此,通常情况下,您不需要更改默认参数。
|
||||
- 只有在以下情况下才需要更改参数:
|
||||
1. 当生成之前或之后看到CUDA内存不足错误时,请降低 tile 大小
|
||||
2. 当您使用的 tile 太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。
|
||||
|
||||
****
|
||||
|
||||
### Tiled Diffusion
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- 从图中可以看到如何将图像分割成块。
|
||||
- 在每个步骤中,潜在空间中的每个小块都将被发送到 Stable Diffusion UNet。
|
||||
- 小块一遍遍地分割和融合,直到完成所有步骤。
|
||||
- 块要多大才合适?
|
||||
- 较大的块大小将提升处理速度,因为小块数量会较少。
|
||||
- 然而,最佳大小取决于您的模型。SD1.4仅适用于绘制512 * 512图像(SD2.1是768 * 768)。由于大多数模型无法生成大于1280 * 1280的好图片。因此,在潜在空间中将其除以8后,你将得到64-160。
|
||||
- 因此,您应该选择64-160之间的值。
|
||||
- **个人建议选择96或128以获得更快的速度。**
|
||||
- 重叠要多大才合适?
|
||||
- 重叠减少了融合中的接缝。显然,较大的重叠值意味着更少接缝,但会**显著降低速度**,因为需要重新绘制更多的小块。
|
||||
- 与 MultiDiffusion 相比,Mixture of Diffusers 需要较少的重叠,因为它使用高斯平滑(因此可以更快)。
|
||||
- **个人建议使用 MultiDiffusion 时选择32或48,使用 Mixture of Diffusers 选择16或32**
|
||||
- **放大算法(Upscaler)** 选项将在图生图(img2img)模式中可用,你可选用一个合适的前置放大器。
|
||||
|
||||
****
|
||||
|
||||
### 区域提示语控制
|
||||
|
||||
ℹ 通常情况下,所有小块共享相同的主提示语。因此,您不能使用主提示语绘制有意义的对象,它会在整个图像上绘制您的对象并破坏您的图像。
|
||||
ℹ 为了处理这个问题,我们提供了强大的区域提示语控制工具。
|
||||
|
||||

|
||||
|
||||
1. 首先,启用区域提示语控制。
|
||||
- **注意:启用区域控制时,默认的小块分割功能将被禁用。**
|
||||
- 如果您的自定义区域不能填满整个画布,它将在这些未覆盖的区域中产生棕色(MultiDiffusion)或噪声(Mixture of Diffusers)。
|
||||
- 我们建议您使用自己的区域来填充整个画布,因为在生成时速度可能会更快。
|
||||
- 如果您懒得绘制,您也可以启用**绘制完整的画布背景**。但是,这将显著降低生成速度。
|
||||
2. 上传一张图片,或点击按钮**创建空白图像**作为参考。
|
||||
3. 点击区域1的启用,您将在图像中看到一个红色的矩形。
|
||||
- 在区域中**点击并拖动**鼠标以移动和调整区域大小。
|
||||
4. 选择区域类型。如果您想绘制对象,请选择前景。否则选择背景。
|
||||
- 如果选择前景,则会出现**羽化**。
|
||||
- 较大的值将为您提供更平滑的边缘。
|
||||
5. 输入区域的提示语和负面提示语。
|
||||
- **注意:您的提示将附加到页面顶部的主提示语中。**
|
||||
- 您可以利用此功能来节省你的词条,例如在页面顶部使用使用常见的提示语(如“masterpiece, best quality, highres...”)并使用“EasyNegative”之类的 embedding 。
|
||||
- **您也可以在提示语中使用 Textual Inversion 和 LoRA**
|
||||
|
||||
****
|
||||
|
||||
### 提高分辨率的特别提示
|
||||
|
||||
- **提高分辨率的推荐参数**
|
||||
- 采样器(Sampler) = Euler a,步数(steps) = 20,去噪强度(denoise) = 0.35,方法(method) = Mixture of Diffusers,潜变量块高和宽(Latent tile height & width) = 128,重叠(overlap) = 16,分块批处理规模(tile batch size)= 8(如果 CUDA 内存不足,请减小块批量大小)。
|
||||
- 支持蒙版局部重绘(mask inpaint)
|
||||
- 如果你想保留某些部分,或者 Tiled Diffusion 给出的结果很奇怪,只需对这些区域进行蒙版。
|
||||
- **所用的模型很重要**
|
||||
- MultiDiffusion 与 highres.fix 的工作方式非常相似,因此结果非常取决于你所用的模型。
|
||||
- 一个能够绘制细节的模型可以为你的图像添加惊人的细节。
|
||||
- 使用**完整的模型**而不是剪枝版(pruned)模型可以产生更好的结果。
|
||||
- **不要在主提示语中包含任何具体对象**,否则结果会很糟糕。
|
||||
- 只需使用像“highres, masterpiece, best quality, ultra-detailed 8k wallpaper, extremely clear”之类的词语。
|
||||
- 如果你喜欢,可以使用区域提示语控制来控制具体对象。
|
||||
- 不需要使用太大的块大小、过多的重叠和过多的降噪步骤,**否则速度会非常慢**。
|
||||
- **提示词相关性(CFG scale)可以显著影响细节**
|
||||
- 较大的提示词相关性(例如 14)可以提供更多的细节。
|
||||
- 你可以通过**0.1 - 0.6 的降噪强度**来控制你想要多大程度地改变原始图像.
|
||||
- 如果你的结果仍然不如我的满意,[可以在这里查看我们的讨论。](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/issues/3)
|
||||
|
||||
****
|
||||
|
||||
## 许可证
|
||||
|
||||
This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
|
||||
|
||||
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
|
||||
|
||||
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
|
||||
[cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg
|
||||
|
||||
****
|
||||
|
||||
感谢阅读!
|
||||
|
|
|
|||
Loading…
Reference in New Issue